DeePMD-kit的模型训练DeePMD-kit的安装教程,现在小编就来说说关于volume builder为什么会有缺口?下面内容希望能帮助到你,我们来一起看看吧!

volume builder为什么会有缺口
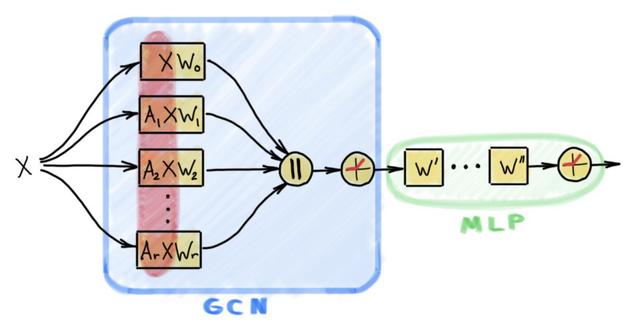
DeePMD-kit的模型训练
DeePMD-kit的安装教程
DeePMD-kit的数据转换(一)
DeePMD-kit的数据转换(二)
深度学习势套件 DeePMD-kit和DP-GEN介绍
根据手册,DeePMD的并行训练是在Horovod的帮助下以同步方式实现的,那么Horovod又是什么呢?Horovod 是一套面向 TensorFlow 的分布式训练框架,由 Uber 构建并开源,目前已经运行于 Uber 的 Michelangelo 机器学习即服务平台上。
Horovod 能够简化并加速分布式深度学习项目的启动与运行。通过利用 MPI实现应用环状规约,显著提升 TensorFlow 模型的实用性与性能表现。查阅资料发现,Horovod 的分布式貌似只支持同步更新式的数据并行,至于模型并行和异步更新式的数据并行,根据 ring-allreduce 算法可知,应该是不支持的。根据训练进程的数量和可用的GPU卡数量,DeePMD-kit将决定是以并行(分布式)模式还是串行模式启动训练。
标定学习率
Horovod在数据并行模式下工作,从而产生更大的全局batch size。例如,当输入文件中的batch size设置为2时,启动了4个工作进程,实际批处理大小为8。因此,学习率会根据工作进程的数量自动调整以实现更好的收敛。
在相同精度下,增加卡数可以减少所需的衰减步数的数量(在上述情况下为步数的1/2),但需要在输入文件中手动调整。
在某些情况下,当利用以线性方式统计的进程数来标定学习率时,程序不会很好地工作。可以通过设置参数scale_by_worker来尝试sqrt或NONE,如下所示:
"learning_rate" :{"scale_by_worker": "none","type": "exp" }
效率测试
在8-GPU主机上测试示例/water/se_e2_a,随着GPU卡数量的增加,可以观察到线性加速的效果。
| GPU卡数 | 秒/100样本 | 样本/秒 | 加速 |
|---|---|---|---|
| 1 | 1.4515 | 68.89 | 1.00 |
| 2 | 1.5962 | 62.65*2 | 1.82 |
| 4 | 1.7635 | 56.71*4 | 3.29 |
| 8 | 1.7267 | 57.91*8 | 6.72 |
训练进程可以用horovodrun启动,以下命令在同一主机上启动4个进程:
CUDA_VISIBLE_DEVICES=4,5,6,7 horovodrun -np 4 \dp train --mpi-log=workers input.json
注意:必须设置环境变量CUDA_VIREBLE_DEVICES以控制占用的主机上的并行数,在该主机上,一个进程绑定一个GPU卡。当使用MPI时,Horovod自动检测并调用mpirun,例如:
CUDA_VISIBLE_DEVICES=4,5,6,7 mpirun -l -launcher=fork \-hosts=localhost -np 4 dp train --mpi-log=workers input.json
在输出的log文件中,可以看到下面的输出信息!
[0] DEEPMD INFO ---Summary of the training---------[0] DEEPMD INFO distributed[0] DEEPMD INFO world size: 4[0] DEEPMD INFO my rank: 0[0] DEEPMD INFO node list: ['exp-13-57'][0] DEEPMD INFO running on: exp-13-57[0] DEEPMD INFO computing device: gpu:0[0] DEEPMD INFO CUDA_VISIBLE_DEVICES: 0,1,2,3[0] DEEPMD INFO Count of visible GPU: 4[0] DEEPMD INFO num_intra_threads: 0[0] DEEPMD INFO num_inter_threads: 0[0] DEEPMD INFO ------------------------------------