主成分分析和因子分析有什么区别和联系?”这个问题其实很多朋友在后台提问过,今天将这个问题的答案写成推送分享给大家。
方法背景随着硬件技术的发展,每年被记录和存储下来的数据是非常庞大的,如何从庞大的数据堆中筛选出目标数据并分析得到有用的结论是现今重要的领域---数据挖掘。为了能够充分有效的利用数据,化繁为简是一项必做的工作,希望将原来繁多的描述变量浓缩成少数几个新指标,同时尽可能多的保存旧变量的信息,这些分析过程被称为数据降维。
主成分分析和因子分析是数据降维分析的主要手段。另一种化繁为简的手段是聚类。
降维分析简单理解就是将描述事物的众多指标(变量)通过一定的手段浓缩成少数几个有代表性且互不相关的新变量。聚类分析的分析对象是个案,每个个案都会有各种描述其情况的指标,根据各种指标的情况,将个案进行归类。例如,酒店通用的分级标准是一星到五星,每个等级都有对应的很多硬性指标,根据所有指标的综合情况评定酒店的级别。
今天我们介绍的就是降维分析的其中两种主要方法:主成分分析和因子分析。
主成分分析主成分分析可以简单的总结成一句话:数据的压缩和解释。常被用来寻找判断某种事物或现象的综合指标,并且给综合指标所包含的信息以适当的解释。在实际的应用过程中,主成分分析常被用作达到目的的中间手段,而非完全的一种分析方法。这也是为什么SPSS软件没有为主成分分析专门设置一个菜单选项,而是将其归并入因子分析。我们可以先了解主成分分析的分析模型。
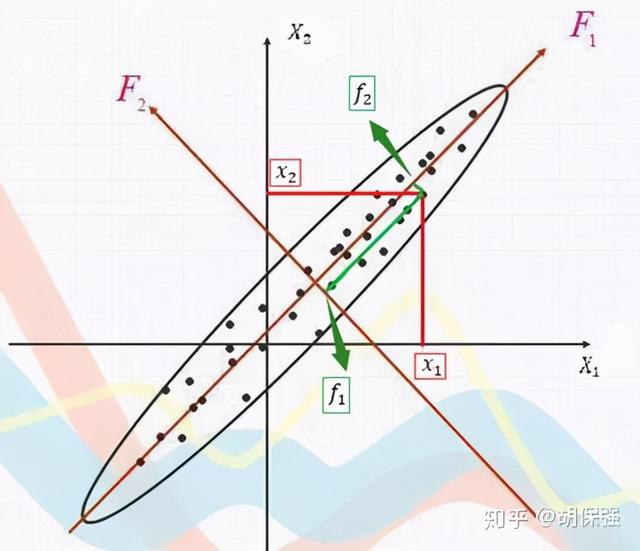
上面这幅图是经常被用来形象解释主成分分析原理。图中原来有两个坐标轴X1和X2,从散点分布可以很明显的知道散点在这两个坐标轴内存在线性相关。如果将这些散点在坐标轴X1和X2上的取值自变量x1和x2纳入到各种回归模型中,将会由于它们的多元共线问题致使拟合结论出现偏差。那么如何处理才能避免呢?这里给大家强调,统计学上数据信息往往指的是数据变异(数据波动)。在上图中,散点的分布构成了一个椭圆形点阵,在椭圆的长轴方向,数据波动明显大于短轴方向。此时如果沿着椭圆的长轴和短轴方向设定新的坐标轴(F1和F2)组成坐标系,那么新坐标系可以完全解释数据散点的信息,散点在新坐标轴上的取值就形成两个新的变量(f1和f2),这两个新变量之间是相互独立(不相关)。从散点图上还可以知道,长轴和短轴能够解释的数据信息是不同的,长轴变量携带了大部分数据的变异信息,而短轴上的变量只携带一小部分变异信息。此时只需要使用长轴方向上的新变量(f1)就可以代表原来两个变量(x1和x2)的大部分信息,达到降维的作用。主成分分析的这种坐标轴变化是通过将原来的坐标轴进行线性组合完成的。这个线性组合的过程涉及到线性代数部分的内容,这里不过多解释。假设描述对象(例如汽车)由k个自变量指标(油耗、车重、轴长、内饰等等)进行描述,因为这些指标很多都是相关的(重量与油耗),因此可以进行主成分分析,浓缩变量。经过坐标轴线性组合以后,可以形成下面的线性组合式子:
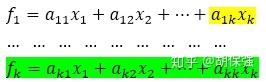
通过线性组合以后,主成分分析可以形成k个新变量。这里的线性组合大家可以理解成原来坐标轴的空间旋转,因此原来有多少变量(k个),经过主成分分析以后,形成数量一致的新变量(k个)。新变量之间的方差关系见下式。通常情况下,我们只许取前面几个即可。

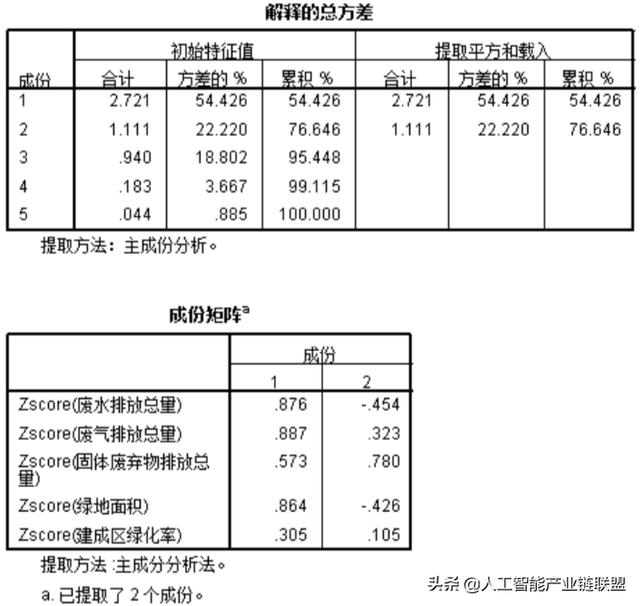
在主成分分析后,SPSS等软件会输出下面这个结果。包括特征根值,方差贡献率和累计方差贡献率。从表格结果可知,原来的变量数量是8个,经过矩阵的线性组合(正交变换)以后,形成了8个成分,前面三个成分总共贡献了数据变异的89.5%,因此提取了前面三个成分作为主成分。

- 特征根是矩阵线性组合后的产物,可以看作主成分的重要性指标,代表引入该主成分后可以解释多少原始变量的信息。如果特征根小于1,说明该主成分的解释力度还不如直接引入一个原变量的平均解释力度大,因此一般可以用特征根大于1作为纳入标准。
- 方差贡献率表示该主成分的方差在全部方差中的比重。这个值越大,表明主成分解释数据信息的能力越强,它与特征根是正相关的,特征根越大,方差贡献率越大。
- 累计贡献率表示前面n个主成分累计提取了多少数据信息。一般来说,如果前k个主成分的贡献率达到85%,表明提取前面k个主成分就基本可以解释所有数据信息。
主成分分析的一个重要的结论是主成分矩阵,如下表所示。主成分矩阵可以说明各主成分在原来变量上的载荷,所以也被称为载荷矩阵。

通过载荷矩阵可以写出主成分的组成结构表达式。我们以第一主成分为例,写出其表达式。从式子可以知道,第一主成分包含原来变量X1,X3和X8在信息最多,X2和X7其次,X4,X5和X6更少一些。这就是主成分分析的致命缺陷,提取出来的主成分不能明确解释成某几个原始变量的概率,为进一步分析制造了困难。(这个问题将由因子分析来解决)

主成分分析的另一个结论是主成分得分矩阵。其实就是主成分载荷矩阵除以主成分特征根后得到的矩阵。为什么要除以特征根呢?这是因为主成分载荷矩阵是带有成分重要性属性(包含特征根)的,如果要用提取得到的主成分进行综合排名比较或回归分析,需要先消除主成分的权重不平等(重要性不同),因此需要除以对应主成分的特征根,得到主成分得分矩阵。上表的主成分得分矩阵为:

根据主成分得分矩阵的得分系数,就可以计算每个个案在新变量(主成分)上的数值。进而可以将新变量值用于综合评分和回归。

以上就是主成分分析的所有过程。可以通过矩阵变换知道原始数据能够浓缩成几个主成分,以及每个主成分与原来变量之间线性组合关系式。但是细心的朋友会发现,每个原始变量在主成分中都占有一定的分量,这些分量(载荷)之间的大小分布没有清晰的分界线,这就造成无法明确表述哪个主成分代表哪些原始变量,也就是说提取出来的主成分无法清晰的解释其代表的含义。
因子分析鉴于主成分分析现实含义的解释缺陷,统计学斯皮尔曼又对主成分分析进行扩展。因子分析在提取公因子时,不仅注意变量之间是否相关,而且考虑相关关系的强弱,使得提取出来的公因子不仅起到降维的作用,而且能够被很好的解释。因子分析与主成分分析是包含与扩展的关系。首先解释包含关系。如下图所示,在SPSS软件“因子分析”模块的提取菜单中,提取公因子的方法很多,其中一种就是主成分。由此可见,主成分只是因子分析的一种方法。

其次是扩展关系。因子分析解决主成分分析解释障碍的方法是通过因子轴旋转。因子轴旋转可以使原始变量在公因子(主成分)上的载荷重新分布,从而使原始变量在公因子上的载荷两级分化,这样公因子(主成分)就能够用哪些载荷大的原始变量来解释。以上过程就解决了主成分分析的现实含义解释障碍。

上面两个表是旋转后的成分矩阵和成分得分系数矩阵,这两个表的数值与主成分分析的结果已经完全不同。从左边的表可以明显知道,第一公因子主要由X1,X8,X3和X5解释,第二公因子有X4和X2解释,第二公因子有X6和X7解释。右边表格的得分系数也不在是通过成分载荷/特征根得到,而是通过回归得出(后面的文章会介绍)。
总结一下从以上内容可以知道,主成分分析和因子分析的关系是包含与扩展。当因子分析提取公因子的方法是主成分(矩阵线性组合)时,因子分析结论的前半部分内容就是主成分分析的内容,而因子旋转是因子分析的专属(扩展),主成分分析是因子分析(提取公因子方法为主成分)的中间步骤。这就是为什么很多软件没有专门为主成分分析独立设计模块的原因。从应用范围和功能上讲,因子分析法完全能够替代主成分分析,并且解决了主成分分析不利于含义解释的问题,功能更为强大。
小结本文原创作者胡保强,请支持原创!
感谢大家耐心看完,自己的文章都写的很细,代码都在原文中,希望大家都可以自己做一做,请关注后私信回复“数据链接”获取所有数据和本人收集的学习资料。如果对您有用请先收藏,再点赞转发。
也欢迎大家的意见和建议,大家想了解什么统计方法都可以在文章下留言,说不定我看见了就会给你写教程哦。
如果你是一个大学本科生或研究生,如果你正在因为你的统计作业、数据分析、论文、报告、考试等发愁,如果你在使用SPSS,R,Python,Mplus, Excel中遇到任何问题,都可以联系我。因为我可以给您提供好的,详细和耐心的数据分析服务。
如果你对Z检验,t检验,方差分析,多元方差分析,回归,卡方检验,相关,多水平模型,结构方程模型,中介调节,量表信效度等等统计技巧有任何问题,请私信我,获取详细和耐心的指导。
If you are a student and you are worried about you statistical #Assignments, #Data #Analysis, #Thesis, #reports, #composing, #Quizzes, Exams.. And if you are facing problem in #SPSS, #R-Programming, #Excel, Mplus, then contact me. Because I could provide you the best services for your Data Analysis.
Are you confused with statistical Techniques like z-test, t-test, ANOVA, MANOVA, Regression, Logistic Regression, Chi-Square, Correlation, Association, SEM, multilevel model, mediation and moderation etc. for your Data Analysis...??
Then Contact Me. I will solve your Problem...
加油吧,打工人!
猜你喜欢R数据分析:探索性因子分析
R语言作图:如何在数据可视化过程中调整因子顺序
R数据分析:如何用R做验证性因子分析及画图,实例操练
R数据分析:双因素方差分析与交互作用检验
R数据分析:主成分分析及可视化
R语言文本挖掘:情感极性分析 LDA主题建模「二」
R文本挖掘:文本主题分析topic analysis
R语言文本挖掘:情感极性分析 LDA主题建模 「一」
R数据分析:多分类逻辑回归
,