「如何从Excel单元格中的文本值提取指定的数据出来?」
就比如做电商的同学可能经常遇到收货地址需要拆分成省市区的问题。
但是用户提交的地址信息不一定规范,就导致拆分的时候需要人工一个一个识别。
本期内容,以溪带你看看工作中常见的文本拆分与提取的案例问题。
如果有你现在正在遇到的问题,可以直接套用。
关注以溪同学,收藏加星,get更多Excel知识技能!
「案例列表」
- MID\LEFT\RIGHT文本提取函数使用
- 地址拆分省市区
- 提取指定字符-分隔的指定个数字符
- 只提取数字或者字母
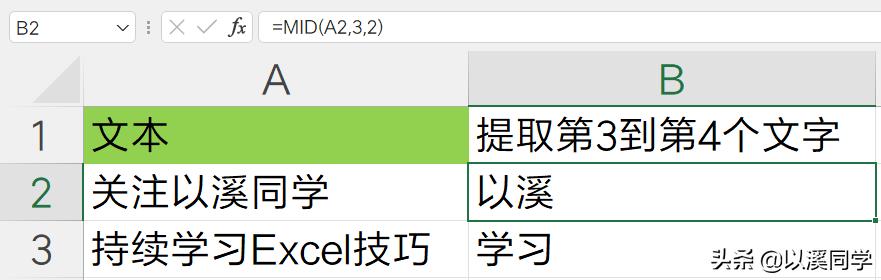
1. mid\left\right文本提取函数使用Excel中有专门的文本提取函数,其中mid、left、right分别用于从中间、左侧、右侧提取文本中的指定长度内容。
依次举例说明:
函数参数:
MID(text,start_num,num_chars)
第一个参数是待提取的文本字符串,第二个是开始提取的字符位置数,第三个参数是从文本中提取的字符数
=MID(A2,3,2)
函数参数:
LEFT(text, [num_chars])
第一个参数是待提取的文本字符串,第二个参数不填默认为1,代表提取的字符数。
=LEFT(A2,2)
函数参数:
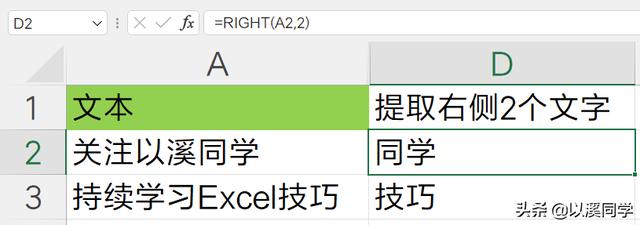
RIGHT(text, [num_chars])
第一个参数是待提取的文本字符串,第二个参数不填默认为1,代表提取的字符数。
=RIGHT(A2,2)
可以注意到,这三个参数,都有几个共同点。
要提供待提取的文本字符串。
要告诉函数从哪提取。
提取多少个字符。
理解了上面这个问题,那解决实际案例的所有「关键点」就在2、3两点上了。
2. 地址拆分如果地址数据的省市区之间有分隔符的,可以直接使用「数据-分列-按指定字符分列」即可完成拆分。
如果是像下图这种没有分隔符的地址,有两种方法可以实现拆分。
通过上面的3个函数,我们知道,想要拆分提取字符,必须要知道从哪提取,提取多少。
所以,第一步,我们需要知道在地址中,省这个字符的具体位置,以及省字符前面有多少字,就能直接提取出省这个字符串了。
在这里引入两个函数,一个是FIND,一个是len。
find函数
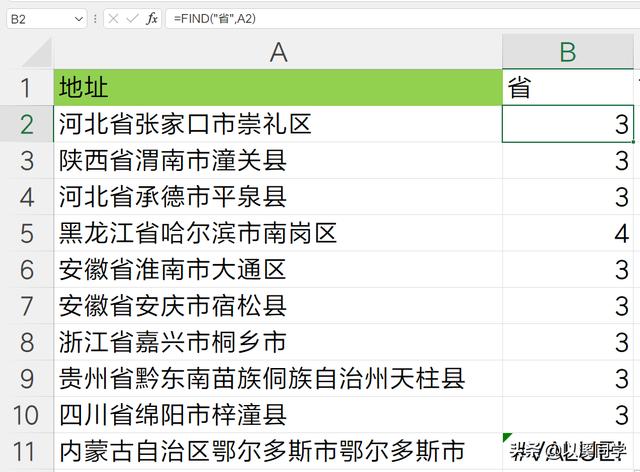
函数作用就是用于查找指定字符在字符串中的字符数位置,函数最终返回值是一个数字。 FIND(find_text,within_text,start_num)
find(要找哪个字符,在哪个字符串里找,从第几个字符位置开始找)
len函数参数
len函数用于返回指定字符串一个有多少个字符数
LEN(text)
len(文本字符串)
除了查找和统计字符数,Excel也提供findb与lenb函数,函数核心功能与find和len都一样。
唯一的区别就是,带b的函数,代表查找或计数的是字节数,反之是字符数。
其中日语、中文(简体)、中文(繁体)以及朝鲜语一个字符算2个字节数。参考下图理解,find和findb用于查找同学位于以溪123同学中的位置。
回到拆分地址上,那第一个,就是查找省这个字位于地址中的位置。
=FIND("省",A2)
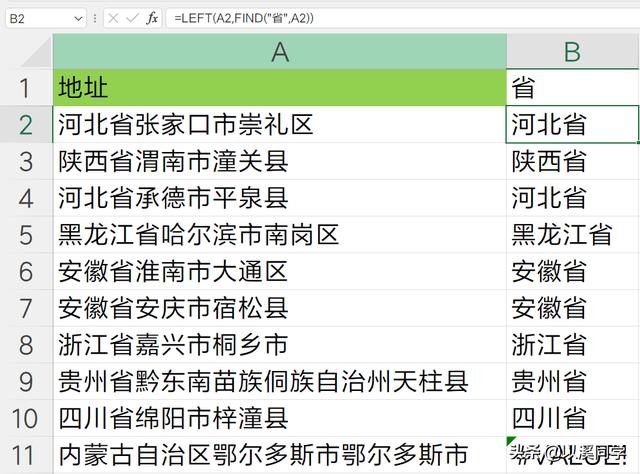
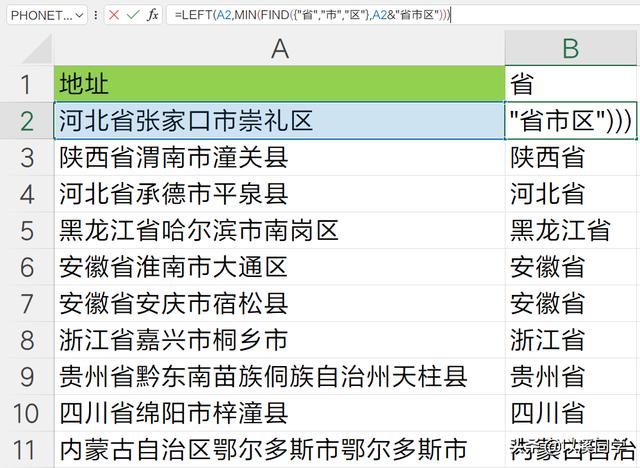
如此得到省的位置后,我们便可以通过left函数,直接提取出省名称。
=LEFT(A2,FIND("省",A2))
前面的是不是都很成功,但是最后一个自治区,就识别不出来了。
主要是我国的行政区划分,不是所有的省级行政区都是省结尾的,还包括有市、区。
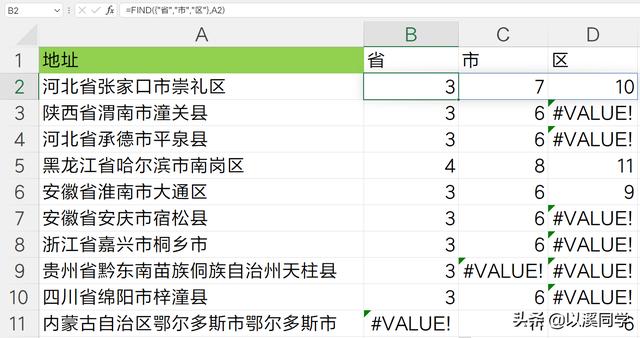
所以这里,我们需要通过数组公式,来一次性提取出省、市、区这三个字在地址中的位置。
数组公式如下:
=FIND({"省","市","区"},A2)
「注意数组公式,需要按照数组公式输入方法使用」
数组公式使用方法
需提前选中承接数组公式结果的单元格区域
再输入数组公式
最后需要按数组确认键 CTRL SHIFT 回车 确认公式
目前只是把地址中省市区出现的位置找到了,还需要对数字进行对比,最小的那个,代表最先出现,也就是省级行政单位的位置。
所以我们使用min函数对其嵌套,得到最小位置数,再使用left函数提取,就能正确获得一级行政区名称。
但是由于min函数不能统计包含#VALUE!的错误值数据,所以我们在find公式中的地址参数那里,手动拼接一个省市区字符串,使其不管怎么样,都不会返回错误值。确保min函数正确运行。
数组公式如下:
=LEFT(A2,MIN(FIND({"省","市","区"},A2&"省市区")))至此第一个省级名称,提取完毕。
如果将原地址中的省级名称去除,那么剩下的地址中,就只包含地级和县级行政区地址信息。
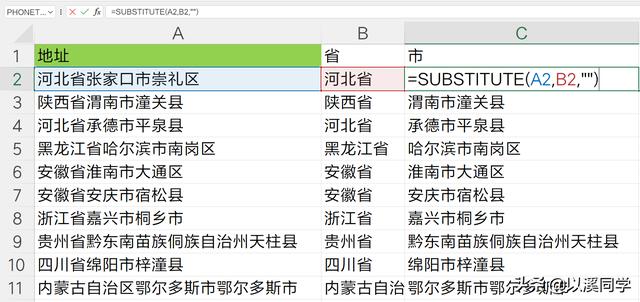
使用substitute函数,就可以替换字符串中的指定字符为空,也就是替换为""。
函数公式如下:
=SUBSTITUTE(A2,B2,"")
我们借用了刚刚提取的省级名称,生成了新的地址,基于这个地址我们采用同样的方法提取地级行政区名称。
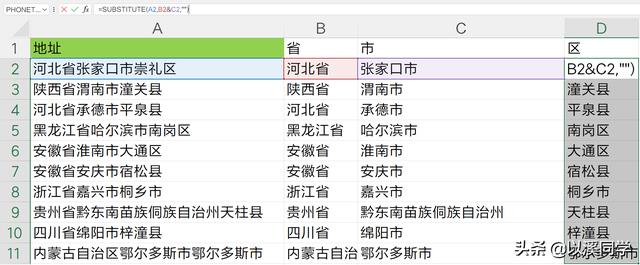
只需要把省级行政区的公式中的地址A2全部替换成上面的subtitute函数公式,再把对应的地级行政区的后缀,市、区、州、盟,全部修改,就可以了。
最终的数组公式如下:
=LEFT(SUBSTITUTE(A2,B2,"")&"市区州盟",MIN(FIND({"市","区","州","盟"},SUBSTITUTE(A2,B2,"")&"市区州盟")))
最后一个直接使用substitute函数替换即可。
数组公式如下:
=SUBSTITUTE(A2,B2&C2,"")
如果你不想用上面这么长的公式,又或者地址信息没有这么完整,存在不清晰的问题!!
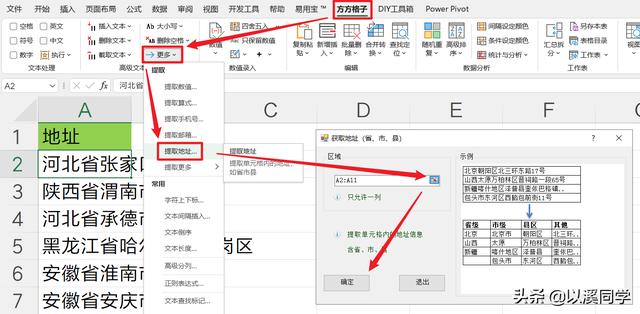
「那就使用方方格子插件来完成地址提取,速度飞快。」
操作路径:方方格子-高级文本处理更多-提取地址-选择地址范围-确定-点击结果存放单元格-确认
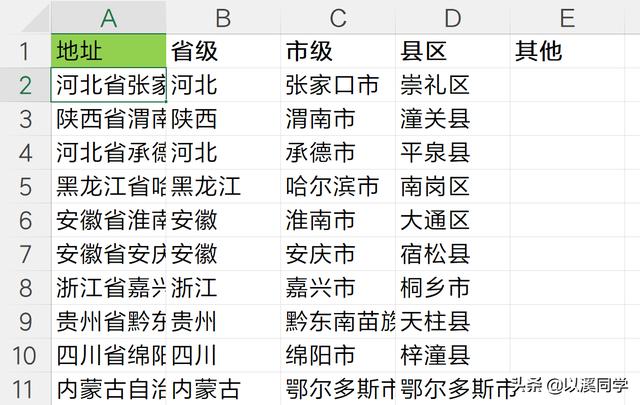
最终结果如下图,几秒钟就搞定了。
即使地址不是特别规范,也能大概匹配拆分出来。
当然,最终还需要仔细检查一下是否存在拆分出错的情况。
3. 提取指定字符-分隔的指定个数字符如下图数据所示:
文本中用-分隔各个信息,其中第二个是产品名称,最后一个是核销状态。
如果是比较规范的数据,就可以先手动提取一行,如下图:
然后按快捷键CTRL E,智能拆分提取,就能提取出对应的数据。
但是,这个案例,CTRL E没法很好的拆分出来,比如产品名称,此时可以选择使用函数公式,将产品名称和核销状态提取出来。
提取产品名称:
=MID(A2,FIND("-",A2) 1,FIND("-",A2,FIND("-",A2) 1)-FIND("-",A2)-1)
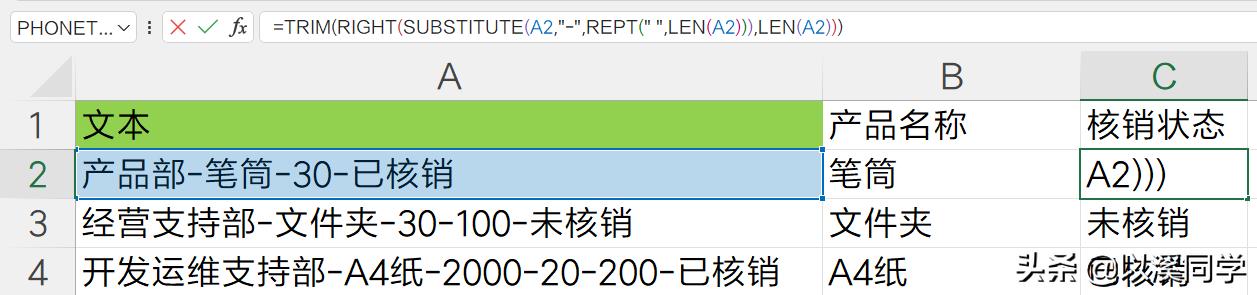
提取最后一个核销状态:
=TRIM(RIGHT(SUBSTITUTE(A2,"-",REPT("",LEN(A2))),LEN(A2)))
「提取产品名称公式原理解析:」
使用find函数找到第一个指定字符-的位置数,此时find函数默认从字符串第一个字开始找。
然后接着继续用find函数找指定字符-,但是此时,我们find函数的第三个参数就写第一次find函数的结果值 1,也就是从第一个指定字符-的下一个字符位置开始查找,由此找到了第二个-的位置。
至此mid函数的2、3参数已经完全找到了。
「提取最后一个核销状态公式原理解析」
使用substitute函数,将所有的指定字符-替换为长度和字符串长度一致的空格。替换后图片如下图。
使用right函数,从替换后的字符串右侧,提取长度为原本字符串长度的文本。此时的文本就是空格和最后一个核销状态数据
使用trim函数,去除文本中的空格
ps. 需要注意第一步中,我们使用rept函数,用来生成字符长度和原始字符串长度一致的空格
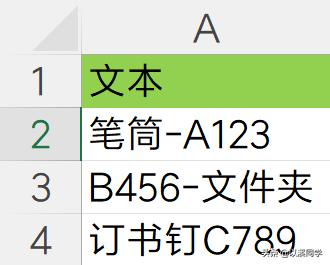
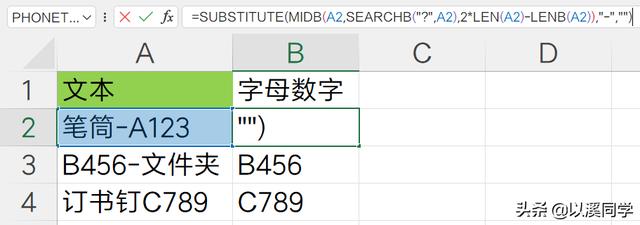
4. 只提取数字或者字母如下图所示,字母和数字在文本中的不同位置,现在想要将字母和数字全部提取。
从文本中提取字母和数字的公式如下:
=SUBSTITUTE(MIDB(A2,SEARCHB("?",A2),2*LEN(A2)-LENB(A2)),"-","")
「从字符串中提取字母数字公式原理解析:」
公式使用了字节和字符两种不同的计算方法。使用minb函数提取指定字节数的数据,lenb和len分别统计字节和字符数量。
由于字母数字和符号都是1个字节,中文是2个字符,通过searchb查找任意1个字节在字符串中的出现位置,就能定位字符串中第一个字母数字或者符号出现位置,进而通过midb函数提取。
提取位数则通过len和lenb的计数来计算出来,lenb减去len得到的就是中文字符的数量也就是2,换算就是4个字节,最后用lenb减去中文字符的字节数,就得到字母数字和符号的字节数。
最终使用substitute函数去除指定的符号,就提取完成了。
如果只想提取字母或者数字,则使用下面的公式:
只提取大小写字母的数组公式,请使用数组三键CTRL SHIFT 回车确认公式:
=CONCAT(IF(((CODE(MID(A2,ROW(INDIRECT("1:"&LEN(A2))),1))>=65)*(CODE(MID(A2,ROW(INDIRECT("1:"&LEN(A2))),1))<=90)) ((CODE(MID(A2,ROW(INDIRECT("1:"&LEN(A2))),1))>=97)*(CODE(MID(A2,ROW(INDIRECT("1:"&LEN(A2))),1))<=122)),MID(A2,ROW(INDIRECT("1:"&LEN(A2))),1),""))如果只提取数字,则数组公式如下:
=CONCAT(IF((CODE(MID(A2,ROW(INDIRECT("1:"&LEN(A2))),1))>=48)*(CODE(MID(A2,ROW(INDIRECT("1:"&LEN(A2))),1))<=57),MID(A2,ROW(INDIRECT("1:"&LEN(A2))),1),""))
「从字符串中单独提取字母或数字公式原理解析:」
上面的提取字母和数字,都使用了相同的原理,那就是code函数,对不同字符的对应编码,其中数字0到9,编码为48到57,大写字母A到Z,编码为65到90,小写字母a到z,编码为97到122。
公式是数组公式,使用了mid将字符串拆分成单独的字符,再通过code函数得到编码,与对应编码对比,区分字母和数字,最终通过if函数判断保留字母或数字,使用concat函数将保留的字符拼接在一起。
其中用到了sequence序列函数用法以及filter函数的多条件式判断,建议在以溪主页,查看对应文章,深入了解。
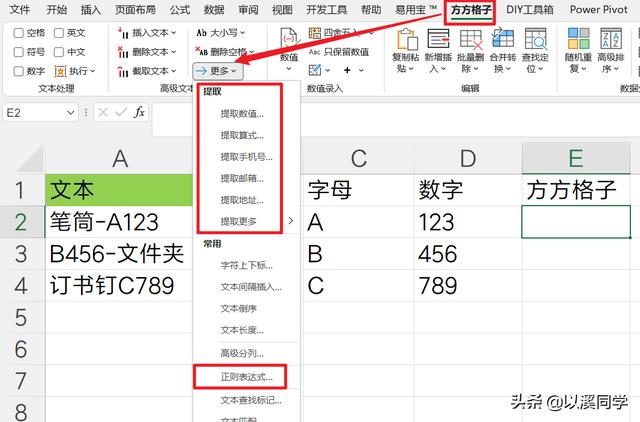
如果用数组公式觉得太麻烦,也可以使用Excel插件来提取字符,如果你会编写正则表达式,那无论是多奇怪的字符,都可以通过插件运行正则表达式提取指定的字符出来。
插件提取方法路径如下:
方方格子-高级文本处理-更多
同时在提取更多里面,还支持提取链接以及之前说的拆分地址。
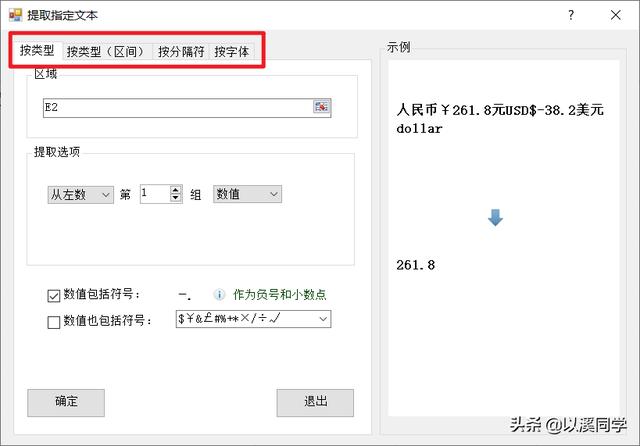
在高级提取功能里,支持额外4种提取需求,如图所示。
以上,就是以溪总结的文本字符串提取的相关案例,如果你有实际需求没有在以上案例,可以留言讨论。
,