摩斯电码:

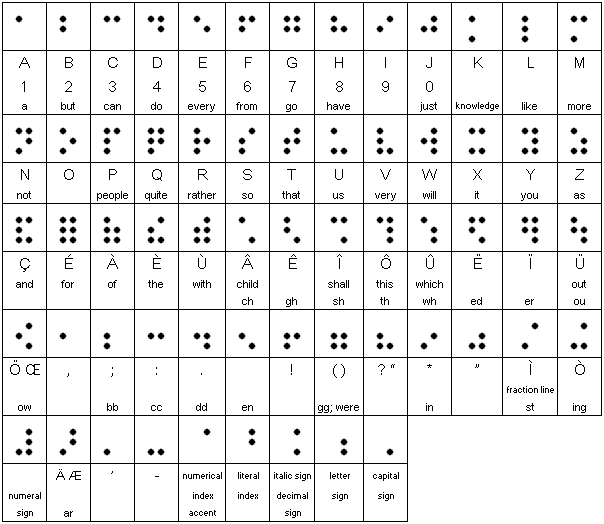
布莱叶盲文编码:
条形码、二维码:

二维码,又称二维条码,它是用特定的几何图形按一定规律在平面(二维方向)上分布的黑白相间的图形。相比一维的条码,二维码能够在横向和纵向两个方位同时表达信息,因此能在很小的面积内表达大量的信息,同时可以有较高的容错能力。
电子计算机用晶体管作为逻辑开关元件,用开关电路实现布尔运算,用循环(记忆)电路实现逻辑存储。
数字化、比特化也要实现编码、解码的问题。
编码是编程首先要面对的问题。
程序涉及到数据的表示、数据的输入、输出,数据处理,以及数据存储:
I 数据需要多大?需要占据多少个存储单元? II 用哪个存储单元的地址作为数据存储空间的地址? III 这一串二进制如何编码和解码?
1 数值类型的编码1.1 有符号整型编码
计算机中的符号整形数有三种表示方法,即原码、反码和补码。三种表示方法均有符号位和数值位两部分,符号位都是用0表示“正”,用1表示“负”,而数值位,三种表示方法各不相同。
在计算机系统中,整型数值一律用补码来表示和存储。原因在于,使用补码,可以将符号位和数值域统一处理;同时,加法和减法也可以统一处理。此外,补码与原码相互转换,其运算过程是相同的,不需要额外的硬件电路。
1.1.1 原码
计算机中所有的数均用0,1编码表示,数字的正负号也不例外,如果一个机器数字长是n位的话,约定最左边一位用作符号位,其余n-1位用于表示数值。
在符号位上用"0"表示正数;用"1"表示负数。数值位表示真值的绝对值。凡不足n-1位的,小数在最低位右边加零;整数则在最高位左边加零以补足n-1位。这种计算机的编码形式叫做原码。
数的范围就是-(2^(n-1)-1)~ 2^(n-1)-1,n=8是这个范围就是-127~ 127。
原码不能直接参加运算,可能会出错。例如数学上,1 (-1)=0,而在二进制中00000001 10000001=10000010,换算成十进制为-2。显然出错了。
另外,对于0的表示也有两表示形式,不满足唯一性的要求。
所以原码的符号位不能直接参与运算,必须和其他位分开,这就增加了硬件的开销和复杂性
1.1.2 模的概念
“模”是指一个计量系统的计数范围。如时钟等。计算机也可以看成一个计量机器,它也有一个计量范围,即都存在一个“模”。例如:
时钟的计量范围是0~11,模=12。表示n位的计算机计量范围是0~2^(n)-1,模=2^(n)。
“模”实质上是计量器产生“溢出”的量,它的值在计量器上表示不出来,计量器上只能表示出模的余数。任何有模的计量器,均可化减法为加法运算。
例如:假设当前时针指向10点,而准确时间是6点,调整时间可有以下两种拨法:一种是倒拨4小时,即:10-4=6;另一种是顺拨8小时:10 8=12 6=6
在以12模的系统中,加8和减4效果是一样的,因此凡是减4运算,都可以用加8来代替。对“模”而言,8和4互为补数。实际上以12模的系统中,11和1,10和2,9和3,7和5,6和6都有这个特性。共同的特点是两者相加等于模。
对于计算机,其概念和方法完全一样。n位计算机,设n=8, 所能表示的最大数是11111111,若再加1成为100000000(9位),但因只有8位,最高位1自然丢失。又回了00000000,所以8位二进制系统的模为2^8。在这样的系统中减法问题也可以化成加法问题,只需把减数用相应的补数表示就可以了。把补数用到计算机对数的处理上,就是补码。
1.1.3 整型的补码
求给定数值的补码分以下两种情况:
正整数的补码是其二进制表示,与原码相同。
9的补码是00001001。
求负整数的补码,将其原码除符号位外的所有位取反(0变1,1变0,符号位为1不变)后加1 。
同一个数字在不同的补码表示形式中是不同的。比如-15的补码,在8位二进制中是11110001,然而在16位二进制补码表示中,就是1111111111110001。以下都使用8位2进制来表示。
-5对应正数5(00000101)→所有位取反(11111010)→加1(11111011)
所以-5的补码是11111011。
已知一个数的补码,求原码的操作其实就是对该补码再求补码。
一个负整数(或原码)与其补数(或补码)相加,和为模。 对一个整数的补码再求补码,等于该整数自身。 补码的正零与负零表示方法相同。

1.2 无符号整形的编码
在不需要考虑数的正负时,就不需要用一位来表示符号位,n位机器数全部用来表示是数值,这时表示数的范围就是0~2^n-1,n=8时这个范围就是0~255.没有符号位的数,称为 无符号数。
1.3 浮点型编码:符号位 指数位(移码) 数据位
I 十进制数形式
由数码0~ 9和小数点组成。例如:0.0,.25,5.789,0.13,5.0,300.,-267.8230等均为合法的实数。
II 指数形式
由十进制数,加阶码标志“e”或“E”以及阶码(只能为整数,可以带符号)组成。其一般形式为a E n (a为十进制数,n为十进制整数)其值为 a*10,n 如: 2.1E5 (等于2.1*10的5次方), 3.7E-2 (等于3.7*10的-2次方) 0.5E7 (等于0.5*10的7次方), -2.8E-2 (等于-2.8*10的-2次方),以下不是合法的实数
345 (无小数点) E7 (阶码标志E之前无数字) -5 (无阶码标志) 53.-E3 (负号位置不对) 2.7E (无阶码)
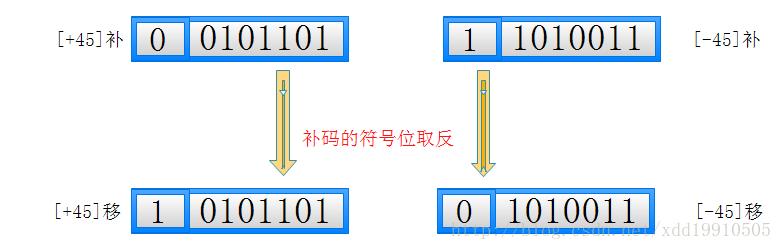
用补码表示阶码的时候,当阶码无限小,产生了下溢的时候,阶码变成了0,那么这个浮点数的值变为了1。
而实际上这个数是无限接近于零的。那么我们就需要取出其中的 "-0“ 值作为机器零。
IEEE754 国际标准规定了,基数为2,阶码采用移码,尾数采用原码。因为规格化原码的最高位恒为1,所以不在尾数中表示出来,计算时候再尾数的前面自动添加1。

符号域:符号域占1位,0表示正数 ,1表示负数。
指数域:指数域共有8位,可表达的范围为:0~255。为能处理负指数,实际指数位存储在指数域中值减去一个偏移量(单精度为127,双精度为1023)。单精度浮点数的偏移量为127,故实际可表达的指数值的范围为-127~128。
尾数域:尾数域共有23位。由于规范浮点数的小数点左侧必须为1,所以在保存尾数时,可以省略小数点前面这个1,从而腾出一个二进制位来保存更多的尾数。
举例:比如对于单精度 数而言,二进制的1001.101(对应于十进制 的9.625)可以表达为1.001101 ×2^3,所以实际保存在尾数域中的 值为0011 0100 0000 0000 0000 000,即去掉小数点左侧的1,并用0 在右侧补齐。
整数部分(9)的计算:1001 小数部分(0.625)的计算: 0.625*2=1.25--------1 0.25 *2=0.5 ----------0 0.5 *2=1.0 -----------1 所以用二进制科学表示方式为:1.001101*2^3
将实数-9.625变换为相应的浮点数格式。
1) 求出该实数对应的二进制:1001.101,用科学计数法表示为:-1.001101 ×2^3;
2) 因为负数,符号为1;
3) 指数为3,故指数域的值为3 127 = 130,即二进制的10000010;
4) 尾数为1.001101,省略小数点左边的1后为001101,右侧0补齐,补够23位,
最终尾数域为:00110100000000000000000;
5) 最终结果:1 10000010 00110100000000000000000,用16进制表示:0xC11A0000。
在计算机系统的发展过程中,曾经提出过多种方法表达实数。典型的比如相对于浮点数的定点数(Fixed Point Number)。在这种表达方式中,小数点固定的位于实数所有数字中间的某个位置。货币的表达就可以使用这种方式,比如 99.00 或者 00.99 可以用于表达具有四位精度(Precision),小数点后有两位的货币值。定点数表达法的缺点在于其形式过于僵硬,固定的小数点位置决定了固定位数的整数部分和小数部分,不利于同时表达特别大的数或者特别小的数。即数值范围和数值精度是个矛盾的问题!最终,绝大多数现代的计算机系统采纳了所谓的浮点数表达方式! IBM在1954年发布了IBM704,它是第一台将浮点数运算硬件作为可选配件的商用计算机,该机器以36位来存储所有的数。对于浮点数,36位被分为27位的有效数,8位的指数和1位的符号位。浮点运算硬件可以直接进行加法减法乘法除法运算,其他的浮点运算则必须通过软件来实现。 1980年开始,浮点运算硬件开始应用于桌面计算机,这起始于英特尔当年发布的8087数字协同处理芯片,当时这种集成电路被称做数学协同处理器或浮点运算单元。
2 字符类型编码2.1 ASCII编码(单字节)
char ch ='a';//窄字符 cout<<"ASCII编码:"<<ch<<":"<<int(ch)<<",size is:"<<sizeof(ch)<<endl; //ASCII编码:a:97,size is:1
2.2 GBK(子集GB2312)编码(宽字节)
wchar_t ch2 ='中';//宽字符 cout<<"GB2312简体中文编码:"<<ch2<<":"<<hex<<long(ch2)<<",size is:"<<dec<<sizeof(ch2)<<endl; //GB2312简体中文编码:54992:d6d0,size is:2
2.3 unicode编码(宽字节)
wchar_t ch3 =L'中';//宽字符 cout<<"unicode编码:"<<ch3<<":"<<hex<<long(ch3)<<",size is:"<<dec<<sizeof(ch3)<<endl; //unicode编码:20013:4e2d,size is:2 wchar_t Str[] = L"Hello"; cout<<"L\"Hello\"的长度:"<<dec<<sizeof(Str)<<endl; //L"Hello"的长度:12
2.4 特殊字符的转义序列和特殊码值
#include<stdio.h> #include<stdlib.h> #include <locale.h> int main(void) { char s[]="中";//汉字在C/C 中是用2个字节表示 char m[3]; printf("%d %d\n",s[0],s[1]); m[0]=-42; m[1]=-48; m[2]=0; puts(m);//两个字节连起来凑成一个汉字。 printf("%c%c\n",s[0],s[1]); printf("%c%c\n",214,208);//d6,d0 //都是字符256模数的关系 setlocale(LC_ALL, "chs"); wchar_t wc = L'\x4E2D'; wprintf(L"%c\n",wc); system("pause"); return 0; } /* -42 -48 中 中 中 中 */
2.5 用C语言写UTF-8编码的文件
I 为 fopen 指定一个编码,然后写入 wchar_t 字符串,最终写入的文件就是UTF-8编码的了。
#include <stdio.h> #include <tchar.h> int main() { FILE* fp = fopen("test.txt", "wt ,ccs=UTF-8"); wchar_t* s = _T("hello, 你好!"); fwrite(s, sizeof(wchar_t), wcslen(s), fp); fclose(fp); return 0; }
II 先将字符串编码转换为UTF-8格式的,然后再写入。
#include <stdio.h> #include <string.h> #include <Windows.h> int main() { FILE* fp = fopen("test.txt", "wb "); // 写入UTF-8的BOM文件头 char header[3] = {(char)0xEF, (char)0xBB, (char)0xBF}; fwrite(header, sizeof(char), 3, fp); char* s = "hello, 你好!"; wchar_t wc[256]; // 将ANSI编码的多字节字符串转换成宽字符字符串 int n = MultiByteToWideChar(CP_ACP, 0, s, strlen(s), wc, 256); if ( n > 0 ) { wc[n] = 0; char mb[1024]; // 将宽字符字符串转换成UTF-8编码的多字节字符串 n = WideCharToMultiByte(CP_UTF8, 0, wc, wcslen(wc), mb, 1024, NULL, NULL); if ( n > 0 ) { mb[n] = 0; fwrite(mb, sizeof(char), strlen(mb), fp); } } fclose(fp); return 0; }
-End-
,




