大家晚上好,我是百度外卖智能物流部的研发工程师蒋能能,我于2015年底加入百度外卖,工作开始至今一直从事策略研发相关工作,在外卖先后担任商户判重、物流调度相关策略的研发工作。今晚很荣幸给大家介绍基于ES商户判重服务的设计与实践。
本次课程将主要从以下4个方面依次展开:
1.判重基础介绍;2.基础框架与检索引擎;3.分词解析计算;4.相关应用。
首先,我们从判重需求背景出发,阐述判重背景、基础概念与解决的问题;其次,我们会介绍相关检索引擎的选择以及服务整体框架与流程;然后,我们会深入到核心的分词解析计算中,给大家介绍具体判重过程与相关策略;最后,我们结合外卖实践给出目前判重服务在部分领域的数据应用实例。

在复杂的O2O市场餐饮市场中,商户一直是核心重点之一。商户对比分析一直是商户运营的重点之一,而要进行商户对比分析的前提是:我们必须找到当前商户所对应的相同商户,因此商户判重是商户级别数据分析的重要前提,同时商户判重产出的独有商户数据也是指导BD进行线下商户签约的重要依据。
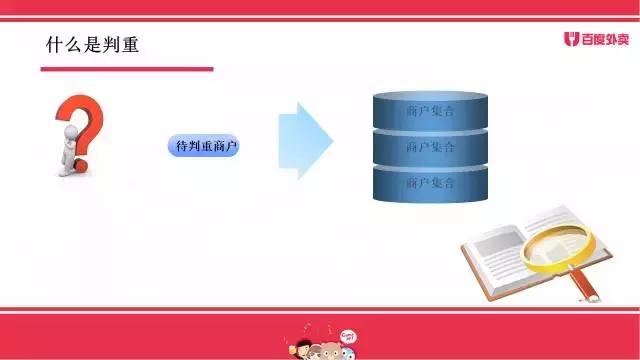
那么到底什么是判重,判重究竟做了什么?举一个通俗的例子,可以将判重过程类比为查字典的过程,当我们需要在数量众多的商户集合中找出一个新增商户的判重关系时,将新增商户视为陌生字词,那么库中商户集合则可以看作一本记录之前出现过字词的字典,判重过程可以视为在字典里面找陌生字词相关字词的过程。

在正式开始介绍判重之前,先了解一下商户判重面临的一些难点。
首先,商户数据量较大,达到百万量级,同时商户数据变化频率也很高,每一天都会有新的商户上线,老的商户下线,一些在线的商户本身的信息也不是一成不变的,因此,判重数据也必须是按照天级进行更新。
同时,商户名称在不同平台上也是有所差异的,拿整个名称进行完全匹配召回率很低,如何保证高效准确的剔除商户名称中的冗余干扰信息,取其中核心信息进行匹配计算是影响判重结果的核心与关键。
运行速率与判重效果是存在折中的,快速的运行速度代表匹配范围的缩小,而缩小的匹配范围则会导致整体召回率的降低,如何在运行速率与判重效果中获取最合适平衡点也是至关重要的。

这一部分我们从判重实际出发,深入浅出的给大家介绍当前主流检索引擎ES,以及目前我们在判重服务中应用到的相关检索模式。同时会介绍判重服务基础框架结构,包含的模块,以及每个模块具体实现的功能与设计思路。

就像查字典一样,我们不会一个一个去对比,无论是拼音还是部首,通过索引缩小我们查找范围永远是我们的第一选择。无独有偶,通过索引检索来缩小商户判重匹配范围也是判重高效运行的关键。结合我自己接触过的2套不同的商户判重代码,也是可以粗分为初步海选与细粒度比较2个部分。最早的判重服务是通过建立模型,进行初步筛选获取一个疑似商户列表,然后再通过策略判重对各项指标逐步进行详细计算,目前外卖判重也是通过ES检索缩小商户的匹配范围,再将具体字段进行一一比对进一步计算,获取最终结果。

涉及相关检索内容,这里先给大家介绍检索中2个核心的概念:全文检索与倒排索引。全文检索是指计算机通过扫描文件中每一个词,建立一个记录该词在对应文件中出现次数、位置的索引,通过这个索引就可以反向由词检索文件。一个检索引擎核心主要由磁盘索引文件、索引引擎、查询引擎、文本分析引擎几部分构成,在这个基础上进行接口开发就可以将全文检索功能添加到对应工程项目中。
倒排索引主要应用于根据属性查找记录的场景。通过倒排索引,我们可以获取到包含某一属性的所有记录集合标识,然后可以通过记录标识查找到相关的所有记录内容。

在判重服务我们选择ES作为检索引擎。ES全称Elasticsearch,基于目前性能最好、功能最全的全文检索工具包Apache Lucene实现。
它具有以下四个显著特点:1.实时检索,从文档索引到搜索完成接近实时;2.集群部属,ES本身就是一个集群,集群共同提供索引与搜索功能;3.稳定可靠,扩展节点保护数据不丢失,节点之间自动均衡,对外表现对等;4.安装方便,最简单安装方法去官网下载程序包直接解压运行即可。

针对检索引擎,我们做一个ES与SPHINX的横向对比。Sphinx基于C 开发,单机索引速率更快,同时资源占用率上也更低,对于通过MYSQL表建索引支持很好。ES主要使用java开发,虽然单机表现不如sphinx,但集群化部属能很大程度弥补单机速度上的缺陷,同时集群化也保证了高可用与更好的扩展。另外ES相关的辅助工具更为丰富,社区也更为活跃。

说到检索引擎,就不得不说的对应的检索模式,这里我们主要挑选判重涉及到的一些匹配模式进行介绍。判重检索场景主要会涉及3种检索方式:1.完全匹配,也就是我们检索的字段中必须完整包含检索短语,类似于sql查询中的like命令;2.分词匹配,将要检索的短语先进行分词,然后根据分词结果数量匹配其中一个或者多个;3.组合查询,通过与或条件将多个查询条件进行组合查询。这3种检索模式在ES、sphinx两种不同检索引擎中都有相关的模式支持。

商户判重服务整体框架结构可以分为3层,分别是数据处理、计算处理以及数据检索。其中数据处理部分主要由python脚本组成,进行数据流处理,通过tcp连接发送商户信息数据包;计算处理部分主要是接收商户信息进行相关分词解析,拼接查询语句发起http检索请求;数据检索是基于ES开发的一个检索服务,从impala集群导入索引数据,接收http请求进行相关查询,接下来我们详细介绍各个模块设计思想与主要功能。

数据处理层主要实现4个功能。1.与MYSQL进行数据交互,包含判重商户数据导出,判重结果记录等;2.数据流处理,商户具体数据处理,字段组合等;3.异常数据过滤,对于一些字段缺失严重,或者明显垃圾数据进行判重前的数据过滤;4.多次判重结果合并,多次检索模式会有不同批次结果,需要将判重结果进行合并。
我们可以发现,这里我们主要诉求就是数据流文件处理,同时可能会因为需求变更,导致数据流变化,因此我们针对文件处理多、需求会变更的场景选择python灵活的组合方式来实现这部分内容。

计算处理层是判重核心部分,很大一部分判重逻辑处理与数据计算都是在这一层进行的。对于每一个商户都会存在一个与之对应的判重请求,都需要执行子进程创建、名称地址电话解析、Http请求与json解析、相似度计算等处理。因此,在运行效率方面会有很高的要求,为此我们选择了效率更高的C 进行开发。
作为连接数据检索、数据处理的中间层,计算处理层需要使用json数据、http请求进行交互。这里我们使用git上C 编写的开源json解析工具RapidJSON实现C 的json解析处理,同时基于libcurl库的easy接口实现C 的get、post请求功能。

数据检索层主体是ES检索引擎,在ES检索基础上,基于ES查询接口我们构建了一个java web服务用来统一处理计算处理模块发起的http请求,并根据相关请求执行对应查询模式下的查询。

第三部分我们将围绕判重核心部分展开,主要介绍分词解析计算策略以及相关相似度计算方法。

商户判重主要涉及到4个商户核心信息,商户名称、地址、电话以及坐标。名称作为商户最为基本也是辨识度最高的信息维度,其中往往含有多个子维度信息,例如:商户地理信息、商户品牌、商户经营菜品、商户分店信息等。地址作为商户地理维度信息,能很大程度反映2个商户距离信息。电话作为商户特征之一,具有相同电话的2个商户极有可能是同一家商户。坐标作为地理维度的量化指标,相比地址形式多样化,坐标处理计算更为简单,但反之坐标也常常伴有不准确的问题。

因为O2O餐饮行业的一些不规范,很多时候会存在数据异常以及表述差异等情况。为了尽量避免这些因素干扰,在进行分词解析之前我们会对数据进行预处理,主要包括4个方面内容:1.将繁体字转换简体字;2.将一些无意义的特殊字符用空格替换;3.将部分简短中文数字统一使用阿拉伯数字替换;4.将一些成对出现同时具有括号含义的字符统一用英文括号替换。

不管是商户名称、地址还是电话,归根结底都是字符串,所以它们相似度计算都是以字符串相似度计算为基础,这里介绍2种最为常见的字符串相似度计算方法:字符串编辑距离与最长连续公共字符串。
字符串编辑距离主要基于将字符串A修改为字符串B所需代价的多少,会涉及插入、删除、替换操作,其中替换操作权值为2,因为一次替换可以视为插入与删除的操作集合。用字符串长度和减去操作次数除以字符串长度获取相似度。
相比字符串编辑距离,最长连续公共子串则更加强调相同部分的连续性,通过计算最长连续公共字符串长度占比反映2个字符串的相似度。

我们来看一个名称相似度计算的例子,2个商户名称:北京品尚烤肉城、品尚正宗烤肉披萨自助(西二旗店)。直观来看,这两家是同一家店的可能性还是很高,但是无论采用字符串编辑距离还是最长公共字符串来计算,得到的相似度都是非常低的。
究其原因,是因为1.商户名称中有冗余信息;2.每个名称中含有的信息也不是完全相同的;3.同样信息对应的粒度也是不一样的。在我们眼中商户名称中每个字的权值是不一样的,例如,‘北京’与‘正宗’我们都是不关心,我们真正看重的是“品尚”与“烤肉”2个词。所以在名称匹配与相似度计算中,我们首先需要明确名称中哪一部分比较重要,哪一部分相对来说可以忽略。

基于我们对平台上众多O2O餐饮商户名称的分析,我们提出了这样的一种商户名称结构模型。以地理位置信息开始,可能是国家、省份、城市等,例如新疆买买提烧烤中的新疆;其次,后面会跟商户品牌,例如张亮麻辣烫中的张亮;在商户品牌后一般会带有商户菜品,例如杨铭宇黄焖鸡米饭中的黄焖鸡米饭。而商户名称最后一般是以括号后缀结尾的商户分店信息。
当然以上的4个部分,不保证所有商户名称中都具有,但是最重要的商户品牌一定不能为空,如果为空,可以将前后部分拼凑作为商户品牌。现在再反过来看之前的2个case,我们可以得到北京地理信息、品尚品牌信息、烤肉商户菜品、西二旗商户分店信息,这样一一对应,我们便能发现这2个商户品牌都为品尚,经营菜品都包含烤肉,在这样条件下对应的相似得分将会大大提高。
除此之外,为了保证分词结果符合我们的预期,我们在基础分词字典上添加了许多含有O2O餐饮行业色彩的词,例如知名的餐饮商户品牌、各种菜品名称以及一些O2O餐饮商户名称中经常出现的冗余字词。通过我们对分词字典的特殊定制化,来保证分词结果是符合我们预期的。

下面说一下具体计算规则,商户地理信息主要用来过滤,如果名称中地理信息不同,则得分为0;商户品牌则采用字符串相似度计算的方法计算其相似度,加权算入名称总得分中;菜品可能有多个,我们选2个商户菜品两两进行字符串相似度计算,取其中得分最高者作为名称中菜品相似度;分店计算相似度前需要过滤市级以上地理信息,以及店等关键字,例如:北京上地店,我们最后只取”上地”作为商户分店信息。
相比于名称,其他部分计算规则则相对简单很多,地址由于其不规范性,最理想的情况是XX市XX区XX街XX号,但是很多情况我们地址都是根据身边一些地理特征来进行地址标识的,例如哈尔滨工业大学南门外,彩虹大厦对面等,因此,地址相似度计算只能对应计算那些明确给出街道的情况,因此这个结果需要根据坐标计算结果进行调整。
电话解析计算核心是需要识别正确的电话号码,排除号码前缀后缀以及部分电话中间含有的空格等字符的干扰,为此,我们需要统计全国各地的区号前缀,结合电话长度判断,手机号则需要根据前三位特征进一步判断其是手机号还是固定电话 前后缀形式。对于2个商户有多个电话情况下,彼此两两计算相似度,取最高者作为最终电话相似度。
坐标距离计算相对来说是最为简单的,采用坐标计算距离公式即可,但是考虑到坐标的不准确性,这个结果需要结合地址计算结果进行调整,取其中较高者。

之前提到了使用检索引擎缩小匹配范围,结果分词解析,我们从商户名称地址电话出发选择了4种检索召回方式:1.使用商户品牌进行完全匹配;2.使用去除县级以上信息后的地址进行完全匹配;3.使用商户的每一个电话进行完全匹配,取匹配结果并集;4.使用完整商户名称进行分词匹配。这四种检索方式相互结合能涵盖大部分情况,在判重运行速率与判重召回率上两者间做出合理的折中。

最终的相似度主要由名称、地址、电话、坐标各自的相似度加权得到,其中名称占比最高,地址次之,电话不同减分不多,当电话相同的情况下会调高电话占比。对于一些字段缺失情况,首先名称不能为空,除名称外不能有2个字段同时缺失,其他情况则会通过重新调整各部分阈值进行降级处理。此外,针对一些特定case还会有对应调整策略,例如名称中分店相似度会影响地址相似度,地址坐标相似度相互影响,名称相似度特别高,地址相似度特别低,当作连锁店处理,降低名称权值。400开头全国通用电话相同不加分等。

相似度计算本身可以看作是一个典型的分类问题,输入是各个维度相似度值与一些相关策略判断结果,输出则是01性的。通过人工筛选的一部分结果绝对正确的数据集进行相关训练,已考虑用决策树或者简单的分类器进行替换实现。

第四部分我们简单介绍一下目前判重结果在外卖各个平台上应用情况,主要包括人工绑定&解绑以及商户对比2个方面。
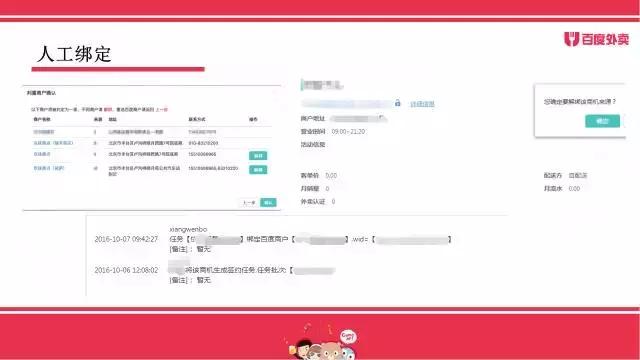
判重服务准确率、召回率不可能达到100%,对于一些有一定相似得分同时又低于相同阈值的case,借助于外卖B端任务制平台,我们将提供这部分疑似数据给线下BD,通过人工判断方式进行人工判重,并将对应结果与自动判重结果进行合并优化。除了绑定之外,对于判重错误的case,也有相关解绑入口。通过绑定解绑操作,在优化判重数据的同时也让线下BD更好的了解到自己商圈商户覆盖情况。

商户对比则是通过判重结果,将不同平台上的相同商户进行横向比较,在优惠活动、营业时间、下单量等指标对比,找出各种差异,进行相关营销策略调整。
本次分享到此结束,感谢大家的支持。谢谢大家!
,




