我们都知道,数据挖掘最终的目的就是建立业务模型,然后投入到实际中做一些分类或者预测的事情,但是这个模型做的好不好,我们总要评价吧?这就需要我们对建立的模型做评估,然后根据评估指标和实际的业务情况决定是否要发布这个模型,那么常用的模型评估指标有哪些呢?他们之间的联系又是什么呢?今天我们就带着这两个问题来学习模型评估的各个指标及含义。
首先,大家应该明白机器学习或者说数据挖掘通常的目的就是分类和回归(就是预测),那么我们对于评估指标也从这两个方面分,即回归评估指标和分类评估指标。
回归评估指标在前面的文章中我们讲解了线性回归算法的推导过程,从中可以看出,回归问题就是建立一个关于自变量和因变量关系的函数,通过训练数据得到回归函数中各变量前系数的一个过程。那么模型的好坏就体现到用这个建立好的函数预测得出的值与真实值的差值大小(即误差大小),如果差值越大,说明预测的越差,反之亦然。那么对于回归问题来说,都有哪些具体的误差指标呢?
- 平均绝对误差(MAE)
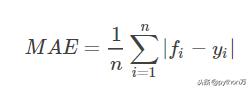
MAE
- 均方误差(MSE)

MSE
- 均方根误差(RMSE)

RMSE
可以看到,回归问题的评价指标公式比较好理解,这里不再赘述(其中f表示模型预测值,y表示真实值)。
分类评估指标相比于回归模型评价指标,分类模型的评价指标比较多且比较抽象,下面我们先看几个符号的定义,然后再来看各个指标的定义并结合例子来理解各指标的意义。
- TP:将正类预测为正类数
- FN:将正类预测为负类数
- FP:将负类预测为正类数
- TN:将负类预测为负类数
注:一般来说,我们将关注的类作为正类。
- 准确率(accuracy):对于给定的测试数据集,分类器(分类模型)正确分类的样本数与总样本数之比。
- 精确率(precision):

精确率
- 召回率(recall):

召回率
- F1值:是精确率和召回率的调和均值。

F1值
上面是关于分类问题各个指标的定义及公式,下面我们从一个例子来理解各个指标的含义。假如宠物店里有10只动物,其中6只猫和4只狗。现在将这10条数据放入一个分类器,做出分类结果如下:7只猫,3只狗。如果我们将猫看为正类,那么TP,FP,TN,FN分别为:6,0,3,1,则准确率为accuracy=(6 3)/(6 0 3 1)=90%,精确率为precision=TP/(TP FP)=6/(6 0)=1,召回率recall=TP/(TP FN)=6/(6 1)=0.86,从上面的几个指标可以看出准确率和精确率的区别,准确率是对整个样本而言,而精确率是正样本而言。而F1=(2*6)/(2*6 0 1)=12/13,由此可以看F1值是精确率和召回率的调和均值,所以在看评估指标时要综合评估,不能根据某一个值的高低评价模型的好坏,当然,在评估的时候我们还要结合实际业务。对于召回率这里在啰嗦一点,他其实就是衡量从全部的正样本中找出正样本的占比,比如上面的例子中实际有7只猫,但是分类器只找出6只,那么召回率就为6/7。他们的关系总结起来就是:宁可错杀,不可放过:低准确,高召回。宁可放过一个坏人,也绝不冤枉一个好人:高准确,低召回。
ROC曲线roc曲线是以FDR(FDR=FP/FP TN)为横轴,以TDR(TDR=TP/(TP FN))为纵轴的曲线,如果要理解这个曲线代表的含义,那我们首先必选了解横纵坐标FDR和TDR的含义,FDR代表在所有实际为负类的样本中,被错误地判断为正类的比率,TDR表示在所有实际的正类样本中,被正确的判断为正类的比率,所以说横轴的比值越小越好,纵轴越高越好,那么反应到图上就是曲线与X轴围成的面积越大越好。如下图,
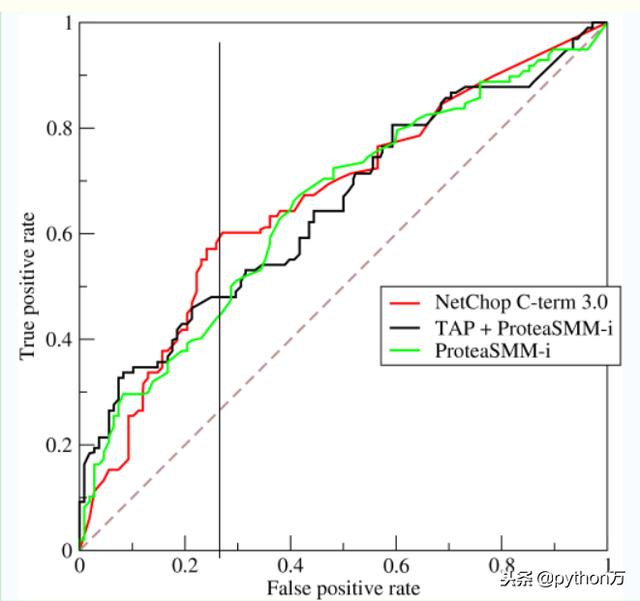
ROC曲线
好了,总结一下,本文主要讲了回归模型和分类模型的评价指标及各指标的含义,在后面模型训练过程中我们会用sklearn中的相关函数直接求得评估指标,喜欢的请点击关注!
,