逻辑回归模型是金融信贷行业制作各类评分卡模型的核心,几乎80%的机器学习/统计学习模型算法都是逻辑回归模型,按照逻辑美国金融公司总结的SAS建模过程,大致总结如下:

建模流程
一般通用模型训练过程:
1, 数据下载
a) 按照指定需求和模型要求制作driver数据集,包含字段有user_id, dep
b) 其中,空值赋默认值即:coalesce(column, default_value)
c) 从800个变量中下载过去6个月的连续数据,每张表转化为宽表下载
2, 计算变量的IV值
a) 将excel数据集转化为SAS数据集
b) 单月份的数据如:年龄、性别等可直接使用单月的值做IV计算
c) 对于6个月的数据如:每月的消费金额、消费次数等需要先做VH变换(目前VH变换的方法有36种),然后将V1-V6以及36种变换一起合起来做IV计算。
d) 按照所有变量的IV值排序,选择IV阈值(申请行为评分的IV阈值为0.02;响应模型的IV阈值为0.1),将大于阈值的字段从VH变换后的表中抽出,合并生产后续数据集(大约剩余变量个数为500~3000个)
3, 变量再选择
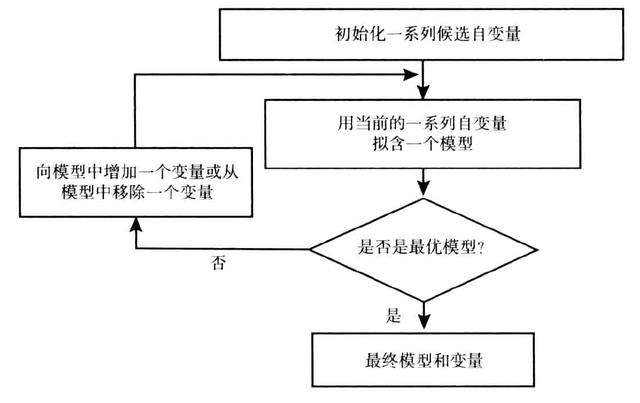
a) 使用逐步判别分析(stepdisc)是先从所有因子中挑选一个具有最显著判别能力的因子,然后再挑选第二个因子,这个因子是在第一因子的基础上具有最显著判别能力的因子,即第一个和第二个因子联合起来有显著判别能力的因子;接着挑选第三个因子,这因子是在第一、第二因子的基础上具有最显著判别能力的因子。由于因子之间的相互关系,当引进了新的因子之后,会使原来已引入的因子失去显著判别能力。因此,在引入第三个因子之后就要先检验一下各已经引入的因子是否还具有显著判别能力,如果有就要剔除这个不显著的因子;接着再继续引入,直到再没有显著能力的因子可剔除为止。用这样挑选出来的因子建立的判别函数进行判别,就能得到较高的判别准确率。通过向前选入、向后剔除或逐步选择对判别有用的定量变量来完成逐步判别分析。生产文件stepdisc_all.xls里面会将选择结果的变量保留下来(大约剩余变量个数为100~300个)
b) 使用逐步回归方法(stepwise)是将变量逐个引入模型,每引入一个解释变量后都要进行F检验,并对已经选入的解释变量逐个进行t检验,当原来引入的解释变量由于后面解释变量的引入变得不再显著时,则将其删除。以确保每次引入新的变量之前回归方程中只包含显著性变量。这是一个反复的过程,直到既没有显著的解释变量选入回归方程,也没有不显著的解释变量从回归方程中剔除为止。以保证最后所得到的解释变量集是最优的。通过此步骤会生成logistic_step_v3.1.xls的文件,在文件末尾地方可以看到精选出来的变量(大约变量个数为15~30个)
4, 进行模型报告打印

模型报告目录
a) 将数据集随机分为训练和测试2个数据集,分别在每一行的结尾添加字段flag=’dev’和flag=’oot’
b) 对变量进行模型报告的打印:训练精选变量的模型,然后用测试数据集进行验证,打印模型的PSI、bivar、ks等评价指标的结果
c) 在结果中,查看P1. Final Model中的CONSISTENT值为FALSE的变量,以及ProbChiSq值较大的变量建议去掉;查看P2.CoLin中的Pearson 相关系数表,去掉相关系数大于0.4的变量;查看P4. KS Gain中的KS值;查看7.Bivar_After_Treatment中的数据,使用
bivar_dev.xls使用快捷键ctrl W可以生成Bivar Plot图表,将其表导入模型报告。根据以上调整去掉一些无效变量,根据Bivar Plot图表进行treatment变换,再次重复进行模型报告的打印
5, 模型变量说明和解释
a) 根据最终选取变量,以及变量变换的方法,将变量说明文档完善
b) 根据变量系数、变量逻辑和dep进行逻辑性验证,去掉不合逻辑、关联性不强的变量,再次使用模型打印报告保证总体的ks下降不大
6, 模型阈值和策略的调整
a) 根据模型报告的P4. KS Gain中的结果制定Min Score作为阈值进行模型预测
end ...
==
针对这一过程,后续会推出专门的文章进行详细说明,欢迎大家订阅咨询。
,




