关系型数据库,是指采用了关系模型来组织数据的数据库,其以行和列的形式存储数据,类似excel
1.1.2 OLAP 和 OLTPOLTP(Online transactionprocessing):在线/联机 事务 处理。主要是对数据库中的数据进行增删改查
OLAP(Online analyticalprocessing):指联机 分析 处理。通过分析数据库中的数据来得出一些结论性的东西
OLTP查询一般仅涉及单表,点查为主,返回的是记录本身或该记录的多个列。
OLAP则不同,表中单条记录本身并不是查询所关心的
1.1.3 事务多个操作同时进行,那么同时成功,那么同时失败。这就是事务。
1.2 innodb 存储结构InnoDB将数据划分为若干页,每个页默认大小16KB。
页是磁盘和内存交互的基本单位,每次IO最少读取16KB的内容到内存。也就是说,IO的基本单位是页。一个页中可以存储多个行记录。
页之间可以不在物理结构上相连,通过双向链表相关联。页内的记录按主键大小排序构成单向链表。

行->页->区->段->表空间
区在文件系统中是连续分配的空间,一个区等于64个页,大小:64*16K=1MB
段中不要求区之间是相邻的,不同类型的数据库对象以不同段的形式存在。例如数据表段(叶子结点)、索引段(非叶子节点段)。
表空间本质上就是一个存放各种页的页面池,数据库由多个表空间组成,空间可划分为系统表空间(只有一个,额外记录系统信息)、用户表空间、临时表空间等。
如果你想让每一个数据库表都有一个单独的表空间文件的话,可以通过参数innodb_file_per_table = ON设置。
1.3 物理文件1.3.1日志文件1. 错误日志文件(error log):记录的是MySQL异常,或则MySQL链接有误
2. 二进制日志(binarg log):用于数据恢复、数据库的主从配置
3. 事务日志(rado undo log):事务的开启会存储到rado log日志以及撤销日志 undo log,稍后会刷入磁盘中
4. 慢查询日志(slow query log):可用于查询项目中的哪些sql语句查询较慢。
5. 查询日志(query log):用于查询缓慢的语句日志
1.3.2 数据库文件1. .frm文件:(MySQL表的引擎是MyISAM的,存储的是该引擎的创建表或则其他操作的语句)。
2. .myd文件:(MySQL表的引擎是MyISAM的,存储的是该引擎的所有数据)。
3. .myi文件:(MySQL表的引擎是MyISAM的,存储的是该引擎的所有索引)。
4. .ibd和ibdata文件:(MySQL表的引擎是innodb的,存储的是该引擎的索引以及数据)。
注:每个存储引擎都有自己的文件夹保存各种数据,这些存储引擎真正存储了数据和索引等数据
直观感受下

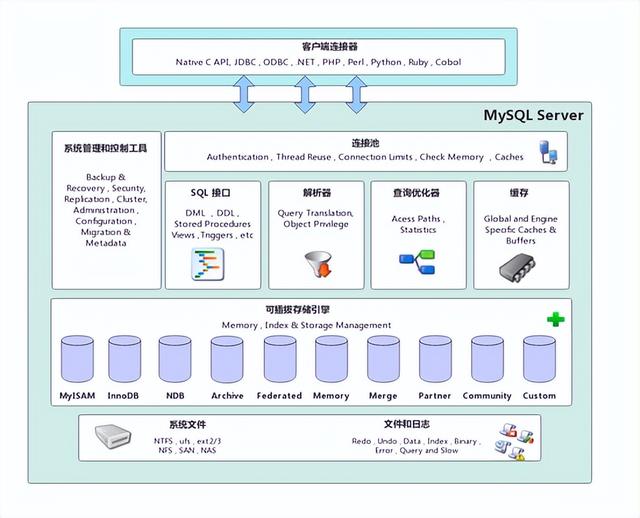
- 网络连接层位于整个MySQL体系架构的最上层,主要担任客户端连接器的角色
- 连接池主要负责存储和管理客户端与数据库的连接信息,连接池里的一个线程负责管理一个客户端到数据库的连接信息。
- 数据库服务层是整个数据库服务器的核心,主要包括了系统管理和控制工具、连接池、SQL接口、解析器、查询优化器和缓存等部分。
- 系统文件层主要包括MySQL中存储数据的底层文件,与上层的存储引擎进行交互,是文件的物理存储层。
- MySQL中的存储引擎层主要负责数据的写入和读取,与底层的文件进行交互,MySQL中的存储引擎是插件式的,服务器中的查询执行引擎通过相关的接口与存储引擎进行通信,同时,接口屏蔽了不同存储引擎之间的差异。MySQL中,最常用的存储引擎就是InnoDB和MyISAM。
创建数据库:
CREATE DATABASE [IF NOT exists] mydb1;
删除数据库:
DROP DATABASE [IF EXISTS] mydb1;
create table 表名(
字段1 字段1类型 [comment 字段1注释],
字段2 字段2类型 [comment 字段2注释],
字段3 字段3类型 [comment 字段3注释],
......
字段n 字段n类型 [comment 字段n注释]
)[comment 表注释];
alter table 表名 add 字段名 类型(长度) [comment 字段注释] [约束]
alter table 表名 drop 字段名;
truncate table 表名; #删除指定表,并重新创建该表
drop table [if exists] 表名; #删除数据表
1、index 普通索引(最基本的索引,没有任何限制)
alter table table_name add index index_name(column)
2、primary key 主键索引(是一种特殊的唯一索引,不允许有空值)
alter table table_name add primary key(column)
3、unique 唯一索引(与“普通索引”类似,不同的就是,索引列的值必须是唯一,但允许有空值)
alter table table_name add unique(column)
4、filltext 全文索引(仅可用于MyISAM表)
alter table table_name add fulltext(column)
5、组合索引(遵循“最左前缀”原则)
alter table table_name add index index_name(column1,column2,column3)
视图(view)是一种虚拟存在的表,是一个逻辑表,本身并不包含数据。作为一个select语句保存在数据字典中的。
CREATE VIEW <视图名> AS <SELECT语句>
ALTER VIEW <视图名> AS <SELECT语句>
DROP VIEW <视图名1> [ , <视图名2> …]
一般不使用,不好管理
2.1.5 存储过程:x:存储过就是数据库SQL与层层面的代码封装与重用

DROP PROCEDURE [ IF EXISTS ] <过程名>
不建议使用,不好管理sql
tips:可以使用工具生成的语句,然后操作。2.2 DML 操作数据️2.2.1 insert 添加数据
INSERT INTO `grade`(`gradeid`,`gradename`) VALUES('11114','大七')
UPDATE table_name SET column1 = value1, column2 = value2 WHERE condition;
DELETE FROM table_name WHERE condition;
执行顺序: from where 聚合 having order limit
1、from 先做表连接
2、where 进行条件限制
3、然后做聚合 group by
4、然后做 having 过滤
5、然后对结果进行排序
6、最后限制数量 limit
- 按数据结构分类:B tree索引、hash索引、Full-text索引。
- 按物理存储分类:聚集索引、非聚集索引(也叫二级索引、辅助索引)。
- 按字段特性分类:主键索引(PRIMARY KEY)、唯一索引(UNIQUE)、普通索引(INDEX)、全文索引(FULLTEXT)。
- 按字段个数分类:单列索引、联合索引(也叫复合索引、组合索引)。

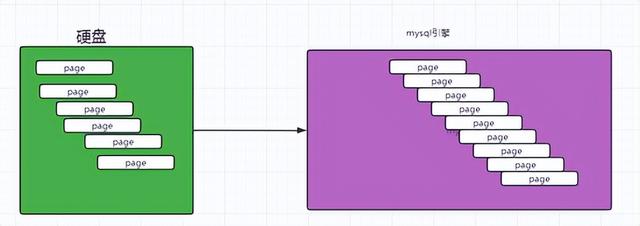
页是mysql innodb存储的最基本结构,也是Innodb磁盘管理的最小单位。
mysql的文件系统在从硬盘加载数据的时候,会以页为单位进行加载,在内存中也是以页为单位进行调度。
在mysql中默认的page_size 是 16K
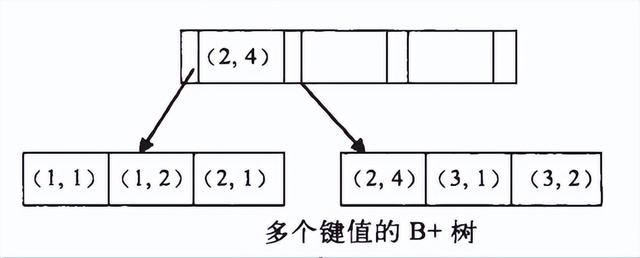
B 树是mysql innodb 的索引数据结构,先看下数据的存储

解释下上面这张图
蓝色的表示数据指针,也就是索引列的值,
红色的表示数据页的地址。
可以看到上面这张图除叶子节点(粉色框的)外存储的数据都是索引列的值
同时所有的叶子节点做了一个指针指向。
- 查询用不到的字段不需要创建索引。
- 数据量小的表最好不要使用索引,如果表中记录太少,比如少于1000个,那么是不需要创建索引的。表记录太少,是否创建索引对查询效率的影响并不大。
- 有大量重复数据的列上不要建立索引
- 在条件表达式中经常用到的不同值较多的列上建立索引,但字段中如果有大量重复数据,也不用创建索引。比如在学生表中的性别字段上只有男和女两个不同的值,因此无须建立索引。如果建立索引,不但不会提高查询效率,反而会严重降低数据更新速度。
- 避免对经常更新的表创建过多的索引。因为更新数据的时候,也需要更新索引,如果索引太多,在更新索引的时候会造成负担,从而影响效率。虽然提高了查询速度,同时却会降低更新 表的速度。
- 不建议使用无序的值作为索引,例如身份证、uuid(在索引比较时需要转为ASCII,并且插入时可能会造成页分裂,这些了解即可)、md5、hash、无序字符串等。
- 删除不再使用或者很少使用的索引,从而减少索引对更新操作的影响。
- 最佳左前缀法则
- 数据类型不匹配,导致索引失效
- 不等于(!= 或者<>)导致索引失效
- like以通配符%开头索引失效
- 联合查询时,字符集不匹配导致索引失效
- where中索引列使用了函数或者运算

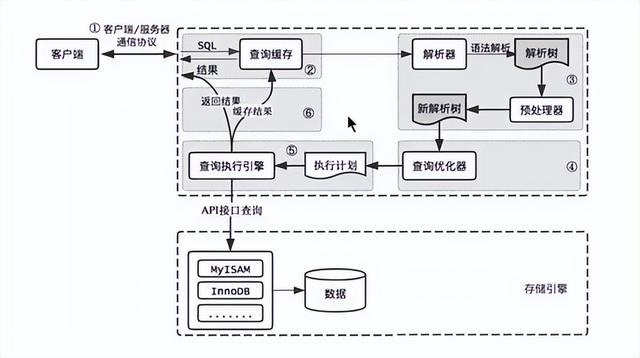
- 查询的生命周期
客户端 -> 服务器查询缓存 -> 解析器 -> 预处理器 -> 查询优化器-> 查询执行引擎 -> 存储引擎 -> 数据
尽量命中缓存,尽量少读数据,尽量少查数据。
- 小表驱动大表
执行 from 后的表关联查询是从左往右执行的,第一张表会涉及到全表扫描,所以将小表放在前面,先扫小表,扫描快效率较高,在扫描后面的大表,或许只扫描大表的前100行就符合返回条件并return了。

- 删除大量数据时表先删除索引,后删除数据,再重建索引,使用truncate代替delete
- 根据业务需要设计表,动静分离,减少冗余,可适当冗余
- 进入docker容器
进入容器
docker exec -it 02d894edba22 bash
连接数据库
mysql -uroot -p123456
选择数据库
show databases;
切换到具体数据库
use ccp_device;
执行sql
select * from device_info limit 10;

原文链接:https://blog.csdn.net/perfect2011/article/details/127051926?utm_source=tuicool&utm_medium=referral
,




