
作者:liufan
Nature Genetics杂志曾发表了一项基于Structure(被引用接近20000次的牛文)开发的一种可以用于扫描大量的遗传数据集新的机器学习算法—TeraStructure,引起了不少学者的关注。该工具可以用于推断个人祖先的遗传组成,识别疾病相关的遗传突变。那么Structure又是何物呢?
Structure是由斯坦福大学Pritchard实验室开发的一款群体结构分析软件,通过该软件,我们直观了解个体间的分类关系—即可以将某个群体分为若干亚群、群体间是否存在基因交流以及每个个体混血程度是多少。

*图片引自Ryck等
Structure中群体的亚群数被称为K值。上图中分别列出了K=2和7时的结果。图中每一种颜色代表一个类群,每个个体代表图中的一个小柱状堆叠图,那么我们可以看出有些个体血统较为纯正,有些则出现了混杂。通过颜色我们便可以对种群中的个体进行不同亚群的划分。
。
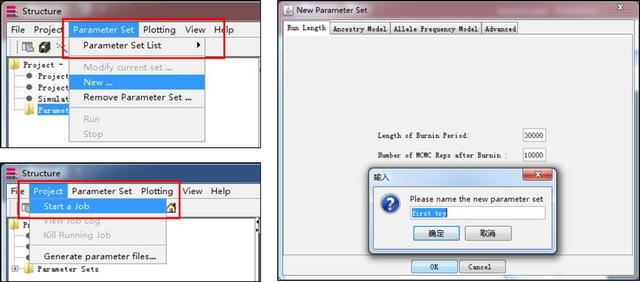
这里笔者会给出一个示例数据,万事俱备,打开软件,点击建立“new project”,输入项目的信息(注意这里数据文件要和select directory在一个文件夹中),点击输入个体信息、位点信息、缺失值等信息,完成数据读入。如果数据无误那么软件会显示输入的数据,有误则会报错。



数据导入完毕后就可以设置参数了,点击parameter下的new进行参数设置,length of burn-in period需要设置较大的数,这里设置为100000,保存为first try。接下来我们需要点击project下的start a job开始任务。
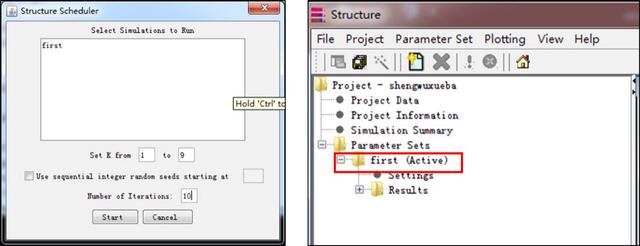
这里设置K为1~9,重复次数为10次,可以看到点击start job后,project处于激活状态,软件此时已经开始运行。
运行完毕后,会得到一个result文件夹,里面包含有90次运行的结果,那么由于之前K取了1~9,哪一个K值是最佳的呢,这里采用Evanno等人的方法进行分析计算。在线分析的网址为http://taylor0.biology.ucla.edu/struct_harvest/ 。将result文件夹压缩上传即可一键分析。从而得出最佳的K值,最后将结果文件下载保存即可。

参考文献:
[1]Pritchard, J. K., Stephens, M., & Donnelly, P. (2000). Inference of population structure using multilocus genotype data. Genetics, 155(2), 945-959.
[2]Gopalan, P., Wei, H., Blei, D. M., & Storey, J. D. (2016). Scaling probabilistic models of genetic variation to millions of humans. Nature Genetics.
[3]Ryck, D. J. D., Koedam, N., Stocken, T. V. D., Ven, R. M. V. D., Adams, J., & Triest, L. (2016). Dispersal limitation of the mangrove avicennia marina at its south african range limit in strong contrast to connectivity in its core east african region. Marine Ecology Progress, 545, 123-134.
[4]Evanno G, Regnaut S, Goudet J. Detecting thenumber of clusters of individuals using the software STRUCTURE: a simulationstudy[J]. Molecular ecology, 2005, 14(8): 2611-2620.

欢迎投稿
tougao@helixlife.com.cn
合作helixlife6
,




