
本文主要根据 “Operating Systems: Three Easy Pieces” 第15章总结而来。
在本头条号之前的文章中有介绍,操作系统为了实现CPU虚拟化,采用的策略是:大部分情况下,让进程直接在CPU上运行,这样效率最高。但是为了不丧失对CPU的控制权,进程在进行系统调用时,或者操作系统设置的定时中断被触发时,操作系统又回重新夺回控制权。从这个层面看,高效和可控是现代操作系统设计的核心。内存虚拟化也不例外。
为了实现内存虚拟化,高效和可控也是首先需要考虑的因素。高效意味着,进程能很容易地在硬件的帮助下访问内存;可控意味着没有一个进程能随意访问别的进程的内存,从而对进程进行保护,也对操作系统进行了保护。除了高效和可控,内存虚拟化还有一个额外的要求就是灵活,灵活指的是我们希望进程能按照它想要的方式随意使用它地址空间内的进程,从而让编程变得简单。
代码很简单,先加载内存中的值,然后加3,最后把计算后的值保存到内存中。从进程的角度看,代码和数据在它的地址空间内如下图所示:
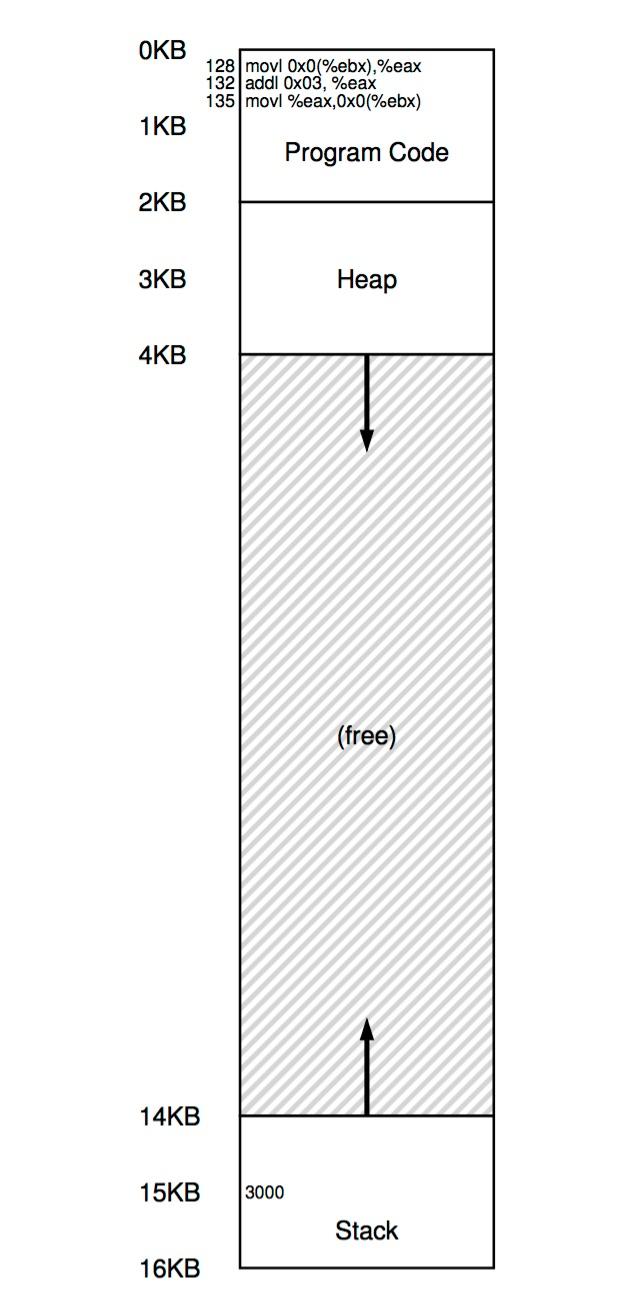
可以看到,加3的代码从地址128开始(靠近代码段的顶端),变量x的值保存在地址15k的位置(靠近栈的底端),初始值是3000。当指令运行之后,从进程的角度看它会这样使用内存:
-
从128获取指令
-
执行指令(从15k的位置加载数据)
-
从132获取指令
-
执行指令(不用读取内存)
-
从135获取指令
-
执行指令(把数据写入15k的位置)
也就是说,进程认为它的地址空间是从0开始,最大是16k,所有的内存访问都必须在0-16k之间。然而,为了实现内存虚拟化,操作系统不一定会把进程放到物理内存0开始的位置。一个可能的视图如下图所示:

从图片来看,进程被放在了物理内存32k-48k的位置,16k-32k和48k-64k的位置还未被使用。那么问题来了,如何在进程无感知的情况下,把进程地址空间放到物理内存的指定位置呢?
基于硬件的动态重定位(或者是动态迁移)
前面的介绍都是背景,下面具体来看操作系统到底是怎么实现地址翻译的。这里就引出了内存管理单元(memory management unit, MMU)中最基本的两个寄存器:基地址寄存机和上界寄存器,base and bounds。后续会使用英文,因为英文更能表达含义。
当进程最初开始运行的时候,操作系统会根据目前系统可用的内存情况,设置base寄存器的值。比如上面的例子进程的物理地址是从32k开始的,那么base寄存器会设置成32k。当进程想获取地址128的指令时,它会被翻译成 32k(32768) 128=32896,这样就能从物理地址里面取到真正的指令了。这就是所谓的地址翻译!重复一下公式: 物理地址 = 虚拟地址 + 基地址
那么bounds寄存器什么时候用呢?也是在进程最初运行的时候,操作系统预分配一定大小的内存给进程,bounds寄存器就会被设置成最大的值,比如上面的例子,被设置成16k。当进程试图引用大于16k的地址空间时,系统会抛出一个异常,这个异常就是因为检查了bounds寄存器中的值。
从上面的流程可以看到,操作系统是在进程运行起来之后,根据系统可用的内存状况来设置base and bounds,这个过程被称作动态重定位。与它相对的也有静态重定位,静态重定位发生在编译器,也就是说,程序编译完了就知道基地址是什么了。可想而知,静态重定位不具有移植性,在不同内存大小的系统就需要重新编译,就算内存大小相同也要根据系统可用的内存而定。所以,目前基本上操作系统都是基于MMU中的 base and bounds寄存器,使用动态重定向的技术。
操作系统的角色
上面说到的是硬件,特别是MMU起的作用,那么操作系统起了什么作用呢?
-
首先,系统可用的内存列表是由操作系统维护的。有很多数据结构可以完成这个任务,随着我们的深入研究会不断介绍新的数据结构。这里我们先看最简单的数据结构叫空闲链表,free list。Free List很简单,把可用的内存分成很多块,每一块当作一个节点放到链表中。当新的进程来的时候,从列表中取一段内存给它,并把这段内存删掉。当进程退出后,再把内存块放到free list里面来。
-
其次,在CPU做上下文切换的时候,操作系统必须要把base and bounds的数据也存储到PCB中。这样当进程重新被调度运行的时候,它依然能找到自己的代码和数据。
-
第三,既然进程可以切换,base and bounds可以被保存和读取,那么在适当的时候,操作系统也可以移动进程在内存中的位置,只需要移动之后把base and bounds更新就可以了。这其实也是动态重定位的体现。
-
最后,操作系统必须在启动的时候,额外注册一个异常句柄,也就是bounds溢出的处理函数,保证进程访问界限之外的内存区域被操作系统拒绝。
总结
基于之前我们做的假设,内存空间的大小是一定的,而且小于物理内存的大小,所以free list能满足我们的需求。但是我们应该看到,这些假设可能造成的问题。毕竟,并不是所有的进程用的地址空间都是一样的,我们系统地址空间的大小是可变的。另外,如果有些内存块太小它就没办法被分配给进程,这块内存就会被浪费掉,也就是我们说的内存碎片。
解决这些问题就需要引入内存分页和分段的技术,这是后面会继续的内容。欢迎大家订阅我的头条号,第一时间收到更新,谢谢!
,




