导语:为了更好抗击此次全球疫情,IBM公司重新调整“沃森”系统(Waston),推出“沃森市民助手”(Watson Assistant for Citizens),希望能够帮助世界各地的政府机构、医学部门等及时快捷回答市民关于“COVID-19”的大量疑问。说起“沃森”,大家可能比较陌生。其实,“沃森”早在2011年就因在《危险边缘》问答竞赛中战胜人类而名扬全球!
《危险边缘》(简称,Jeopardy!)是美国著名的智力竞赛节目,该节目要求参赛者根据所提供的线索来推断出答案,并以问题的形式表述出来。过去,人们很难想象这种问答竞赛会有计算机程序充当人类选手的竞争对手,却在2011年被IBM研发的“沃森”人工智能系统夺得冠军,比赛成绩遥遥领先两名人类顶级选手。

IBM“沃森”参加《危险边缘》竞赛
有人说,IBM“沃森”是率先战胜人类国际象棋旗手的IBM“深蓝”的延续。其实这句话是不准确的,从技术的角度来说,相比于依靠暴力计算且专门针对数字游戏的“深蓝”,针对人机对话问题的“沃森”已经能够处理语音、声音甚至图像。
最为关键的一点,“沃森”能够理解并处理非结构数据。这让很多人看到了一种全新的大数据分析方式——认知计算,“沃森”将世界带到一个全新的计算时代。那么,什么是认知计算?
什么是认知计算?据著名国际数据公司IDC预测,2018 年到 2025 年之间,全球产生产生的数据量将从从 33 ZB 增长到 175 ZB,其中80%的数据都是处理非常复杂的非结构化数据。IBM的一份资料也显示,医疗数据逐年大规模增长,其中88%的医疗数据都将是非结构化数据。政府、教育、传媒业等行业的数据中,同样拥有至少80%的非结构化数据。
数据就是财富,可是目前的计算系统能够理解处理的数据还不到其中20%。这时候,能够更好处理这类非结构化数据的认知计算就显得尤为重要。

认知计算是模拟人类的方式来处理自然语言和非结构化数据。从经验中学习,并根据最佳的可用数据,帮助人类制定更有效地决策。严格意义上来说,认知计算并不是完全的人工智能系统,认知计算强调人与机器的协同。用IBM的话表述,认知计算不是制造为人思考的机器,而是与增加人类智慧有关。
相比于认知计算,人们更加熟悉人工智能。事实上,认知计算和人工智能相当于两个相交部分重叠的圆,彼此相互联系但又有区别。
认知计算强调对数据的认知和理解,而人工智能则希望机器按照人设定的规则是去行动,缺乏与人之间的相互交互。人工智能的目标是让机器能够替代人实现人的价值。而认知计算虽然借助了人工智能的技术,但最终希望让机器能够提供更加专业化的思考,为人类决策提供依据。
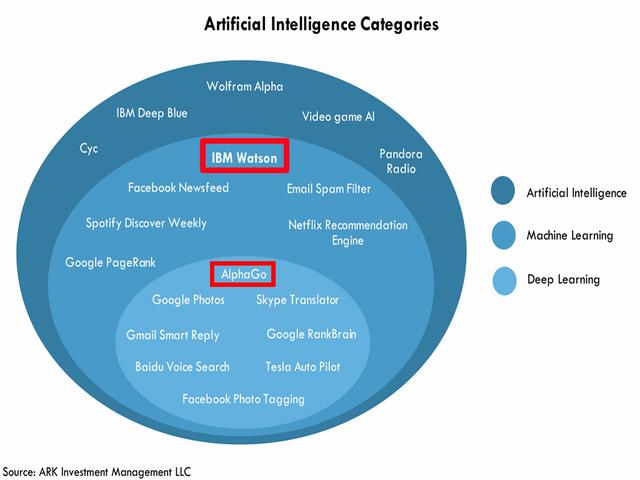
IBM“沃森”与人工智能的关系
“沃森”是认知计算的杰出代表,其本质是集成自然语言处理、信息检索、知识表达、自动推理以及机器学习的电脑问答系统,核心是基于假设认知和大规模证据收集、分析和评价的DeepQA技术。注意,这里的DeepQA与深度学习无关,“Deep”是指深度语言处理或深度回答。
DeepQA的强大在于融合了很多浅层小算法。有趣的是,后续IBM也“沃森”增加一些深度学习功能,结果发现效果并不明显。一个重要的原因是IBM并没有足够多的问答数据供“沃森”学习。例如2012年赢得图像识别大赛冠军的AlexNet使用了120万个ImageNet训练实例,但是“沃森”仅训练了25000个问题。

“沃森”训练数据的数量级
尽管不像亚马逊、谷歌这种将人工智能研发到一定程度后就会立马落实到民用级的产品,“沃森”一开始就盯着几块比较难啃的骨头:医疗、金融和营销。IBM意图通过掌握的大量企业数据为企业提供认知计算服务,从而帮助企业完成行业转型。
虽然,“沃森”在AI医疗领域动作最大发声最多,但因为“沃森”会出现“看错病开错药”的情况,导致外界对“沃森”认知计算技术产生较大的怀疑。业界虽然对过分宣传的“沃森”表示失望,但是事实上,“沃森”的问题并不是技术问题,主要原因集中在缺少真实罕见病或复发癌症的训练数据。
目前,虽然“沃森”主导的认知计算是人工智能领域中的冷门,但是“沃森”却在《危险边缘》人机竞赛中表现惊人。那么,“沃森”是如何挖掘出《危险边缘》的最佳答案?
“沃森”是如何找出《危险边缘》的最佳答案?IBM在开发“沃森”之前,已经有由4人团队花费6年开发了一个当时很不错的问答系统。但是,这个系统并不适用于《危险边缘》,于是IBM团队耗费几个月完成系统改造和实验,最终找到了一个可行的问答系统算法框架——DeepQA。DeepQA算法非常复杂,但是背后的方法很简单,也即分析问题、用搜索引擎寻找候选答案以及根据证据对答案进行评分。

“沃森”DeepQA算法框架
“沃森”的问题分析阶段通过自然语言处理算法(NLP),实现将一个问题分解成多个信息片段,找到线索中单词的词性、人名、地名等,从而构建线索的句型图。对于其中一些信息,比如以1或者2开头的4位数字列,我们可以很容易让“沃森”搜索日期。对其他比较复杂的信息,“沃森”则需要通过“句法分析”生成的句型图来理解。
例如英语中,动词短语可以拆解为副词和动词短语,名词短语可以拆解为形容词和名词。按照这些规则,就可以将一个句子拆解为单一词性的小块。但是,一个语句中由于单词不同的词性很有可能有多种拆解方法,计算机无法确定哪一个句型图是正确,为此需要通过单词和词性之间的统计关系来确定最有可能的句型图。
句型图的用处之一就是找到线索语句的重点,从而能够准确抓住要问的东西的词组。比如这个人或这种症状,或者表示关联的“或、并、非”关键词等。当“沃森”完成寻找重点的标记任务后,就需要为线索寻找答案。你可能会认为是查询字典、数据库甚至是维基百科,但是“沃森”使用的方法和人类截然不同。

句型图拆解句子示意图
人需要答案一般采取的方式在最合适的信息来源中寻找,如果没有就会寻找第二个信息来源,类似于纵向搜索。并且,我们寻找的答案很可能是来自单一信息来源。但是“沃森”的目标不是选择正确答案,而是搜索可能的候选答案,类似于横向搜索。为了防止正确答案不在候选答案中,“沃森”筛选的标准很低。
“沃森”查找的候选答案来源于庞大的非结构化数据,包括百科全书、报纸、维基百科界面、字典等。由于比赛过程中不能联网,因此研究人搜集了“沃森”的所有文档,并将它加载到自定义的搜索引擎中。这样,“沃森”就能将问题发现阶段的重点信息作为查询发送到搜索引擎,这样就能在搜索结果中创建更多的候选答案。最终,只需要将搜索结果的标题就可以当做候选答案。
这里,“沃森”使用了一个小技巧。研究人员发现,《危险边缘》节目中竟然有多达95%的答案是维基百科页面的标题。这样,研究人员就将维基百科作为“沃森”生成候选答案阶段的基石。通常情况下,“沃森”生成的候选答案有几百个。为此它需要对每个候选答案进行深度分析,从而找到正确答案。

“沃森”首先使用轻量级过滤器来缩小候选答案范围。比如线索答案的类型是人,则只需要将候选答案缩小到人名范围。所有通过轻量级筛选的候选答案都将进入证据搜索阶段,也就是重新接着数据库和搜索引擎,进一步对每一个候选答案与线索之间的匹配度进行打分,也就是关键词是否出现出现在候选答案页面中的内容,比如奥运会、2008年、5000米等。
“沃森”采用了许多简单的评分器来评估证据,包括加权统计重叠单词、寻找是否对齐、性别评分器、日期一致等100个多评分器。这些评分器的制定则是靠背后团队针对评价方式的缺陷,将研发人员的经验编码成评分器,如果有真有改进作用,则将这种评分器添加到“沃森”。

最后,“沃森”在生成最终答案之前,使用7个独立的变换序列分类器,实现重复答案合并、格式变换以及“汇总不同分类器过滤候选答案”等操作,最终取得分最高的候选答案作为最佳答案。
由此可见,虽然“沃森”采用了与深度学习相关的迁移学习 (Transfer Learning)来解决不常见问题样本较少的问题,但这与AlphaGo不同,它不是一个完全采用深度学习技术的人工智能系统,而是一个融合自然语言处理、认知科学、逻辑回归分类等机器学习系统。
“沃森”真的有智能吗?认知计算又将如何发展?看完“沃森”整个寻找准确答案的过程,大家有没有想过“沃森”有何不同之处?其实,“沃森”与先前的问答系统最大的不同就是其庞大的规模和对DeepQA的使用。那么,“沃森”具备回答《危险边缘》问题的能力,是否意味着“沃森”拥有智能?

我认为“沃森”的智能程度并不像IBM宣传的那样高。
从根据线索寻找正确答案的过程来看,“沃森”并不能真正理解线索到底要问什么。“沃森”答题过程只是遵循一系列确定的步骤,用人工设计的规则和从数据中学到的权重来搜索验证问题,并对获取的证据进行评分。
IBM宣传“沃森”的评分器为推理算法,这是比较牵强的说法,因为其中一些评分器只做统计单词等类似的事情。而且,即使“沃森”在《危险边缘》中表现非常出色,但是“沃森”的初级版本也只是为了这一具体任何而设计。因此,如果“沃森”不做改进,它是做不了其他事情的。在这里点上,很多人工智能深度学习算法也有同样的问题。
但是,“沃森”并不是一点智能也没有。“沃森”在比赛过程中,还做出了很多与理解自然语音无关的决策,包括何时下注、是否抢答、下注多少。“沃森”要想做出准确的决策,必须评估正确回答的可能性和给多少赌注是否会增加获胜几率。为此,“沃森”采用采用历史数据来评估答案的置信度,并通过一个复杂的回归模型描述游戏的状态信息(例如,三方得分)来评估任何游戏阶段“沃森”获胜的概率。
相对于“沃森”的高级数学评估模型,人充其量只能对这些数字量做出粗略的估计。

IBM“沃森”应用推广
现如今,IBM已经将“沃森”推广到其他各种应用当中,但是这些系统应该和最初的“沃森”的实现方式有很大不同。虽然,“沃森”在其他领域表现并不理想,但是“沃森”首次引起轰动的时候,IBM还是选择将“沃森”的工作原理公之于众,而且这项研究也已经被主流自然语言处理学界所接受。
未来,以“沃森”为代表的认知计算将如何发展?
所有的技术革命都是由商业和社会需求而推动起来的,追求技术的革新不是为了证明我们有能力,而是我们有需求。
目前看得见、短期能创造巨大收益的深度学习深受大家的追捧。但认知计算却并没有产生巨大社会影响力,原因在于认知计算的技术体系还并不完善,从而导致基于认知计算的商业产品并没有真正解决实际场景的需求。
随着大规模非结构数据的不断增长,社会对更加智能的机器的需求越来越大,人们希望能够移动终端接入到这些更加智能的服务的渴望程度也越来越强。认知计算要想突破,核心还是在技术的发展,而且这种发展要能够跟上信息数据爆发的速度。

未来,自然语言处理、神经形态计算机、无人监督的机器学习算法和虚拟现实等技术的进一步发展,将会进一步提高认知系统处理决策的可靠性。另一方面,认知计算在各个领域的广泛运用需要相应政策同步跟进,包括数据共享、数据安全和隐私等。
认知计算的价值主张极具诱惑力,而且许多领先机构已经实现了依托认知计算的价值经济。但是,认知计算需要良好的管理,并且具备更好解决现实问题的能力。否则,大量不同观点的差异和错误信息可能带来另一次“寒冬”。
结论本文从攻克《危险边缘》问答竞赛的IBM“沃森”出发,引出对“沃森”背后的认知计算的探讨。不同于替代人去实现人的价值的人工智能,认知计算虽然也采用一些人工智能的技术,但目标更强调为人提供辅助决策、帮助人提高智能。
尽管目前认知计算并没有广泛被接受,但是“沃森”在《危险边缘》的表现的确是具有划时代意义。因为认知计算完成了过去只有人能够完成的事。
为了进一步说明“沃森”如何在《危险边缘》中寻找最佳答案,本文从“分析问题”、“寻找候选答案”、“评估答案”三个方面,详细解读“沃森”的技术细节。从而说明,“沃森”与AlphaGo不同,不是一个完全采用深度学习技术的人工智能系统,而是一个机器学习系统。
“沃森”并不能说是完全智能,因为在寻找答案的过程中,“沃森”并不能真正理解线索的意思。但这并不意味着“沃森”没有智能,因为“沃森”解决了很多非自然语音处理的决策问题。
认知计算的确很美妙,但是要想真正能够影响我们的社会,技术还需要不断跟上非结构性数据爆发的速度,否则到最后也只是“一场空”。
如果您觉得本文对您有价值,
欢迎大家关注静心科技,静心科技为您提供不一样的静心视角。
如果您有不同的看法,
欢迎在下方留言板留下您的意见建议。
图片来源:网络,如果侵权,请联系删除!
文:静心科技,科技研发工作者,荣获十几篇头条科技领域青云文章。
,




