Fluid 是云原生基金会 CNCF 下的云原生数据编排和加速项目,由南京大学、阿里云及 AlluxIO 社区联合发起并开源。本文主要介绍云知声 Atlas 超算平台基于 Fluid Alluxio 的计算加速实践,以及 Fluid 是如何为 Atlas 带来全新的数据集管理方式的。
Atlas平台介绍云知声是一家专注物联网人工智能服务公司。云知声的 AI 技术栈涵盖了信号、语音、图像、文本的感知和表达能力,知识、理解、分析、决策等认知技术,并朝着多模态人工智能系统方向发展。云知声 Atlas 超算平台作为底层基础架构,支持着公司在 AI 各个领域的模型训练与推理服务的开展。云知声很早就开始布局建设业界领先的 GPU/CPU 异构 Atlas 计算平台和分布式文件存储系统,该计算集群可为 AI 计算提供高性能计算和海量数据的存储访问能力。
云知声团队基于 kubernetes 开源架构之上,进行了相应的核心功能研发,成功构建了浮点处理能力超过10 PFLOPS(一亿亿次/秒)的 AI 超级计算服务平台。该平台支持主流机器学习架构,开发者能够实现语音、语言、大数据、多模态等核心技术的高效研发。平台也开放了相应的算力与存储,为中小微企业和院校机构提供定制化计算服务。
问题与挑战Atlas 计算平台采用是计算与存储分离的架构,目前整个平台的存储服务器、计算服务器之间以及计算与存储服务器之间的底层网络架构是由 100GB 的 InfiniBand 进行互联。

计算平台的模型训练数据存储系统由多套 PB 量级的高性能分布式文件系统 Lustre 组成。Lustre 分布式文件系统兼容 POSIX 接口,多种深度学习框架能够直接进行数据读取。计算与存储分离的架构使计算跟存储能够独立进行扩容,整体架构较为灵活。但是之前平台也遇到了数据访问效率低与底层存储带宽瓶颈等问题:
存储宽带瓶颈
在存储资源相对固定的情况下,随着平台用户的增加,其带宽、元数据负载以及服务器的负载都呈现出来较大的上升。集群存在多个单机任务运行在同一个 GPU 节点,造成 IO 资源的竞争,由于 IO 的竞争导致了整个训练周期拉长了,大大降低了研发影响效率。
海量小文件
第二个问题是模型训练数据集本身的特点问题。在降噪场景中有用户的任务存在接近 TB 量级的小文件,导致底层分布式文件系统的的元数据服务压力很大。大量的小文件使得程序本身读数据的效率较低,数据读取缓慢造成 GPU 大部分时间在等数据,整体 GPU 的整体利用率较低,延长了模型的训练周期。
数据种类多
由于平台支持的业务类型较广,用户的数据类型较多,文件大小类型也不同,很难通过调优一套存储的参数来适配多种业务类型。结合用户的业务类型分析,我们发现平台数据主要还是用来做模型训练占的比重比较大,其余部分主要进行模型的推理与 CPU 密集型数据生成任务。
数据冗余
在平台中存在数据集重叠的问题,同一个组内或者不同组有使用到相同的数据集,但是却存储了多份,造成了存储空间的浪费。
早期解决方案如何通过最小的预算与架构改动来应对存储总带宽的瓶颈以及减少元数据服务器的压力,云知声 Atlas 也进行一系列的探索与研发。
宽带限制
考虑到大量的并发读取会造成存储带宽达到极限,造成存储卡顿或者存储系统瘫痪。平台通过限制每个计算节点的客户端带宽以及每个用户的 UID/GID 限制带宽,但是该方法存在不够灵活、没办法充分利用 GPU 的计算能力的问题,当有 2 个大 IO 的训练任务分配到了同一个节点,由于节点的带宽限制,2个训练任务的 IO 都有上限,数据读取的速度限制导致 GPU 没办法充分发挥并行读取的优势,通过监控发现该类型的 GPU 利用率在 40% 左右,严重浪费了硬件资源。
聚合大文件
考虑到平台的小文件太多,会对元数据造成较大的压力,我们进行了相应的措施,首先通过检测每个用户的 inode 数量与存储总量判断用户的小文件数量,限制用户小文件的数量。第二是推行一系列数据聚合的工具,让用户将小文件聚合成 lmdb、tfrecord 之类的大文件格式。
任务调度器重构
为了避免任务都聚集在同一个节点上,我们通过定制任务调度器插件,增加调度策略,判断节点的计算资源的使用情况,优先将任务调度到空闲节点,避免多个任务跑在同一个节点造成的 IO 竞争,但是该方案在平台的计算资源出现满载的情况下还是不可避免。
多级缓存
为了充分利用空闲的硬件以及减轻底层存储系统的压力,在最早期平台研发了第一版本的缓存方案作作为过渡。该方法能够一定程度缓解存储的压力,但是其对于数据的管理还是不够自动化,这只能作为我们过渡到新架构的一个临时替代解决的方案。
全新的架构云知声在 2020 年开始调研 Alluxio并进行了一系列的测试,包括功能的适配与性能测试等,发现 Alluxio 能够满足目前云知声需求,能够较为快速并且以较低的成本解决我们存在的几个痛点:
- Alluxio Fuse 提供了 POSIX 文件系统接口,用户能够无缝的使用分布式缓存,程序无需做更改;
- Alluxio 支持对多种文件系统的支持,包括分布式文件系统、对象存储等,当我们平台后续引入新的存储,Alluxio 缓存都能很好的进行支持,保证我们整个缓存架构的稳定性;
- Alluxio 提供较好的缓存管理,Alluxio 的层次化存储机制能够充分利用内存、固态硬盘或者磁盘,降低具有弹性扩张特性的数据驱动型应用的成本开销;
- 支持以 Kubernetes 或者容器的方式部署到平台中,与现有的技术栈较为一致;
- Alluxio 提供了 HA 支持,保证了分布式缓存系统的高可用性。
相比早前的计算与存储分离的架构,Alluxio 在计算与存储之间引入一层 Cache 层,将底层存储的压力转移到各个计算节点的内存或者本地硬盘中,用户的任务能享受本地存储带来的速度提升优势,整个平台能够兼容分布式文件系统与本地硬盘两者的优势。
在使用 Alluxio 进行业务端整合时,我们遇到了权限控制、以及数据挂载等问题。Fluid 提供了一种更加云原生的方式来使用 Alluxio, 其提供了一种全新的数据集管理方式,缓存数据集跟云原生的资源一样,能够被 kubernetes 进行相应的分配与调度,有效的解决早期缓存与 kubernetes 使用方式独立的问题。
最终我们的架构是使用 Alluxio 作为 Fluid 的缓存加速引擎,其负责做底层分布式文件系统到计算节点本地缓存介质的数据迁移以及缓存的管理,为平台的应用程序提供了数据加速的功能。而 Fluid 负责缓存与应用的编排,基于 Fluid,平台能够感知缓存,将之前需要很多人工的缓存操作,转移到平台层智能化处理。
引入新架构后,我们在自研的模型训练任务提交工具 atlasctl 将 fluid 功能进行集成,尽可能的为用户屏蔽一些复杂的概念,用户通过 atlasctl cache create 并指定添加一些参数信息例如缓存的大小,缓存介质等即可创建缓存数据集。该工具的集成为用户屏蔽了负载的缓存机制信息,让他们更加关注与数据与业务本身。
业务适配Fluid Alluxio 为集群引入了全新的架构,但是在具体场景适配方面我们还是遇到了一些问题,这些问题我们第一时间与社区反馈,社区都第一时间解决了我们的需求,这里主要讲下几个比较重要的特性支持:
hostpath 与 nonroot 的支持
在 Atlas 平台中,我们对分布式文件系统设置了 nonroot,客户端的 root 是没有权限操作用户的目录的。如果在 Alluxio 缓存引擎使用 root 用户访问底层 UFS 会出现权限问题,Fluid 还提供了 nonroot 支持,支持在缓存引擎与数据集分别设置用户的 UID 与 GID,缓存引擎的用户信息保证 Allluxio 能够成功读取到底层 UFS 的数据,如果用户在数据集设置相同的 UID 与 GID 就可以实现任务端数据的读取,如果将数据集的 UID 与 GID 设置成别的用户信息,就可以实现数据集的共享,该特性很好的解决了平台遇到的权限控制相关的问题以及数据存储冗余的问题。
多个挂载点的支持
由于用户的任务的数据通常是由不同的数据集组成,这里的不同数据集可以是同一个存储系统的不同目录或者是不同存储系统。Alluxio 能够为应用程序提供统一命名空间。通过统一命名空间的抽象,应用程序可以通过统一命名空间和接口来访问多个独立的存储系统。相比于连接每个独立的存储系统进行通信,应用程序可以只连接到 Alluxio ,通过 Alluxiofuse 让用户能够使用 POXIS 接口访问不同底层存储的缓存数据。
透明命名机制保证了Alluxio和底层存储系统命名空间身份一致性。不同的底层存储的目录与文件名都能够在 Alluxio 进行映射。
基于该特性用户的可以同时在同一个训练任务中为 2 个存储系统的数据进行缓存加速。该特性能够避免用户进行大量的数据迁移工作,在 Atlas 平台中,TB 量级的小文件的压缩打包、迁移与解压需要耗费几个小时,运用该特性用户只需要更改下任务中数据的存储路径无需修改源代码,即可运行程序。

缓存预热
平台中计算资源往往比存储资源更紧缺,如果用户启动了 TB 量级的小文件训练任务,底层存储系统与缓存系统之间的元数据同步以及数据的同步需要耗费大量时间。Alluxio 提供了 loadMetadata 与 loaddata 的功能,Fluid 将 2 个功能进行了集成,用户能够提前将远程存储系统中的数据拉取到靠近计算结点的分布式缓存引擎中,使得消费该数据集的应用能够在首次运行时即可享受到缓存带来的加速效果。该功能能够有效的增加集群的 GPU 利用率,避免在首次缓存时进行元数据同步的时候,造成的耗时,使得程序一开始运行就具有较好的 IO 读取速度,整体的 GPU 利用率上升了。
参数调优
Alluxio 提供了较多的调优参数,平台根据业务的特点进行相应的参数配置与调优,针对几乎全是读的场景,进行了一些通用参数的调优以及一些针对不同数据集的调优。
通用参数:
- 打开 kernel_cache 以及将 alluxio.user.metadata.cache.enabled 设置为 true, 在客户端开启文件及目录元数据缓存。对于全读的场景可以配置 alluxio.user.metadata.cache.max.size 和 alluxio.user.metadata.cache.expiration.time以调整最多缓存文件及目录元数据缓存量和有效时间。
- 通过设置 alluxio.user.file.passive.cache.enabled=false 与 alluxio.user.file.readtype.default=CACHE 来避免频繁逐出(Cache Eviction)造成缓存抖动。
我们将业务按照数据集的大小分成了 3 种,第一种是小文件,单个文件的大小在 1M 以下的。第二种是中大型数据数据量在几百 G 左右的,第三种是 T 级别大文件。
语音降噪场景
本次测试的模型是基于 Pytorch 框架搭建的 DLSE 模型,数据文件数在 50 万左右 ,数据总大小是 183 GB,采用内存作为 Alluxio 的缓存介质。
本次实验采用单机10卡的任务,基于 Pytorch 原生的 DDP 框架进行多卡的通信,对比测试了直接从分布式文件系统、从 Alluxio 缓存读取以及进行一轮预热之后再从 Alluxio 的实验。
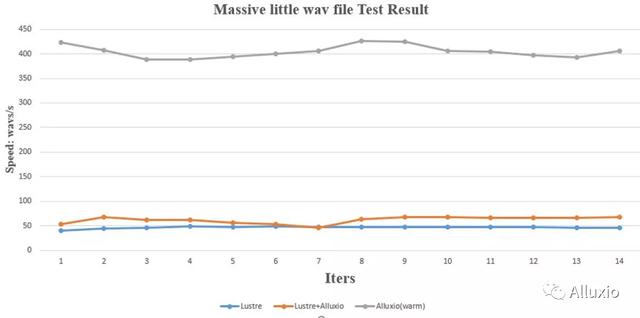
通过第一轮的时间可以看出,进行了 warmup 的缓存任务相比于直接从底层文件系统读取或者 Alluxio 的第一轮读取速度有了接近 10 倍的提速。Alluxio 在第一轮训练的时候由于数据需要做元数据同步与缓存数据,因此在第一轮数据读取的时候缓存的优势还体现不出来。但是当第二轮读取的时候,由于数据已经全部落入缓存介质中,这时候考验的就是 Alluxio 本身的缓存命中率,通过上面的实验结果也可以看出,增速非常明显。

数据读取效率提升之后,整体 GPU 利用率也得到了提升,通过监控 GPU 的利用率发现采用 WarmUp 的 Alluxio 缓存,GPU 的利用率基本稳定在 90% 左右,同时我们看到数据缓存在内存中能够有效的降低底层存储的负载。
文字识别本次实验采用基于 CRNN 的文字识别模型,采用 Pytorch 的框架进行模型的构建,数据源采用的是自采集的 125GB 的图像数据,图像数据转换成了一个 lmdb 的大文件,我们做了3 个对比测试,直接从底层文件系统读取、从没有进行预热的 Alluxio 读取以及采用进行了预热的 Alluxio 读取。

我们发现采用预热的 Alluxio 节点的 IO 带宽流量相比于直接从底层分布式存储读取从 1300Mb/s 降为基本为0,对于我们的平台收益是非常大的,在不增加底层存储硬件的情况下,这是最快而且相对廉价的降低存储系统带宽使用的方法。

读取缓存相对于直接读取底层存储计算节点 GPU平均使用率由 69.59% 提升到 91.46%,表明消除 I/O 瓶颈可以提高大文件训练任务资源使用效率。
结论通过引入 Fluid Alluxio 的新架构,平台取得了一系列的收益。
- 加速模型训练:通过上述的测试结果我们看到对于任务的提速效果非常明显,能够直接利用本地存储的速度优势避免因为网络传输与资源竞争,从而有效的加速模型训练过程中数据读取的耗时。
- 降低底层存储负载:新架构可以通过本地缓存分担底层存储系统的带宽与 IOPS 压力,大幅度减少底层存储系统的负载,有效的提高了底层存储系统的可用性。
- 增加集群 GPU 利用率:通过高效的 IO 读取,消除用户程序数据读取的瓶颈, 避免了 GPU 空转等待数据的现象,提高了 GPU 的利用率,从而提高了整个集群 GPU 使用率。
- 避免同节点 IO 竞争:新架构充分解决了我们早期遇到的同节点 IO 资源竞争、存储系统存在带宽瓶颈以及模型的训练效率不高的痛点。更加高效的缓存管理:采用新架构以一种更加云原生的方式管理缓存,工程师从之前单纯将数据载内存到现在缓存转变成可以管理与监控的资源,Kubernetes 调度能够感知缓存,进行相应的策略分配,使得任务能够更加高效的运行。
Fluid Alluxio 为我们带来了很大的收益,目前我们也跟社区紧密持续合作中,后续我们将在以下几个方面继续深入研究:
- 持续反馈测试结果与问题以及提供更丰富的使用场景给社区,不断的迭代优化 Alluxio 的性能;
- 总结与测试更多的数据类型,提供参数调优实践反馈给社区;
- 增加 fluid 缓存智能化调度功能。
本文作者:
吕冬冬:云知声超算平台架构师, 负责大规模分布式机器学习平台架构设计与功能研发,负责深度学习算法应用的优化与 AI 模型加速。研究领域包括高性能计算、分布式文件存储、分布式缓存等。有多年的云原生开源社区经验。
刘青松:云知声算法研究员,负责机器学习平台和应用算法研发,研究领域包括云原生架构研究、高性能计算、语音和视觉应用、机器学习算法等。
原文链接:http://click.aliyun.com/m/1000322281/
本文为阿里云原创内容,未经允许不得转载。
,




