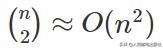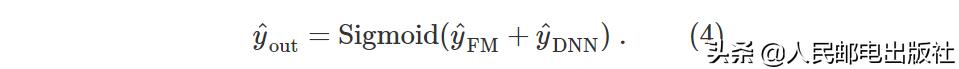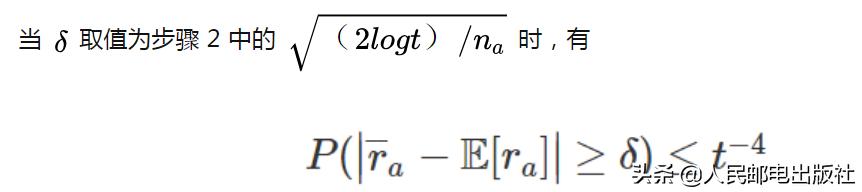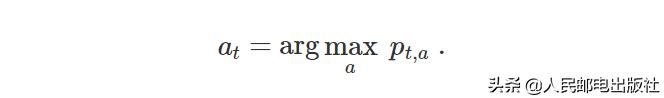本文来源于Hulu,文章《<百面深度学习>试读 | 系列五:计算广告中的点击率预估问题》,葫芦娃著。
计算广告是互联网行业内发展比较成熟的领域,其中的业务比较复杂,需要解决的问题也很多。该领域中一些适合用智能算法来解决的问题,大部分在深度学习出现之前就已经有了解决方案;但深度学习出现后,其中有一部分问题在应用深度学习技术后能够进一步提升效率。
由于不同公司面临的业务场景有各自的特色,比如横幅广告、Google 的搜索广告以及 Hulu 的视频广告等等。这使得计算广告领域内的具体问题一般会带有各自公司业务的特点,各不相同。
在计算广告领域,点击率预测是大家熟知、也是最为重要的问题之一,本文将从点击率预估问题入手,概述点击率预估的常用模型、用户的兴趣建模以及如何使用多臂老虎机算法解决冷启动问题。在最后的总结中,尝试描述计算广告领域处理和看待问题的方式。
点击率预估问题概述计算广告领域有一大类广告的定价模式是按点击收费:用户如果点击了广告,广告主支付一定的费用;用户如果没有点击,则广告主不用支付费用。按点击计费是一种主流的广告模式,在这种广告模式中,用户点击广告的概率直接关系到广告的收入,因此点击率(Click-Through Rate, CTR)预估是其中的一个核心问题。 CTR 是指在广告展示中用户点击广告的概率。预测 CTR 对搜索、广告和推荐系统都有着重要作用 [1] [2]。
在细分流量上,点击率预估的输入信息主要包括三类:(1) 广告信息;(2) 用户信息;(3) 场景信息。我们尝试建立模型根据这三类信息推荐出与上下文和用户都相关的广告。场景信息的存在也对模型的实时性提出了要求,同一个用户在不同场景下优先关注的广告可能是不同的。例如如果用户的来源网址是一个汽车网站,那么用户对汽车类广告的兴趣可能比较高;如果用户的来源网站是旅游类网站,那么用户对旅行广告的关注程度可能会更高。
实时性的要求意味着点击率预估模型需要在线上实时估计用户的点击率并推送合适的广告。如果用户的并发请求较多,可能需要采用一些模型或者架构上的改动来适应实时性的需求。比如经典的 YouTube 推荐系统架构就由两部分组成:首先是召回模型,负责从海量的候选集中筛选出少量的备选集(在 YouTube 的场景下是几百个);其次是排序模型,根据召回模型的输出备选集,预测出每一个元素的点击率,用于最终的排序与推荐。
点击率预估主要模型尝试解决 CTR 问题的机器学习模型非常多,虽然有很多变型,但是大多基于几个基本的模型框架。这些框架包括逻辑回归、因子分解机、梯度提升树、引入深度神经网络的机器学习模型等等。
逻辑回归(Logistic Regression, LR)仍然是一个可以考虑的模型,因为其结构简单,可解释性强,现在仍然会被作为系统早期的模型备选方案之一。LR 的表达性可以由特征工程来扩展,工程师可以通过添加数值变量的平方、平方根等变形,以及交叉特征来扩展样本的表示,人工完成其他复杂模型的任务。这样做也有一些缺点,首先是这增加了工作量,其次是这个方法会导致输入特征的维数特别高,可能导致过拟合,需要增加一些正则化等方式来防止过拟合。
因子分解机(Factorization Machines, FM)模型为 CTR 预估中特征交叉问题提供了一个解决方案。 比如对于口红类商品的广告,可能对年龄在 16 岁以上且性别为女的用户更加合适,这就意味着预测口红广告的 CTR 需要用户年龄和用户性别的二阶交叉特征。由于 CTR 特征的高维稀疏性特点,特征交叉将增加问题的难度。对于一个 n 维特征输入,二阶特征交叉就意味着
量级的交叉特征,这大大增加了模型的计算量,难以进行实际应用。
应用逻辑回归等线性模型来预测 CTR 会遇到如下问题:一些起重要作用的交叉特征无法被线性模型表达,需要人工加入这些交叉特征来扩展输入,这会导致算法的可扩展性不强。另外一些方法如二阶多项式(Degree-2 Polynomial)模型会枚举所有二阶交叉特征并在此基础上应用机器学习算法进行学习,这种枚举方式模拟了线性模型中针对二阶交叉特征的特征筛选工作,但它会大大增加输入特征的维度。
此外,在实际的训练过程中,有些交叉特征在样本中出现的次数比较少,这会导致交叉项在模型中的权重参数无法得到充分训练。具体来说,FM 模型可以表示为特征的一阶交叉项与二阶交叉项之和:
FM 模型通过给每维特征学习一个低维嵌入向量,然后用嵌入向量的内积来表示交叉系数,这样可以降低模型的参数个数,使得模型学习交叉特征变得可行,最终增加模型的实用性。
将每维特征对应到一个嵌入向量上还会带来一个优点:只要训练集中该特征的非零取值次数足够多,对应的嵌入向量就能得到充分训练,这样就能通过嵌入向量的内积计算出交叉特征的系数,而并不要求交叉项在训练集中出现很多次。
在实际 CTR 预估问题中,不同特征域之间的交叉特征的影响是不同的。比如,用户性别与年龄的交叉特征对 CTR 的影响可能比较大,而性别与在线时长的交叉特征却往往没有太大意义。在 FM 模型中,
,这样就无法表现出不同特征域之间交叉特征的重要性变化。针对这个问题,域感知因子分解机(Field-aware Factorization Machines, FFM)[3] 模型提出了改进措施,为每维特征学习针对不同特征域(feature field)的不同嵌入向量,以刻画不同特征域之间的特征交叉的区别,具体公式如下:
无论是 FM、FFM 还是 FwFM 模型,都只建模了二阶特征交叉,然而实际应用场景中更高阶特征交叉对 CTR 预估也很重要。深度学习模型由于引入了隐层与非线性变换,可以用来建模高阶特征交叉,如乘积神经网络(Product-based Neural Networks, PNN)、深度因子分解机(DeepFM)、深度兴趣网络(DIN)等。
深度因子分解机(DeepFM)[5] 在 FM 的基础上,添加了深度神经网络作为 "Deep" 部分,让模型能够学习高阶特征交叉。Fig. 1 展示了 DeepFM 的结构示意图,整个模型可以分为 FM 部分和 Deep 部分,具体细节如下:
- 类似于 FM,DeepFM 模型的输入是每个特征的稀疏编码。随后,DeepFM 为每个特征学习一个稠密的低维嵌入向量,并将这些嵌入向量作为后续的 FM 部分和 Deep 部分的输入。
- 在 FM 部分,模型会产生一阶特征交叉项 ⟨ ⟩ 和二阶特征交叉项 ⟨ ⟩ (参考 Eq. 1)。FM 部分的输出记作 。
- 在 Deep 部分,模型采用多层全连接神经网络来学习高阶特征交叉信息。Deep 部分采用特征的嵌入向量作为输入(而不是特征的稀疏编码),是因为不同于图像、语音等领域,CTR 预估问题中的输入特征通常是高维稀疏向量(大部分是类别型特征),直接作为神经网络的输入不能取得很好的效果。Deep 部分的输出记作 。
- 模型最终的输出是 FM 部分和 Deep 部分的输出之和(再经过一个 Sigmoid 变换):
整体来说,DeepFM 模型通过 FM 部分直接保留了低阶特征交叉项(一阶和二阶),通过 Deep 部分学习更高阶的特征交叉信息,从而提高 CTR 预估的效果。此外,FM 部分与 Deep 部分共享特征的嵌入向量,这可以减轻特征的计算量,并且在训练过程中能使嵌入向量同时学习到低阶和高阶的特征交叉信息,从而获得更有效的特征表示。
Figure 1: DeepFM 模型结构图
点击率兴趣建模
在 CTR 预估问题中,无论用户点击的广告是线上商城的商品,还是电影、电视剧等视频资源,用户表现的兴趣往往都是多样化的。例如,同一个用户可能既喜欢看恐怖片,也喜欢看喜剧片。然而,大多数处理 CTR 预估问题的机器学习方法都只建模用户的单峰兴趣特性,即将用户数据中的特征通过一些变换组合成一个固定长度的向量,这无法很好地表现用户兴趣的多样性。
阿里巴巴公司在 2018 年发表的深度兴趣网络(DIN)[6],在预测用户对于特定广告的 CTR 时,可以只关心与该广告相关的用户历史行为(也即能影响到用户决策的那部分特征),从而提升预测效果。具体来说,针对不同的广告,DIN 会对用户历史行为产生不同的注意力向量,并据此对用户历史行为做变换,最终生成与目标广告相关的用户特征编码。这里之所以使用注意力机制,是因为用户在选择点击某个感兴趣的广告时,往往只是有一部分历史行为信息与当前的决策相关。
Fig. 2 是 DIN 的结构示意图。从图中可以看到,DIN 先对用户的每一个历史行为进行编码,然后通过局部注意力模块计算出这些历史行为的注意力权重向量,最后将注意力权重与历史行为编码向量相乘,做加权求和后即获得用户的特征编码;用户特征与其他特征以及广告特征拼接在一起,输入到多层神经网络中,最终得到 CTR 预测值。这里通过注意力机制产生的用户特征编码的公式如下:
Fig. 3 是 DIN 中的局部注意力模块的结构示意图。由图可知,除了用户历史行为记录和目标广告的编码向量作为输入之外,局部注意力模块还计算了这两个向量的外积,作为计算用户历史行为和目标广告相关性的显式特征。另外值得注意的是,在局部注意力模块中,并没有对注意力权重向量进行 Softmax 归一化,这是为了保留用户兴趣的强度信息,方便使用强度信息比较用户的不同兴趣与目标广告的相关性。
Figure 2: 深度兴趣网络(DIN)的结构示意图
Figure 3: 深度兴趣网络(DIN)中的局部注意力模块的结构示意图
点击率预估中的样本偏差问题在点击率预估问题中,正样本(有点击行为的样本)往往只占总样本的很小一部分,这会给预测正样本带来很大挑战。首先由于正负样本比例的不同,大多数分类器都会更偏向于给出偏向负样本的预测结果。工程上这个问题往往采用负样本降采样或者正样本重采样的技术来解决。
基于类似的原理,广告的点击率也会由于位置的不同而不同,带来模型对相关性估计的偏差。举例来说,对于同一个页面上的静态广告,排列在首位显眼位置的广告显然比排列在尾部的不起眼位置的广告有更高的点击率,这个是和广告内容不太相关的。
常见的位置偏差包括广告位置、广告尺寸、创意尺寸、日期、时间等等。工程上一般采用期望点击的方法来降低位置偏差对广告点击率估计的影响。估计情景偏差的模型叫做偏差模型(bias model),这个模型表示的是在同一个位置随机放置广告所带来的点击率估计值。
点击率预估中的冷启动问题在广告投放排序过程中,预测的 CTR 是非常重要一项指标。例如,一般效果广告会按 CTR×CPC(cost per click)来进行排序。在 CTR 预估问题中,广告的展示和点击数据是十分重要的一个输入。
对于新广告而言,在刚刚开始投放时,并没有积累太多的展示数据和足够的点击数据进行准确地 CTR 预估。同样,对于长尾广告,由于没有足够的展示机会,因而也缺乏足够的展示和点击数据。在这种情况下,如何把新广告投给感兴趣的用户,这称为广告冷启动问题。冷启动在推荐系统中也是非常重要的一个课题。
多臂老虎机算法是解决冷启动的一种常见方法,它是强化学习的一个简化版本。多臂老虎机问题起源于古老的赌博游戏:假设一个老虎机有多个臂,每摇一次臂需要花费一个金币,每个臂的收益概率是不一样的且未知的(但这个概率是固定的);一个赌徒有一定数目的金币,他如何操作可以得到最大的收益呢?如果将这个问题对应到强化学习框架下,则赌徒是代理(agent),摇臂是动作(action),摇臂后得到的收益是奖励(reward)。
根据赌博游戏最直接的思路,我们可以先花费一定的金币进行探索(exploration),探测哪个摇臂的收益概率最大;然后利用(exploitation)之前探测得到的信息,将金币用在收益概率最大的摇臂上。“探索”和“利用”是在广告以及推荐系统中十分常见的一类问题。
把广告冷启动问题对应到多臂老虎机算法上,则每个广告对应一个摇臂,每摇一次臂对应着一次广告展示,广告上的 CTR×CPC(根据业务不同会略有不同)是收益。我们要解决的问题是每次如何展示广告,能够让最后的收益最大化。下面介绍业界中常用的两种多臂老虎机算法。注意这里我们讨论的老虎机每次摇臂后的收益是 1 或者 0,分别代表摇臂后有收益或没有收益,下文不再赘述。
可以看到,在 Thompson 采样算法中,每个臂刚开始时的 Beta 分布的方差比较大,采样值的随机性比较大,因而每个臂都有机会被选到;当摇臂次数的增加,Beta 分布的方差变小,算法会根据已经累积的数据做更加准确地选择。对比 UCB 算法和 Thompson 采样算法可以发现,这两个算法在选择臂时有个共同特点:要么然选择已经比较确定的较好的臂,要么选择还不太确定的臂。
上面描述的多臂老虎机算法都还比较简单,在实际业务场景中情况会复杂很多。其中最重要的一点是,上面的 UCB 算法和 Thompson 采样算法并没有考虑到上下文信息。在广告投放系统中,上下文关系是十分重要的因素,例如口红广告在女性用户流量上的 CTR 要远好于在男性用户上的 CTR。因此,广告投放系统需要一个考虑上下文信息的 Bandit 算法(contextual Bandit)。
Yahoo! 在 2010 年提出的 LinUCB 算法 [7],考虑了上下文信息的,是 UCB 算法的一个延伸。从名字可以看出,LinUCB 算法用线性组合关系来建模上下文信息与期望收益之间的关系。将广告系
这样,我们可以选择置信上界最大的臂,即:
总结下来,LinUCB 算法的基本流程如下:
上述 LinUCB 算法是在 UCB 算法的基础上,结合了上下文信息。微软在 2013 年提出了一个在 Thompson 采样算法中结合上下文信息的算法 [9],在工业界中应用也很广泛,有兴趣的读者可以进行拓展阅读。
小结点击率预估问题是计算广告领域的经典问题,机器学习算法在其中有着非常广泛的应用。选择模型和预测方法不仅仅是与数据量的大小以及应用场景有关系,还与点击率预估模块所在的整个广告系统的发展程度有关系。如果只是在系统搭建的初期,往往更推荐用更简单的点击率预估架构,使得整个系统形成一个回路;随着收集数据的增多以及系统稳健性得到的更大保障,我们可以逐渐尝试更复杂更精确的模型。
我们在一个大数据的时代,人们对互联网的依赖逐渐增强,各个公司收集到的用户数据也逐渐增多。如何利用这些数据一直是一个充满挑战和机遇的问题。有人说大数据这一方法论唯一形成规模化营收的落地行业就是计算广告。从这个角度看,计算广告的主要目的是把用户数据和用户流量转化成公司收入,这意味着营收和利润始终是计算广告无法回避的问题,这也是为什么点击率预估最高的结果往往不会作为最终推荐的结果,还要考虑公司的盈利来对结果做出调整。
参考文献:
[1] COVINGTON P, ADAMS J, SARGIN E. Deep neural networks for YouTube recommendations[C]//Proceedings of the 10th ACM Conference on Recommender Systems. ACM, 2016: 191–198.[2] CHENG H-T, KOC L, HARMSEN J, 等. Wide & deep learning for recommender systems[C]//Proceedings of the 1st Workshop on Deep Learning for Recommender Systems. ACM, 2016: 7–10.[3] JUAN Y, ZHUANG Y, CHIN W-S, 等. Field-aware factorization machines for CTR prediction[C]//Proceedings of the 10th ACM Conference on Recommender Systems. ACM, 2016: 43–50.[4] PAN J, XU J, RUIZ A L, 等. Field-weighted factorization machines for click-through rate prediction in display advertising[C]//Proceedings of the 2018 World Wide Web Conference. International World Wide Web Conferences Steering Committee, 2018: 1349–1357.[5] GUO H, TANG R, YE Y, 等. DeepFM: A factorization-machine based neural network for CTR prediction[J]. arXiv preprint arXiv:1703.04247, 2017.[6] ZHOU G, ZHU X, SONG C, 等. Deep interest network for click-through rate prediction[C]//Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. ACM, 2018: 1059–1068.[7] LI L, CHU W, LANGFORD J, 等. A contextual-bandit approach to personalized news article recommendation[C]//Proceedings of the 19th International Conference on World Wide Web. ACM, 2010: 661–670.[8] WALSH T J, SZITA I, DIUK C, 等. Exploring compact reinforcement-learning representations with linear regression[C]//Proceedings of the 25th Conference on Uncertainty in Artificial Intelligence. AUAI Press, 2009: 591–598.[9] AGRAWAL S, GOYAL N. Thompson sampling for contextual bandits with linear payoffs[C]//International Conference on Machine Learning. 2013: 127–135.
,