承接上文神经网络基础篇二
sigmoid函数计算梯度的问题
最早的神经网络就是用Sigmoid计算梯度的

sigmoid激活函数每一点的梯度都可以计算,但问题就是随着x变大或变小,梯度约等于0,导致梯度不进行更新,不进行传播。
x w1 w2 w3 w4
反向传播计算w3的梯度,如果梯w3的梯度为0,就会导致w2和w1的梯度为0。
这就是sigmoid函数带来的问题,一旦数值较大或较小,会发生梯度消失的现象。
由于个别层的影响使得梯度最后计算完之后,变成了0,因为它是一个乘法的操作,计算到某一层的梯度为0,后面就不会更新了。
改进
Relu函数借鉴了Max函数,90%都使用这个激活函数。
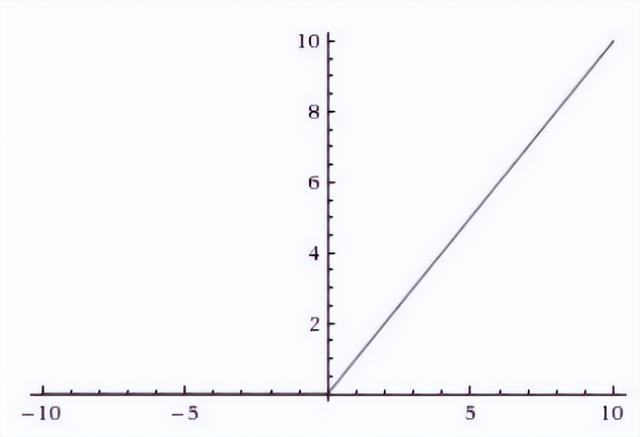
小于0都等于0,大于0都等于x本身,梯度为1,不会出现梯度消失即不会变成0。
数据预处理
不同的预处理效果会使得模型的效果发生很大的差异!

拿到数据之后,不能直接输入到神经网络当中,得稍微的做一些变换,比如做一些标准化操作。
在标准化操作当中,第一步就是把这个地方变成中心化即每个地方的实际坐标值减去均值就可以了,得到了以圆点为中心对称的结果,接下来进行各种维度的放缩或扩充即除上标准差就可以了,这就是数据的标准化。所有的数据问题都会涉及到数据预处理操作,这是一个比较常见的标准化操作。
参数初始化
参数初始化同样非常重要,通常我们都使用随机策略来进行参数初始化。

比如有一只猫的图片数据,经过一个3x4(即D=3,H=4)的权重参数矩阵变换,对3x4的权重参数矩阵进行初始化,先随机生成初始化参数,然后在数据训练的过程中,反向传播重新计算参数值。
不能让权重参数矩阵中的不同的权重参数值差异过大,比如有些w很大,大部分w都很小,希望它尽可能稳定一些,当把初始化后的值乘以0.01,得到的值就都会很小。
Drop Out

整个网络架构中层数比较多,每一层神经元个数也比较多,就会使得整个神经网络过拟合风险比较高。
上图是全连接的神经网络,每一个神经元都和其他神经元全连在一起,只用其中一部分行不行?

在神经网络训练过程中,每一层随机的杀死一部分神经元。每一层画叉的神经元就表示这次前向传播、反向传播就不带画叉的神经元玩了。更新权重参数,这些画叉的神经元保持原来的参数不变,不参与。每层画叉的神经元是随机被选中的,只是这次训练不使用,并不是永远不用。梯度下降算法要迭代很多次,迭代10万次或100万次都有可能,每次训练的时候随机“杀死”部分神经元,训练的网络架构就会简单些,防止网络模型太复杂。
drop-out是一个比例,比如50%,在训练的过程中,每次有50%的神经元是不参与这次训练的,只训练剩下的50%。
小结

- 前向传播
对数据先进行预处理,比如文本数据去一些停用词,图像数据做一些标准化操作等。预处理完之后,得到输入层,往神经网络中输入数据的3个特征x1,x2,x3,输入层和隐藏层就是一组权重参数矩阵连接起来的,w1是3x4的权重参数矩阵,表示左边连接3个,左边连接4个,再对中间层做不限制的特征提取,比如做个8层、10层。最后一组权重参数就是要得到的最终输出结果。隐藏层做完之后,再用激活函数做下变换,一般用relu函数,这就是前向传播的过程。最后用输出的结果,计算loss值。
- 反向传播用loss值对w3求偏导,计算w3对最终的结果有什么样的影响。再对relu激活函数求偏导,只不过它不更新值。然后再对w2求偏导,再对relu函数求偏导,不更新值,再做w1求偏导,这个过程就是反向传播。
整个神经网络就围绕一件事情去做的:什么样的权重参数最适合于当前的这个任务。神经网络做完之后,99%都会过拟合,一旦过拟合了,就需要想什么样的解决方案是最合适的,一种方式就是加上正则化惩罚项。
计算机视觉CV领域的发展

这个是imagenet图像分类的错误率,y轴是错误率。10,11年使用的是传统的机器学习算法,12年开始使用深度学习。Human表示人类用肉眼识别的错误率,大概5%,16年用深度学习网络达到的错误率已经远低于人类了。
计算机视觉领域的任务用深度学习算法做的比较多。
卷积神经网络能够想到的传统的计算机视觉任务或者说以后可能出现的,全部都可以由卷积神经网络CNN来做。比如常见的检测任务,在图片或视屏当中进行检测或追踪现在做的都已经比较好了,之前的准确率可能没有那么高,卷积神经网络来了之后,准确率已经比较高了。
分类与检索

分类就是最传统的计算机视觉任务,这张图片是什么。检索是输入一张图片返回相似的结果。比如淘宝中,看中一个商品,可能不知道它的名字叫什么,不知道它具体的型号,把它拍照下来,进行拍照的搜索,就会返回一些同款,这个就是检索,也可以用神经网络来做。
判断这张图片是什么,然后在当前这个领域中哪些商品跟它的相似度是比较高的。神经网络和卷积神经网络都是用来做特征提取的。比如有了A和B特征,都是一个300维的向量,就可以去计算相似度。所以核心一点就是怎样做特征提取。
传统的神经网络在特征提取上有一些问题,比如权重参数矩阵特别大:一张图片784个像素点,隐层有128个神经元,那么中间的矩阵就是784x128,训练花的时间就会比较多,过拟合的风险也挺高。
卷积神经网络在图像数据(视屏也是一张张图片组成的)上一定程度解决了该问题。
卷积神经网络的应用
- 超分辨率重构
- 输入数据是一张模糊的图片,可以训练这个卷积神经网络,让这个网络学习下,怎么样能够重构这张图像,怎么样能把这张图像做的更清晰一些。
- 医学任务等

现在计算机视觉和医学结合的比较多了,比如做一些细胞检测、人体透视图、动态图结果的分析;OCR字体识别;停车场进出自动抬杆;车牌的识别;标志的识别等。所有任务但凡和图像搭上边的,都能用神经网络或卷积神经网络实现出来。
- 无人驾驶
- 开车的过程中,车有摄像头,摄像头拍出来的图像数据,就是由卷积神经网络去做的。
- 上图右侧部分是一个显卡。CPU可以跑神经网络,GPU(图像处理单元)也能去跑,印象中GPU是玩游戏的,游戏中处理的就是一桢一桢的图像数据,如果完游戏比较卡,说明这张图像和下一张图像连接不连贯,因为处理的速度太慢了,所以会觉着卡。在卷积神经网络当中最好也能有显卡,卷积神经网络无非就是做卷积,做全连接等各种各样的运算,GPU在处理这些运算的效率要比CPU快100倍以上。所以实际项目中都是用GPU来跑的卷积神经网络。
- 人脸识别
提取脸部关键点特征,分析判断是否是一个人或者判断这个人是谁。
卷积神经网络和传统网络的区别

上图左侧是传统的神经网络NN,上图右侧是卷积神经网络CNN。左侧看起来像二维的,右侧看起来像三维的。
传统网络输入层说784,这是表示784个像素点,这个只是一列特征。而卷积神经网络不是输入784个像素点,而是输入的是一张原始的图片,比如28x28x1,这是三维的,不是一列,不是一个向量,不是一个特征,而是一个长方体矩阵,三维的(h * w * c),所以接下来处理的数据都是三维的。不会先把数据拉成一个向量,而是直接对这个样本就是图像数据进行特征提取。
卷积神经网络的整体架构

输入层比如输入一张28x28x3的图像数据;卷积层是提取特征;池化层是压缩特征;全连接层就是通过一组权重参数比如784x50把输入层和隐层连接在一起。输出层是每个类别的概率值,比如猫的概率0.82,狗的概率0.56。
卷积到底做了什么事情
输入数据是一张32x32x3的猫的图像数据,它边界的特征和它中间眼睛的特征以及它嘴的特征,肯定不同,对不同的区域提取出来不同的特征,得知道一点,它在边界的特征没有那么重要,它的眼睛特征很重要,胡须特征也很重要,把一张图像分成了不同的好多部分,不同的地方要区别进行处理。
在做卷积的过程当中,需要先把图像进行一个分割,来分割成很多的小块。
每一小块它不是一个像素点,一个眼睛可能是一个小区域,一个小区域它可能是由多个像素点组成的。

比如1这小块假设是3x3x3的区域,对1号区域进行特征提取,选一个特征,再对2号区域选一个特征,再对3号区域选一个特征。
怎么才能再上图深蓝色区域(3x3x3区域)选择出来它的一个特征值?
在神经网络当中用一组权重参数达到一个特征值,在卷积神经网络中也是一样用一组权重参数得到的。
首先看第一个3x3的区域,下图左上角深色部分,其中的332 001 312是输入数据,012 220 012是权重参数,要找的还是最好的这组权重参数矩阵,使得特征提取完之后,效果能够做好。

正常情况下它是一个3x3x3 三维的数据,三维的不好画,先画一个一维度的了解其原理。
在这个区域选择一个特征,得到绿色特征图中的第一个特征值12.0,表示当前这个3x3的区域,它的代表值就是12。然后再往右移动一个单元格,

再在这个区域选择一个特征,得到绿色特征图中的第二个特征值12.0,依次类推,就可以得到这样的一个特征图。

一开始是3x3的原始输入数据,经过一次卷积完之后,得到了一个特征图,特征图中的值就是当前得到的一个结果了。
卷积的过程首先把一张图像分割成每个小区域,不同的区域得到的特征值是不同的,然后通过一个计算方法计算每个区域对应的特征值是多少。
图像颜色通道

常见的颜色通道是3颜色通道(RGB),32x32x3 这个3就表示3颜色通道(RGB),3分成了上图的右侧3个部分,分别是R、G、B,实际当在做计算的过程中,要每个颜色通道分别计算,R通道单独计算,G通道单独计算,B通道单独计算,最终再把每个通道卷积计算的结果加到一起就可以了。

上图右侧部分红、绿、蓝分别表示RGB三个颜色通道。
比如R通道计算完的结果是1,G通道计算完之后的结果是3,B通道计算完之后的结果是2,最终结果就是1 2 3=6。
上面演示的对一个小区域提取特征值的过程是一个颜色通道的,实际上需要3个通道分别去计算的。

上图只是画了2个颜色通道R、B,对每一个立体区域进行特征提取,得到最终的一个特征值。
接下来再详细说下整个卷积的过程

输入数据是7x7x3(h w c)的数据,通道数就是第三个维度c(channel),每个颜色通道的大小都是7x7,3个颜色通道的维度都是一样的,它们合在一起就是7x7x3的输入数据,然后分区域对当前的输入数据进行特征提取。
filter w0 先随机初始化一组权重参数矩阵,filter中的第三个维度必须是3和输入数据的第三个维度必须是一致的。3x3就是一个卷积核大小,表示在原始数据中每3x3的小区域进行一个特征选择。filter中的前两个h和w表示在原始图像区域中每多大的区域选择一个特征即多大的区域对应一个值。
在filter wo分别对R、G、B进行计算,每个通道里面的权重参数值都是不同的,所以要区分对待不同的一个输入数据即同一份输入数据当中不同的部分。
所有的卷积网络中都是用的内积做的计算即对应位置相乘,结果相加。
比如上图R通道的值是怎么计算的:

原属数据中像素点为0的位置就忽略,因为0乘以任何数都为0。那么就剩下四个1的位置,每个对应位置上的2个值相乘,然后再相加即1x(-1) 1x0 1x1 1x0=0
同理G通道的计算结果为2,B通道的计算结果为0,3个通道的结果相加就为2,这个就是filter w0内积计算的结果,一个特征提取的值。再加上一个偏置项b(图中给小b初始化的值为1),所以最终结果为3,即图中绿色圈中的部分3。在原始图中第一个小区域3x3,3个颜色通道,这样的一个区域对应的特征值为3。
特征图的个数

filter w0得到一个特征图,filter w1对应一个特征图,所以这里有2个特征图,相当于2中不同的特征提取方法,得到两种不同的结果。

w0和w1的规格相同,都是3x3的。
输出的结果是3x3x2的,2表示深度即特征图的个数,filter w0生成一个特征图,filter w1生成一个特征图。
对于同样的输入数据来说,可以多粒度的进行特征提取,不光要用一个filter,一个卷积核进行特征提取,可以用很多个卷积核进行特征提取,f1,f2,f3....f100,选择不同的矩阵,得到的特征结果是不同的,那就可以让特征更丰富起来了。

上图有6个不同的特征图,每个都是28x28x1的,把每个特征图堆叠在一起即28x28x6,相当于得到了一个比较丰富的特征。
以上只是对一个区域做了一次卷积的过程,还有第二个区域,第三个区域.....
第一个区域做完之后,往右平移了2个单元格,

计算方式都是一样的。
滑动完所有的单元格之后,那也就计算完了。
卷积完之后,得到特征图,就算提取出了一个特征。

原始的输入比如一张图片,第一步low-level fetaure,这个只是一个形象的解释,实际并没有高低之分,一开始先粗粒度的提取下大致的特征,然后在细粒度的提取出来一些中间特征,最后再提取处一些组成起来的高级特征,然后把高级特征去做分类,它其实在说这样一个事情: 一张输入数据来了之后,做一次卷积是不够的,而是需要做好多次卷积。除了第一次卷积,每次的卷积都是在前一次卷积得到的特征图的基础之前做的。

首先开始输入一张32x32x3的图像数据,做了一次卷积之后,得到特征图,特征图也是三维的hwc,hw是特征图的大小,c是有多少个特征图。
上图第一个卷积层,用了6个不同的filter即6个不同的卷积核,那得到的特征图的深度是6

这个是一个特征图,特征图中有6个不同的图叠加在一起。
相当于在原始图像上卷积一次得到一个中间特征,再在中间特征上做卷积,相当于对特征做了进一步的特征提取,所以卷积是一步一步去做的。
第二次卷积,卷积核是5x5x6,前一个卷积核是5x5x3,卷积核的第三个值一定和前一个输入是一致的。
用10个不同的filter来执行这样一次卷积,执行完之后,得到一个特征图,深度是10。经过多次卷积得到的特征,才认为是比较好用的。和神经网络中,加一个隐层,再加一个隐层,道理都是一样的。卷积可以无限次的往下堆叠,但不追求无限次。
卷积层涉及到的参数
- 滑动窗口步长
- 移动窗口,可以移动的大一点,也可以移动的小一点。步长为1的卷积,在原始基础上移动了一个单元格。
- 红色窗口对应一个红色的特征值,绿色窗口对应一个绿色的特征值
步长为1的,得到的特征图是5x5的,步长为2的,得到的特征图是3x3的,对于当前任务来说,输入的数据都是一样的,能移动的窗口越多,得到的特征值越多,得到的特征图也会越大。当步长比较小的时候,慢慢的去提取特征,细粒度的去提取特征,这样得到的特征是比较丰富的。当步长比较大的时候,大刀阔斧的去提取特征,滑动比较大,得到的特征比较少,得到的特征没有那么丰富。这个就是步长对结果的影响。一般情况下,对于图像任务来说,选择步长为1就可以了,但有些任务跟图像不太一样,比如文本任务,卷积神经网络不只是做计算机视觉,文本数据以及其他数据都能用上。
比如一个文本数据,最终还想做一个分类任务,二分类,判断1或0。
文本数据:我今天去打篮球。
对于图像数据来说都是3x3x3或5x5x3,h和w都是一样的,一般情况下都是用正方形的一个大小来做卷积。
而文本任务比如1x3 表示在文本中的“我今天”这3个字,3个字提取一个特征或5个字提取一个特征,所以步长大小的设置跟具体任务相关的。
一般情况下图像任务,常用的步长为1。
步长越小,得到的特征越多,计算的效率越慢。
但在文本任务中不同的任务设置的卷积核大小可以不同,设置的步长也可以不一样,你可以2个字2个字的滑,也可以3个字3个字的滑动。
步长为3表示两个区域相同位置相距为3个词。区域大小为5表示卷积核大小为5即一个区域的长度是5。
- 卷积核尺寸
- 3x3的区域和4x4的区域,无非就是3x3的区域得到一个值,4x4的区域得到一个值,相当于选择的一个区域大小以及得到最终的结果。得到最终结果的个数也是不同的,卷积核越小说明越细粒度的进行提取,卷积核越大,越大刀阔斧,现在基本的做法卷积核为1,卷积核尺寸一般为3x3,也是常用的最小的一个尺寸。
- 边缘填充
上图蓝色区域是第一次卷积到的区域,绿色区域是第二次卷积到的区域,红色部分是第三次卷积到的区域。

粉红色椭圆圈住的区域是第一个区域和第二个区域重合(交接点)的部分。黄色椭圆圈住的区域是第二个区域和第三个区域重合的部分。
那重合部分的值比如粉红色椭圆中的一个点0

它对最终的计算结果3和-5都有贡献。
蓝色区域和绿色区域分别得到的值是3和-5,重合地方的值贡献大,对最终结果影响比较多,因为它可以影响2个地方。其他位置的值即非重合的部分,只跟filter计算了一次。有些点对计算结果天生有优势,计算又多,有些点天生没有这个优势,计算又少。什么样的点多,什么样的点少呢?越往边界的点能被利用的次数越少,越往中间的点,最终被利用的次数越多,那怎么解决这个问题呢?怎么使得边界的点能被计算的多点呢?

原本数据的大小是5x5的,就是上图紫色的点,表示原始输入就这么大,最左上角的1就是边界点,如果在这个边界外面再加一圈0,原本是边界的点就不是边界了,既然不是边界的点,那能被利用的次数就更多了,一定程度上弥补了边界信息缺失的问题、边界提取特征利用不充分的问题。这就是padding要做的事情,只加了一圈0,却使得边界特征能被充分利用,让卷积神经网络能更公平的对待边界特征。
为什么拿0做填充?
若是拿1做填充,在和filter做计算的时候,新添加进来的东西会对最终结果有影响,但是添加0呢,0乘以任何数都为0,此时相当于最外层只是添加了一个扩充,而不会对最终结果产生影响,而我们也希望所添加的内容不会对结果产生影响,所以它叫zero padding即以0为值,进行边界扩充,按自己的需求添加1圈、2圈、3圈,通常情况下添加一圈就够了。为了能整除,为了能更好的计算,自己选择填充的次数,这就是边缘填充。
文本数据也会涉及到边缘填充,比如有2个文本,一个文本有100个词,另一个文本中有120个词,两者的大小是不一样的,这是不行的,因为基本前提是输入大小必须是一样的。则在100个词的文本后面填充20个0就行了。
- 卷积核个数
最终计算的时候要得到多少个特征图,比如要得到10个特征图,那卷积核就是10。
这10个卷积核中的每个卷积核中的值都是不一样的,一开始进行随机初始化,分别进行各自参数的更新。
,