在前面的文章中我们可以简单推导出索引的形成过程,具体内容详情可以参考
演示表的基本结构如下所示
mysql> CREATE TABLE index_test(
-> c1 INT,
-> c2 INT,
-> c3 CHAR(1),
-> PRIMARY KEY(c1)
-> ) ROW_FORMAT = Compact;
Query OK, 0 rows affected (0.01 sec)
根据演示表得出主键索引的简单结构如下所示
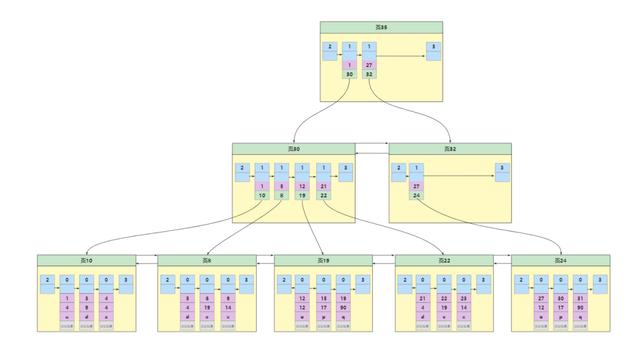
整个主键索引或者说B 树由数据页构成,当然数据页中采用记录头属性record_type区分了是业务记录还是目录项记录,0为业务记录,1为目录项记录。了解完这些我们就可以来聊聊索引的类型。
聚簇索引聚簇索引的特性一般是两个
- 使用记录主键值的大小进行记录和页的排序,这里面有三重含义
- 数据页中的记录与记录之间根据主键大小排序,并且形成单向链表。
- 存储业务数据的数据页之间按照主键的大小排序,并且形成双向链表。
- 存储目录项记录的数据页按照同样按照目录项记录主键大小顺序形成双向链表。
- B 树的叶子节点存储完整的业务记录(指包含该记录的所有列,包括隐藏列)。
我们将具有这种特性的B 树称为聚簇索引,这种索引不需要人为指定创建,InnoDB存储引擎会自动创建,而且在InnoDB存储引擎中,聚簇索引就是数据的存储方式,因为所有的数据都存储在B 树的叶子节点中,聚簇索引最明显的例子就是上图,完全符合。
二级索引二级索引也可以被称为普通索引,很明显就是给非主键值加索引,例如给演示表index_test的非主键列c2加索引,那么索引结构应该如下所示
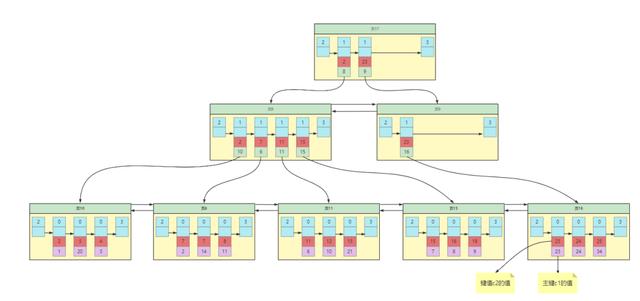
二级索引和聚簇索引有很大的区别,主要有如下三点
- 二级索引的索引树叶子节点,只保存c2列的值和主键值c1值的,不再保存完整记录。
- 记录排序和数据页排序都采用c2列排序,不再采用主键值排序。
- 目录项数据页存储的是c2列的值和页号,不再是主键值和页号。
查询过程也会所有调整,例如需要查询c2列为7的值,步骤如下
- 从根节点出发,定位到目录项数据页在页8(2 <= 7 <= 23)。
- 根据页8确定用户数据在页6( 2 <= 7 <= 7)。
- 定位到数据页后通过二分法才能定位到c2列为7的记录,但是这里仅仅能得到c1列的值和c2列的值,想要得到这条记录的其它值,还需要根据主键值c1的值再去聚簇索引中查询得到完整用户记录,这个过程称之为回表。
也就是说如果想通过二级索引查询完整用户记录,需要查询两个B 树,需要回表操作,为什么这样设计呢?显然是节省内存空间。
联合索引联合索引顾名思义就是同时以多列的大小进行排序,其本质也是一个二级索引,如给index_test表的c2,c3列同时建立索引,先按照c2列值排序,如果c2列值相同再按照c3列排序,所以在用户记录数据页中将存在三个值分别为c2列值,c3列值和主键c1列值,结构图如下

请注意这里因为组合索引包含了c2、c3列值,而记录中也会包含主键值,这里查询将不再需要回表的操作,但这并不能证明组合索引不需要回表操作。
,