在上一篇文章我们讲述了python爬虫的urllib常用方法,不少同学可能觉得光知道语法有什么用,又干不了什么事情。那么今天作者就带大家用urllib方法实战一番,自己制作一个翻译器。话不多说,直接开始。我会先讲解步骤,如果大家需要完整代码,自行在文章后面取用。
首先,我们应该知道访问浏览器有最基本的两种方法,一种是GET请求,一种是POST请求,而POST请求就是让我们提交表单后获取数据的。这里我们以有道词典为例子。

我们打开浏览器检查,观察输入表单后提交给浏览器的数据是什么,并观察返回的信息是什么。
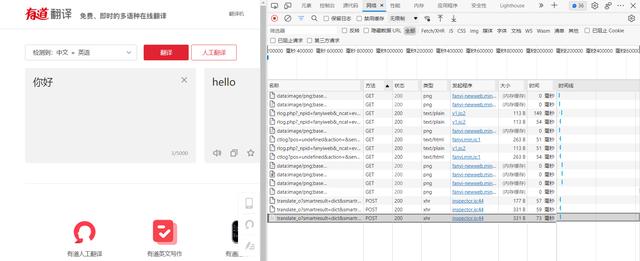
这里点击网络并找到POST类型,标头的请求URL就是我们实际上访问的URL

图中的表单数据便是我们提交给服务器的数据。
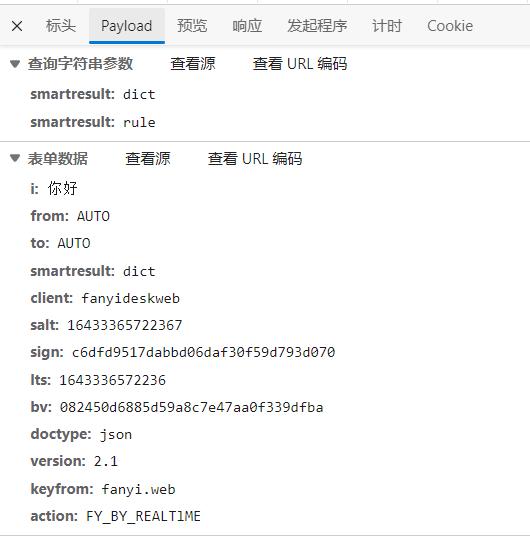
我们上篇文章讲解到urllib.request.urlopen()方法中的url参数,而它后面还有一个data参数就是我们提交表单的信息。接下来的讲解我将注释在代码块中
import urllib.request#请求模块
import urllib.parse#解析模块
import json#因服务器返回给我们的数据是json格式,所以导入json模块
content = input('请输入翻译的内容:')
url = "https://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule"#可能由于有道反爬的原因,translate_o需去掉_o才能访问
data = {}#我们刚才通过检查得到的表单数据,并把‘你好’换成content变量以便我们进行获取用户输入
data['i']= content
data['from']= 'AUTO'
data['to']= 'AUTO'
data['smartresult']= 'dict'
data['client']= 'fanyideskweb'
data['salt']= '16433365722367'
data['sign']= 'c6dfd9517dabbd06daf30f59d793d070'
data['lts']= '1643336572236'
data['bv']= '082450d6885d59a8c7e47aa0f339dfba'
data['doctype']= 'json'
data['version']= '2.1'
data['keyfrom']= 'fanyi.web'
data['action']='FY_BY_REALTlME'
data = urllib.parse.urlencode(data).encode('utf-8')#将data先翻译成浏览器能读懂的类型编码为utf-8格式,因为data参数是字节流类型
response = urllib.request.urlopen(url,data)#访问
html = response.read().decode('utf-8')#将获取的数据解码为utf-8格式防止乱码
target = json.loads(html)#json格式加载
print('翻译结果是:%s'% (target['translateResult'][0][0]['tgt']))
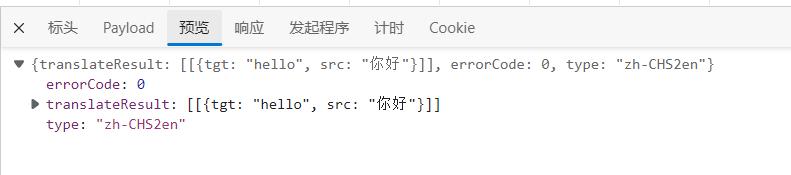
图中translateResult便是我们需要的数据。最后让我们看看运行的结果如何。

大功告成,最后希望大家多多关注我,喜欢我的文章给我点个赞,我会经常分享实用有趣的知识。
,