准备程序:
eclipse-3.3.2(这个版本的插件只能用这个版本的eclipse)Hadoop-0.20.2-eclipse-plugin.jar (在hadoop-0.20.2/contrib/eclipse-plugin目录下)
将hadoop-0.20.2-eclipse-plugin.jar 复制到eclipse/plugins目录下,重启eclipse。
2.打开MapReduce视图Window -> Open Perspective -> Other 选择Map/Reduce,图标是个蓝色的象。
3.添加一个MapReduce环境
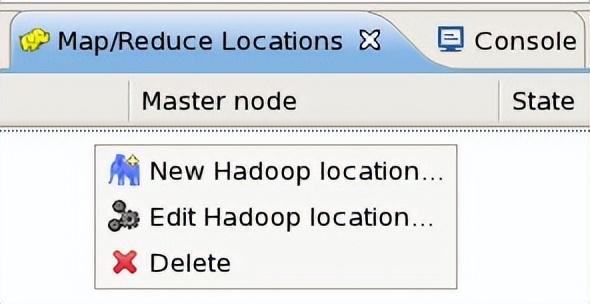
在eclipse下端,控制台旁边会多一个Tab,叫“Map/Reduce Locations”,在下面空白的地方点右键,选择“New Hadoop location...”,如图所示:
在弹出的对话框中填写如下内容:
Location name(取个名字)Map/Reduce Master(Job Tracker的IP和端口,根据mapred-site.xml中配置的mapred.job.tracker来填写)DFS Master(Name Node的IP和端口,根据core-site.xml中配置的fs.default.name来填写)
4.使用eclipse对HDFS内容进行修改
经过上一步骤,左侧“Project Explorer”中应该会出现配置好的HDFS,点击右键,可以进行新建文件夹、删除文件夹、上传文件、下载文件、删除文件等操作。
注意:每一次操作完在eclipse中不能马上显示变化,必须得刷新一下。
5.创建MapReduce工程5.1配置Hadoop路径
Window -> Preferences 选择 “Hadoop Map/Reduce”,点击“Browse...”选择Hadoop文件夹的路径。这个步骤与运行环境无关,只是在新建工程的时候能将hadoop根目录和lib目录下的所有jar包自动导入。
5.2创建工程File -> New -> Project 选择“Map/Reduce Project”,然后输入项目名称,创建项目。插件会自动把hadoop根目录和lib目录下的所有jar包导入。
5.3创建Mapper或者ReducerFile -> New -> Mapper 创建Mapper,自动继承mapred包里面的MapReduceBase并实现Mapper接口。注意:这个插件自动继承的是mapred包里旧版的类和接口,新版的Mapper得自己写。
Reducer同理。
6.在eclipse中运行WordCount程序6.1导入WordCountWordCount
6.2配置运行参数
1 import java.io.IOException; 2 import java.util.StringTokenizer; 3 4 import org.apache.hadoop.conf.Configuration; 5 import org.apache.hadoop.fs.Path; 6 import org.apache.hadoop.io.IntWritable; 7 import org.apache.hadoop.io.LongWritable; 8 import org.apache.hadoop.io.Text; 9 import org.apache.hadoop.mapreduce.Job; 10 import org.apache.hadoop.mapreduce.Mapper; 11 import org.apache.hadoop.mapreduce.Reducer; 12 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 13 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 14 15 public class WordCount { 16 public static class TokenizerMapper extends Mapper<LongWritable, Text, Text, IntWritable>{ 17 18 private final static IntWritable one = new IntWritable(1); 19 private Text word = new Text(); 20 21 public void map(LongWritable key, Text value, Context context) 22 throws IOException, InterruptedException { 23 StringTokenizer itr = new StringTokenizer(value.toString()); 24 while (itr.hasMoreTokens()) { 25 word.set(itr.nextToken()); 26 context.write(word, one); 27 } 28 } 29 } 30 31 public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> { 32 private IntWritable result = new IntWritable(); 33 34 public void reduce(Text key, Iterable<IntWritable> values, Context context) 35 throws IOException, InterruptedException { 36 int sum = 0; 37 for (IntWritable val : values) { 38 sum = val.get(); 39 } 40 result.set(sum); 41 context.write(key, result); 42 } 43 } 44 45 public static void main(String[] args) throws Exception { 46 Configuration conf = new Configuration(); 47 if (args.length != 2) { 48 System.err.println("Usage: wordcount "); 49 System.exit(2); 50 } 51 52 Job job = new Job(conf, "word count"); 53 job.setJarByClass(WordCount.class); 54 job.setMapperClass(TokenizerMapper.class); 55 job.setReducerClass(IntSumReducer.class); 56 job.setMapOutputKeyClass(Text.class); 57 job.setMapOutputValueClass(IntWritable.class); 58 job.setOutputKeyClass(Text.class); 59 job.setOutputValueClass(IntWritable.class); 60 61 FileInputFormat.addInputPath(job, new Path(args[0])); 62 FileOutputFormat.setOutputPath(job, new Path(args[1])); 63 64 System.exit(job.waitForCompletion(true) ? 0 : 1); 65 66 } 67 68 }Run As -> Open Run Dialog... 选择WordCount程序,在Arguments中配置运行参数:/mapreduce/wordcount/input /mapreduce/wordcount/output/1
分别表示HDFS下的输入目录和输出目录,其中输入目录中有几个文本文件,输出目录必须不存在。
6.3运行
Run As -> Run on Hadoop 选择之前配置好的MapReduce运行环境,点击“Finish”运行。
控制台会输出相关的运行信息。
6.4查看运行结果
在输出目录/mapreduce/wordcount/output/1中,可以看见WordCount程序的输出文件。除此之外,还可以看见一个logs文件夹,里面会有运行的日志。
,