编辑导语:聚类分析是对样本或指标进行分类的一种统计方法,它能帮助我们窥探不同人群之间的数据差异,也被应用于基于定量数据的用户分类实践中。本文作者结合某金融借贷服务流程再设计中的用户分类案例,阐述了聚类分析在用户画像中的应用,一起来看一下吧。
聚类分析(Cluster analysis)是对样本或指标进行分类的一种统计方法,属于探索性的数据分析方法。
聚类分析将看似无序的对象(如桌子、人、树木、情绪、观念等)进行分组、归类,按照个体或样本的特征将其分类,使得同一类别下的个体具有尽可能高的同质性,而不同类别/组别之间则是尽可能高的异质性,以更好地理解研究对象。
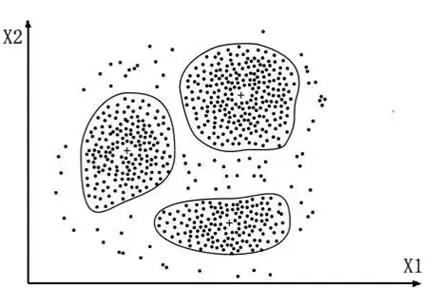
物以类聚,人以群分。借助聚类分析算法,可以帮助我们窥探不同人群之间的数据差异(如图1)。因此,此种方法也被应用于基于定量数据的用户分类实践中。
图1:二维(2个变量 )下的聚类分析示意图
然而,由于聚类分析所使用的数据并没有明确的分类,聚类分析后的类别数量也是未知的。
即:我们不知道用来聚类分析的样本大概有什么分布,也不了解系统会将其分成哪几类,事先可能也没有任何有关类别信息供参考。
因此聚类分析更像是一种建立假设的方法,而对相关假设的检验还需要借助其它统计方法,在用户画像的生成过程中,建议将聚类分析当做一种探索分类结构、提供数据支撑的手段,而非(也不可能)完全依赖于聚类分析来形成最终用户分类结论。
以下结合某金融借贷服务流程再设计中的用户分类案例,来具体阐述聚类分析在用户画像中的应用。
01 聚类分析适用的数据类型聚类分析所应用的数据类型主要为多维度、连续/等级/分类变量,且要求数据量足够大、客观可测量,因此,较为适合应用于研究者已拥有海量、多维度用户客观数据的情况。
数据来源如:已经运营一段时间的产品后台数据、电商浏览购买行为数据、客户CRM数据、微信公众号后台数据等。
基于这些数据,我们可以以用户实际产生的行为数据(如:点击次数、转发次数、使用频率等)、人口学资料数据等客观数据将用户分成数类。正因此,聚类分析被广泛应用于消费者行为研究、细分市场研究、电子商务运营策略研究等关注人群、市场和消费行为的研究项目中。
聚类分析介入用户分类的程序:在用户研究工作中,用户分类可以基于定性或定量数据来进行,但最终会收敛为一个具体、明确、符合经验的分类模型,使之能够服务于未来的产品设计与运营。如图2:
图2:2019微众银行用户调研之人群画像
仅依靠数据无法帮助我们定义和解释不同类别下的样本轮廓,也无法将统计结果直接运用于生产设计和运营活动中。
因此聚类分析的方法应当结合前后期的定性研究(如产品走查、用户访谈、内部访谈、观察、工作坊等)和定量研究(问卷调查、拦访调研、接受度测试等)而进行。在本案例中,研究者采取了先定性,后聚类,再补充定量的方式,来形成和运用聚类分析的结果,如图3:
图3:金融借贷服务流程再设计-用户画像创建流程
再者,从机器学习角度上来说,聚类分析是一种无监督学习unsupervised learning,根据不同的数据选取策略和不同的聚类算法,系统会给出不同的分类模型。
至于哪个模型是贴合研究实际的“最优解”,需要研究者自行决定。这意味着在做用户分类时,我们所依赖的工具需要在研究者所提供的浩如烟海的数据当中根据数据的分布形态,逐渐探索出数据的分类形态,因此最终数据分类的结果质量对研究者对数据的理解、把握和解读有着更高的要求。
这要求研究者在使用数据进行聚类之前,应当对数据的业务内涵具有相当程度的把握和敏感性。
02 聚类分析用于用户分类的操作流程1)样本数据选择
根据前期的定性研究和已经生成的假设,选择能够用来描述和定义用户的数据维度。在本案例中,通过定性访谈、内部访谈等研究,研究者已经得知,不同用户在借贷周期、借贷金额、还款履约行为、犹豫周期上存在着很大差别,因此,研究者可以有目的地选择可能有用的数据。可以列出所需维度的数据清单,向数据负责人获取。
在选择数据时,也可以查阅相关文献,如行业竞品常用的数据/参数模型,建立对研究所需数据标签的感知。图4为本案例在选择样本数据时参考的某银行产品用户标签体系。
图4:某银行金融产品用户标签体系
2)样本数据清洗
这一步骤的目的在于去除缺省值、异常值、不合理值、非研究范畴值,研究者可以根据项目的实际需求,去除可能成为干扰项的数据。如:对收入进行标准化处理,剔除3个标准差外的异常值,去除超越研究范畴(如60周岁以上)的样本。
注意保存清洗逻辑并在团队成员间共享,以便随时恢复被误删除的数据。
3)数据编码及标准化
涉及到数据类型的转换和数据可读性的调整,由于聚类分析需要用到一定规模的连续变量和分类变量,对于一些界定模糊的变量,需要团队成员商议后给予其明确的数据类型定义,并给出相应的定义值。此外,注意保存这些编码逻辑,业务数据往往夹杂着诸多术语和缩写,研究员需将其转为易读的符号并加以记忆。
如图5,本案例中,申请类型、进件渠道、还款方式属于分类变量,B卡评分描述了用户的信用程度,则可以定义为等级变量或连续变量。
图5:金融借贷服务流程再设计-原始数据编码逻辑片段
此外,为了顺利进行聚类分析算法的运转,需将不一致的数据单位调整为一致的、标准的计量单位,如:将“利率”统一转化为“月利率”或“年利率”。
4)变量处理与提取特征
这一步骤目的在于使冗余的数据得到凝缩和降维。
原始变量可能会有几百上千的维度,但最终用于聚类分析的变量需要能够很好地描摹用户行为,有时研究者需要对数据进行一些简单加工,得到一些更为关键的变量。如:研究者可以用最终办理进件时间减去首次用户问询时间,得出中间的差值,该变量(犹豫时长)可以用来形容用户在金融借贷产品中的消费风格。
此外,聚类分析算法要求变量与变量之间具有较强的独立性,因此,需要研究者尽可能地整合相关性较大的变量,更严谨的做法则可以借助关联规则分析发现并排除高度相关的特征,或通过主成分分析进行降维。
5)选择聚类分析算法
在 SPSS统计分析软件中,常用的聚类分析算法包含二阶聚类 twostep、K-均值聚类 K-means、系统/层次聚类 Hierarchical。不同聚类分析的算法逻辑不同(本文不再赘述)所需要用到的变量类型也有所不同,适用的样本群体也略有差异。研究者可根据项目的实际需要来选择相应的算法。如图6:
图6:根据项目实际需要选择相应算法
本案例中,研究者选择了二阶聚类算法,这种算法无需人为设定最终分类个数,有助于实现对人群样本聚类的探索。
6)选择变量进行聚类——检验模型效果
这一步骤是漫长的探索过程,需要研究者不断尝试,选择适量的变量进行聚类分析运算,并检视模型质量和前期研究的适配度。研究者往往需要尝试几十、几百次的更换变量、修改参数,才能得到一个聚类质量较高、模型解释力强的分类模型。
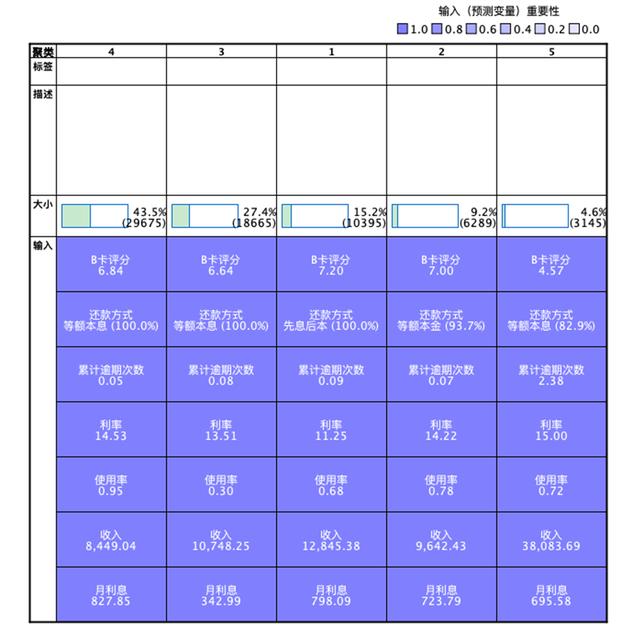
本案例中,研究者选择了B卡评分、还款方式、累计逾期次数、利率、使用率(用款金额占授信额度的占比)、收入、月利息共7个变量,包含连续变量和分类变量,最终得到图7的聚类模型。研究者可以在“模型摘要图”打开模型浏览器,看到聚类质量、聚类大小等图表形式结果(图8)。
图7:模型摘要图
图8:聚类质量、聚类大小图表
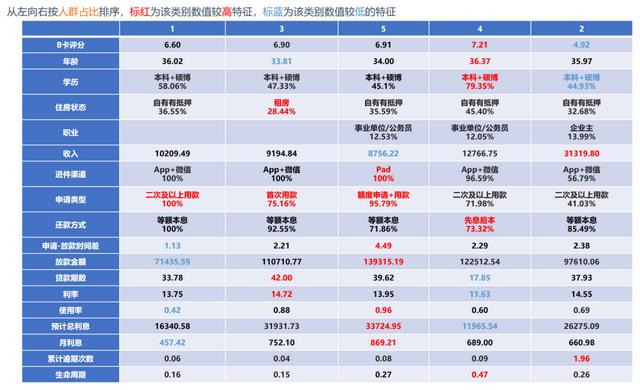
03 聚类分析结果应用得到聚类分析的模型结果,通过模型中呈现的不同变量(含用于聚类分析的变量,和用于描述各分类的其他变量)的数值及分布,可以描述出不同类别用户的特征,而每一类用户会有个别较为突出的显著特征,如图9:
图9:某银行金融产品用户标签体系
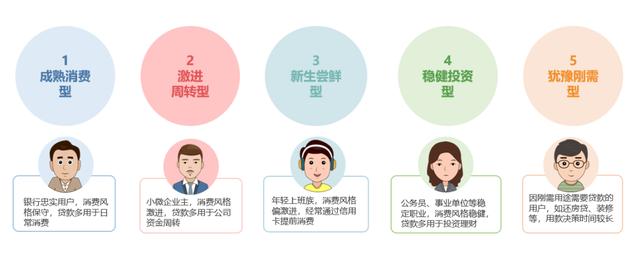
通过提取不同类别用户的关键特征,结合聚类分析前所获得的定性调研结果及经验,研究者与行方共同探讨定义出了这5类用户的内涵与外延。如图10:
图10:用户的内涵与外延
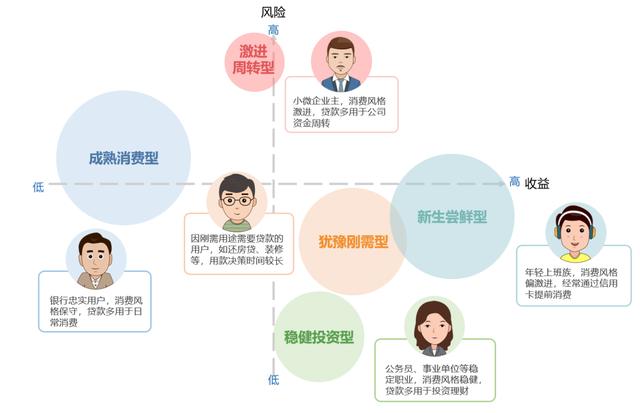
为了便于业务理解和应用,进一步加工该分类,将这五类用户放在“风险-收益”两个独立维度中进行描述,如图11:
图11:用户进一步分类
如此,业务方得以了解各类用户对于银行借贷金融业务的价值与风险、期待与需求,基于此描述,我们可以进一步制定针对不同用户的营销和服务策略。
值得注意的是,对最终与研究假设/直觉拟合度较高的模型,最终需要结合已知的定性研究结果和业务相关人员共同阐释,方可使机械的模型具备生态效力和业务解释力。
得出用户分类的基础画像后,可以再次使用访谈、工作坊、定量问卷等方式加以补充描述,本文不再赘述。
作者:何龙荃,ISAR公司资深用研
来源公众号:伊飒尔UXD学院,专注用户研究和用户体验设计
本文由人人都是产品经理合作媒体 @伊飒尔UXD 授权发布,未经许可,禁止转载。
题图来自 Unsplash,基于 CC0 协议。
,