提示:关注 转发本文 私信我“资料”,可获取更多电子书、技术教程、视频、大厂面试题等学习资料。

本文介绍阿里开源的 Sentinel 源码,GitHub: alibaba/Sentinel,基于当前最新的 release 版本
简介
Sentinel 的定位是流量控制、熔断降级,你应该把它理解为一个第三方 Jar 包。
这个 Jar 包会进行流量统计,执行流量控制规则。而统计数据的展示和规则的设置在 sentinel- dashboard 项目中,这是一个 Spring MVC 应用,有后台管理界面,我们通过这个管理后台和各个应 用进行交互。
当然,你不一定需要 dashboard,很长一段时间,我仅仅使用 sentinel-core,它会将统计信息写入到 指定的日志文件中,我通过该文件内容来了解每个接口的流量情况。当然,这种情况下,我只是使用到 了 Sentinel 的流量监控功能而已。
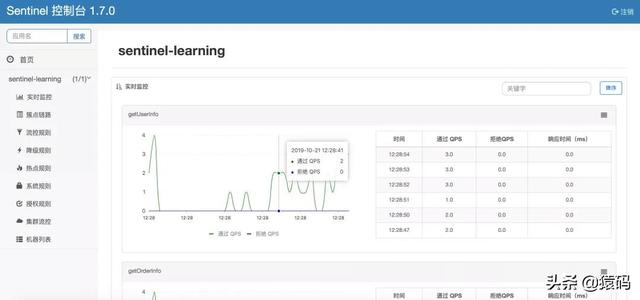
从左侧我们可以看到这个 dashboard 可以管理很多应用,而对于每个应用,我们还可以有很多机器实 例(见机器列表)。我们在这个后台,可以非常直观地了解到每个接口的 QPS 数据,我们可以对每个 接口设置流量控制规则、降级规则等。
这个 dashboard 应用默认是不持久化数据的,它的所有数据都是在内存中的,所以 dashboard 重启意 味着所有的数据都会丢失。你应该按照自己的需要来定制化 dashboard,如至少你应该要持久化规则 设置,QPS 数据非常适合存放在时序数据库中,当然如果你的数据量不大,存 MySQL 也问题不大,定 期清理一下过期数据即可,因为大部分人应该不会关心一个月以前的 QPS 数据。
sentinel-dashboard 并没有定位为一个功能强大的管理后台,一般来说,我们需要基于它来进行二次 开发,甚至于你也可以不使用这个 Java 项目,自己使用其他的语言来实现。在最后一小节,我介绍了 业务应用是怎么和 dashboard 应用交互的。
Sentinel 的数据统计
在正式开始介绍 Sentinel 的流程源码之前,我想先和大家介绍一下 Sentinel 的数据统计模块的内容, 这样读者在后面看到相应的内容的时候心里有一些底。这节内容还是比较简单的,当然,如果你希望立 马进入 Sentinel 的主流程,可以先跳过这一节。
Sentinel 的定位是流量控制,它有两个维度的控制,一个是控制并发线程数,另一个是控制 QPS,它们 都是针对某个具体的接口来设置的,其实说资源比较准确,Sentinel 把控制的粒度定义为 Resource。
既然要做控制,那么首先,Sentinel 就要先做统计,它要知道当前接口的 QPS 和并发是多少,进而判 断一个新的请求能不能让它通过。
这里我们先抛开 Sentinel 的各种概念,直接先看下数据统计的代码。数据统计的代码在 StatisticNode 中,对于 QPS 数据,它使用了滑动窗口的设计:
privatetransientvolatileMetricrollingCounterInSecond=new
ArrayMetric(SampleCountProperty.SAMPLE_COUNT,
IntervalProperty.INTERVAL);
privatetransientMetricrollingCounterInMinute=newArrayMetric(60,60*1000,false);
privateAtomicIntegercurThreadNum=newAtomicInteger(0);
先看最后的属性 curThreadNum,它使用 AtomicInteger 来统计并发量,就是原子加、原子减的操 作,非常简单,这里不浪费篇幅了,下面仅介绍 QPS 的统计。
从上面的代码也可以知道,Sentinel 统计了 秒 和 分 两个维度的数据,下面我们简单说说实现类 ArrayMetric 的源码设计。
publicclassArrayMetricimplementsMetric{
privatefinalLeapArray<MetricBucket>data;
publicArrayMetric(intsampleCount,intintervalInMs){
this.data=newOccupiableBucketLeapArray(sampleCount,intervalInMs);
}
publicArrayMetric(intsampleCount,intintervalInMs,booleanenableOccupy)
{
if(enableOccupy){
this.data=newOccupiableBucketLeapArray(sampleCount,
intervalInMs);
}else{
this.data=newBucketLeapArray(sampleCount,intervalInMs);
}
}
......
}
ArrayMetric 的内部是一个 LeapArray,我们以分钟维度统计的使用来说,它使用子类BucketLeapArray 实现。
这里先介绍较为简单的 BucketLeapArray 的实现,然后在最后一节会介绍
OccupiableBucketLeapArray。
publicabstractclassLeapArray<T>{
protectedintwindowLengthInMs;
protectedintsampleCount;
protectedintintervalInMs;
protectedfinalAtomicReferenceArray<WindowWrap<T>>array;
//对于分钟维度的设置,sampleCount为60,intervalInMs为60*1000
publicLeapArray(intsampleCount,intintervalInMs){
//单个窗口长度,这里是1000ms
this.windowLengthInMs=intervalInMs/sampleCount;
//一轮总时长60,000ms
this.intervalInMs=intervalInMs;
//60个窗口
this.sampleCount=sampleCount;
this.array=newAtomicReferenceArray<>(sampleCount);
}
//......
}
它的内部核心是一个数组 array,它的长度为 60,也就是有 60 个窗口,每个窗口长度为 1 秒,刚好一分钟走完一轮。然后下一轮开启“覆盖”操作。

每个窗口是一个 WindowWrap 类实例。
添加数据的时候,先判断当前走到哪个窗口了(当前时间(s) % 60 即可),然后需要判断这个窗口是否是过期数据,如果是过期数据(窗口代表的时间距离当前已经超过 1 分钟),需要先重置这个窗口实例的数据。
统计数据同理,如统计过去一分钟的 QPS 数据,就是将每个窗口的值相加,当中需要判断窗口数据是否是过期数据,即判断窗口的 WindowWrap 实例是否是一分钟内的数据。
核心逻辑都封装在了 currentWindow(long timeMillis) 和 values(long timeMillis) 方法中。
添加数据的时候,我们要先获取操作的目标窗口,也就是 currentWindow 这个方法,Sentinel 在这里处理初始化和过期重置的情况:
privatetransientvolatileMetricrollingCounterInSecond=new
ArrayMetric(SampleCountProperty.SAMPLE_COUNT,
IntervalProperty.INTERVAL);
privatetransientMetricrollingCounterInMinute=newArrayMetric(60,60*1000,false);
privateAtomicIntegercurThreadNum=newAtomicInteger(0);
获取数据,使用的是 values 方法,这个方法返回“有效的”窗口中的数据:
publicList<T>values(longtimeMillis){
if(timeMillis<0){
returnnewArrayList<T>();
}
intsize=array.length();
List<T>result=newArrayList<T>(size);
for(inti=0;i<size;i ){
WindowWrap<T>windowWrap=array.get(i);
//过滤掉过期数据
if(windowWrap==null||isWindowDeprecated(timeMillis,windowWrap)){
continue;
}
result.add(windowWrap.value());
}
returnresult;
}
//判断当前窗口的数据是否是60秒内的
publicbooleanisWindowDeprecated(longtime,WindowWrap<T>windowWrap){
returntime-windowWrap.windowStart()>intervalInMs;
}
这个 values 方法很简单,就是过滤掉那些过期数据就可以了。
到这里,我们就说完了 分 维度数据统计的问题。至于秒维度的数据统计,有些不一样,稍微复杂一些,我在后面单独起了一节。跳过这部分内容对阅读 Sentinel 源码没有影响。
Sentinel 源码分析
下面,我们正式开始 Sentinel 的源码介绍。
官方文档中,它的最简单的使用是下面这样的,这里用了 try-with-resource 的写法:
publicclassArrayMetricimplementsMetric{
privatefinalLeapArray<MetricBucket>data;
publicArrayMetric(intsampleCount,intintervalInMs){
this.data=newOccupiableBucketLeapArray(sampleCount,intervalInMs);
}
publicArrayMetric(intsampleCount,intintervalInMs,booleanenableOccupy)
{
if(enableOccupy){
this.data=newOccupiableBucketLeapArray(sampleCount,
intervalInMs);
}else{
this.data=newBucketLeapArray(sampleCount,intervalInMs);
}
}
......
}
这个例子对于理解源码其实不是很好,我们来写一个复杂一些的例子,这样对理解源码有很大的帮助:

1、红色部分,Context 代表一个调用链的入口,Context 实例设置在 ThreadLocal 中,所以它是跟着线程走的,如果要切换线程,需要手动切换。ContextUtil#enter 有两个参数:
第一个参数是 context name,它代表调用链的入口,作用是为了区分不同的调用链路,个人感觉没什么用,默认是 Constants.CONTEXT_DEFAULT_NAME 的常量值 "sentinel_default_context";第二个参数代表调用方标识 origin,目前它有两个作用,一是用于黑白名单的授权控制,二是可以用来统计诸如从应用 application-a 发起的对当前应用 interfaceXxx() 接口的调用,目前这个数据会被统计,但是 dashboard 中并不展示。
2、进入 BlockException 异常分支,代表该次请求被流量控制规则限制了,我们一般会让代码走入到熔断降级的逻辑里面。当然,BlockException 其实有好多个子类,如 DegradeException、FlowException 等,我们也可以 catch 具体的子类来进行处理。7v
3、Entry 是我们的重点,对于 SphU#entry 方法:第一个参数标识资源,通常就是我们的接口标识,对于数据统计、规则控制等,我们一般都是在这个粒度上进行的,根据这个字符串来唯一标识,它会被包装成 ResourceWrapper 实例,大家要先看下它的hashCode 和 equals 方法;第二个参数标识资源的类型,我们左边的代码使用了 EntryType.IN 代表这个是入口流量,比如我们的接口对外提供服务,那么我们通常就是控制入口流量;EntryType.OUT 代表出口流量,比如上面的getOrderInfo 方法(没写默认就是 OUT),它的业务需要调用订单服务,像这种情况,压力其实都在订单服务中,那么我们就指定它为出口流量。这个流量类型有什么用呢?答案在 SystemSlot 类中,它用于实现自适应限流,根据系统健康状态来判断是否要限流,如果是 OUT 类型,由于压力在外部系统中,所以就不需要执行这个规则。
4、上面的代码,我们在 getOrderInfo 中嵌套使用了 Entry,也是为了我们后面的源码分析需要。如果我们在一个方法中写的话,要注意内层的 Entry 先 exit,才能做外层的 exit,否则会抛出异常。源码角度来看,是在 Context 实例中,保存了当前的 Entry 实例。
5、实际开发过程中,我们当然不会每个接口都像上面的代码这么写,Sentinel 提供了很多的扩展和适配器,这里只是为了源码分析的需要。
Sentinel 提供了很多的 adapter 用于诸如 dubbo、grpc、网关等环境,它们其实都是封装了上述的代码。你只要认真看完本文,那些包装都很容易看懂。

这里我们介绍了 Sentinel 的接口使用,不过它的类名字我现在都没懂是什么意思,SphU、CtSph、CtEntry 这些名字有什么特殊含义,有知道的读者请不吝赐教。
下面,我们按照上面的代码,开始源码分析。这里我不会像之前分析 Spring IOC 和 Netty 源码一样,一行一行代码说,所以大家一定要打开源码配合着看。
ContextUtil#enter我们先看 Context#enter 方法,这行代码我们是可以不写的,通常情况下,我们都不会显示设置context。
publicabstractclassLeapArray<T>{
protectedintwindowLengthInMs;
protectedintsampleCount;
protectedintintervalInMs;
protectedfinalAtomicReferenceArray<WindowWrap<T>>array;
//对于分钟维度的设置,sampleCount为60,intervalInMs为60*1000
publicLeapArray(intsampleCount,intintervalInMs){
//单个窗口长度,这里是1000ms
this.windowLengthInMs=intervalInMs/sampleCount;
//一轮总时长60,000ms
this.intervalInMs=intervalInMs;
//60个窗口
this.sampleCount=sampleCount;
this.array=newAtomicReferenceArray<>(sampleCount);
}
//......
}
下面我们就会看到,如果我们不显式调用这个方法,那么会进入到默认的 context 中。
进入到 ContextUtil 类,大家可能会漏看它的 static 代码块,这里会添加一个默认的EntranceNode 实例。
然后上面的这个方法会走到 ContextUtil#trueEnter 中,这里会添加名为 "user-center" 的
EntranceNode 节点。根据源码,我们可以得出下面这棵树:

这里的源码非常简单,如果我们从来不显式调用 ContextUtil#enter 方法的话,那 root 就只有一个default 子节点 sentinel_default_context。
context 很好理解,它代表线程执行的上下文,在各种开源框架中都有类似的语义,在 Sentinel 中,我们可以看到,对于一个新的 context name,Sentinel 会往树中添加一个 EntranceNode 实例。它的作用是为了区分调用链路,标识调用入口。在 sentinel-dashboard 中,我们可以很直观地看出调用链路:

SphU#entry
接下来,我们看 SphU#entry 。自己跟进去,我们会来到 CtSph#entryWithPriority 方法,这个方法是 Sentinel 的骨架,非常重要。
privatetransientvolatileMetricrollingCounterInSecond=new
ArrayMetric(SampleCountProperty.SAMPLE_COUNT,
IntervalProperty.INTERVAL);
privatetransientMetricrollingCounterInMinute=newArrayMetric(60,60*1000,false);
privateAtomicIntegercurThreadNum=newAtomicInteger(0);
publicclassDefaultSlotChainBuilderimplementsSlotChainBuilder{
@Override
publicProcessorSlotChainbuild(){
ProcessorSlotChainchain=newDefaultProcessorSlotChain();
chain.addLast(newNodeSelectorSlot());
chain.addLast(newClusterBuilderSlot());
chain.addLast(newLogSlot());
chain.addLast(newStatisticSlot());
chain.addLast(newAuthoritySlot());
chain.addLast(newSystemSlot());
chain.addLast(newFlowSlot());
chain.addLast(newDegradeSlot());
returnchain;
}
}
}
接下来,我们就按照默认的 DefaultSlotChainBuilder 生成的责任链往下看源码。
这里要强调一点,对于相同的 resource,使用同一个责任链实例,不同的 resource,使用不同的责任链实例。
另外,对于 resource 实例,我们前面也说了,它根据 resource name 来判断,和线程没有关系。
NodeSelectorSlot

首先,链中第一个处理节点是 NodeSelectorSlot。
publicList<T>values(longtimeMillis){
if(timeMillis<0){
returnnewArrayList<T>();
}
intsize=array.length();
List<T>result=newArrayList<T>(size);
for(inti=0;i<size;i ){
WindowWrap<T>windowWrap=array.get(i);
//过滤掉过期数据
if(windowWrap==null||isWindowDeprecated(timeMillis,windowWrap)){
continue;
}
result.add(windowWrap.value());
}
returnresult;
}
//判断当前窗口的数据是否是60秒内的
publicbooleanisWindowDeprecated(longtime,WindowWrap<T>windowWrap){
returntime-windowWrap.windowStart()>intervalInMs;
}
我们前面说了,责任链实例和 resource name 相关,和线程无关,所以当处理同一个 resource 的时候,会进入到同一个 NodeSelectorSlot 实例中。
所以这块代码主要就是要处理:不同的 context name,同一个 resource name 的情况。
如下面两段代码,它们都是处理同一个 resource("getUserInfo" 这个 resource),但是它们的入口context 不一致。

然后我们再结合前面的那棵树,我们可以得出下面这棵树,看深色的部分:

NodeSelectorSlot 还是比较简单的,只要读者搞清楚 NodeSelectorSlot 实例是跟着 resource 一一对
应的就很清楚了。
ClusterBuilderSlot

接下来,我们来到了 ClusterBuilderSlot 这一环,这一环的主要作用是构建 ClusterNode。
这里不贴源码,根据上面的树,然后在经过该类的处理以后,我们可以得出下面这棵树:

看上图中深色部分,对于每一个 resource,这里会对应一个 ClusterNode 实例,如果不存在,就创建一个实例。
这个 ClusterNode 非常有用,因为我们就是使用它来做数据统计的。比如 getUserInfo 这个接口,由于从不同的 context name 中开启调用链,它有多个 DefaultNode 实例,但是只有一个ClusterNode,通过这个实例,我们可以知道这个接口现在的 QPS 是多少。
另外,这个类还处理了 origin 不是默认值的情况:
再说一次,origin 代表调用方标识,如 application-a, application-b 等。
publicclassArrayMetricimplementsMetric{ privatefinalLeapArray<MetricBucket>data; publicArrayMetric(intsampleCount,intintervalInMs){ this.data=newOccupiableBucketLeapArray(sampleCount,intervalInMs); } publicArrayMetric(intsampleCount,intintervalInMs,booleanenableOccupy) { if(enableOccupy){ this.data=newOccupiableBucketLeapArray(sampleCount, intervalInMs); }else{ this.data=newBucketLeapArray(sampleCount,intervalInMs); } } ...... }我们可以看到,当设置了 origin 的时候,会额外生成一个 StatisticsNode 实例,挂在 ClusterNode上。
我们把前面的代码改改,看红色部分:
我们的 getUserInfo 接收到了来自 application-a 和 application-b 两个应用的请求,那么树会变成下面这样:
它的作用是用来统计从 application-a 过来的访问 getUserInfo 这个接口的信息。目前这个信息在dashboard 中是不展示的,毕竟也没什么用。
LogSlot
这个类比较简单,我们看到它直接 fire 出去了,也就是说,先处理责任链上后面的那些节点,如果它们抛出了 BlockException,那么这里才做处理。
这里调用了 EagleEyeLogUtil#log 方法,它其实就是,将被设置的规则 block 的信息记录到日志文件sentinel-block.log 中。也就是记录哪些接口被规则挡住了。
StatisticSlot
这个 slot 非常重要,它负责进行数据统计。
它也是先 fire 出去,等后面的节点处理完毕以后,它再进行统计数据。之所以这么设计,是因为后面的节点是做控制的,执行的时候可能是正常通过的,也可能是抛出 BlockException 异常的。源码非常简单,对于 QPS 统计,使用前面介绍的滑动窗口,而对于线程并发的统计,它使用了LongAdder。
大家一定要看一遍这个类的源码,这里没有什么特别的内容需要强调,所以我就不展开说了。
接下来,我们后面要介绍的几个 Slot,需要通过 dashboard 进行开启,因为需要配置规则。
当然,你也可以硬编码规则到代码中。但是要调整数值就比较麻烦,每次都要改代码。
AuthoritySlot
这个类非常简单,做权限控制,根据 origin 做黑白名单的控制:
在 dashboard 中,是这么配置的:
SystemSlot
这个是 Sentinel 中比较重要的一个东西了,用来实现自适应限流。
规则校验都在 SystemRuleManager#checkSystem 中:
我们先说说上面的代码中的 RT、线程数、入口 QPS 这三项系统保护规则。dashboard 配置界面:
在前面介绍的 StatisticSlot 类中,有下面一段代码:
Sentinel 针对所有的入口流量,使用了一个全局的 ENTRY_NODE 进行统计,所以我们也要知道,系统
保护规则是全局的,和具体的某个资源没有关系。
由于系统的平均 RT、当前线程数、QPS 都可以从 ENTRY_NODE 中获得,所以限制代码非常简单,比较一下大小就可以了。如果超过阈值,抛出 SystemBlockException 。
ENTRY_NODE 是 ClusterNode 类型的,而 ClusterNode 对于 rt、qps 都是统计的秒维度的数据。
当然,对于 SystemSlot 类来说,最重要的其实并不是上面的这些,因为在实际使用过程中,对于 RT、线程数、QPS 每一项,我们其实都很难设置一个确定的阈值。
我们往下看它的对于系统负载和 CPU 资源的保护:
我们可以看到,Sentinel 通过调用 MBean 中的方法获取当前的系统负载和 CPU 使用率,Sentinel 起了一个后台线程,每秒查询一次。
publicabstractclassLeapArray<T>{ protectedintwindowLengthInMs; protectedintsampleCount; protectedintintervalInMs; protectedfinalAtomicReferenceArray<WindowWrap<T>>array; //对于分钟维度的设置,sampleCount为60,intervalInMs为60*1000 publicLeapArray(intsampleCount,intintervalInMs){ //单个窗口长度,这里是1000ms this.windowLengthInMs=intervalInMs/sampleCount; //一轮总时长60,000ms this.intervalInMs=intervalInMs; //60个窗口 this.sampleCount=sampleCount; this.array=newAtomicReferenceArray<>(sampleCount); } //...... }下图展示 dashboard 中对于 CPU 使用率的规则配置:
FlowSlot
Flow CONTROL 是 Sentinel 的核心, 因为 Sentinel 本身定位就是一个流控工具,所以 FlowSlot 非常重要。
对于读者来说,最大的挑战应该也是这部分代码,因为前面的代码,只要读者理得清楚里面各个类的关系,就不难。而这部分代码由于涉及到限流算法,会稍微复杂一点点。
在 Sentinel 的流控中,我们可以配置流控规则,主要是控制 QPS 和并发线程数,这里我们不讨论控制线程数,控制线程数的代码不在我们这里的讨论范围内,下面的介绍都是指控制 QPS。
RateLimiterController
RateLimiterController 非常简单,它通过使用 latestPassedTime 属性来记录最后一次通过的时间,然后根据规则中 QPS 的限制,计算当前请求是否可以通过。它在 Sentinel 中的流控效果定义为 “排队等待”。
举个非常简单的例子:设置 QPS 为 10,那么每 100 毫秒允许通过一个,通过计算当前时间是否已经过了上一个请求的通过时间 latestPassedTime 之后的 100 毫秒,来判断是否可以通过。假设才过了50ms,那么需要当前线程再 sleep 50ms,然后才可以通过。如果同时有另一个请求呢?那需要 sleep150ms 才行。
publicWindowWrap<T>currentWindow(longtimeMillis){ if(timeMillis<0){ returnnull; } //获取窗口下标 intidx=calculateTimeIdx(timeMillis); //计算该窗口的理论开始时间 longwindowStart=calculateWindowStart(timeMillis); //嵌套在一个循环中,因为有并发的情况 } while(true){ WindowWrap<T>old=array.get(idx); if(old==null){ //窗口未实例化的情况,使用一个CAS来设置该窗口实例 WindowWrap<T>window=newWindowWrap<T>(windowLengthInMs, windowStart,newEmptyBucket(timeMillis)); if(array.compareAndSet(idx,null,window)){ returnwindow; }else{ //存在竞争 Thread.yield(); } }elseif(windowStart==old.windowStart()){ //当前数组中的窗口没有过期 returnold; }elseif(windowStart>old.windowStart()){ //该窗口已过期,重置窗口的值。使用一个锁来控制并发。 if(updateLock.tryLock()){ try{ returnresetWindowTo(old,windowStart); }finally{ updateLock.unlock(); } }else{ Thread.yield(); } }elseif(windowStart<old.windowStart()){ //正常情况都不会走到这个分支,异常情况其实就是时钟回拨,这里返回一个 WindowWrap是容错 returnnewWindowWrap<T>(windowLengthInMs,windowStart, newEmptyBucket(timeMillis)); } } }这个源码非常简单,策略也非常简单,这里就不做过多讨论了。
WarmUpController
WarmUpController 用来防止突发流量迅速上升,导致系统负载严重过高,本来系统在稳定状态下能处理的,但是由于许多资源没有预热,导致这个时候处理不了了。比如,数据库需要建立连接、需要连接到远程服务等,这就是为什么我们需要预热。
啰嗦一句,这里不仅仅指系统刚刚启动需要预热,对于长时间处于低负载的系统,突发流量也需要重新预热。
Guava 的 SmoothWarmingUp 是用来控制获取令牌的速率的,和这里的控制 QPS 还是有一点区别,但是中心思想是一样的。我们在看完源码以后再讨论它们的区别。
为了帮助大家理解源码,我们这边先设定一个场景:QPS 设置为 100,预热时间设置为 10 秒。代码中
使用 “【】” 代表根据这个场景计算出来的值。
接下来,大家请仔细看下面的这块源码:
publicclassDefaultSlotChainBuilderimplementsSlotChainBuilder{ @Override publicProcessorSlotChainbuild(){ ProcessorSlotChainchain=newDefaultProcessorSlotChain(); chain.addLast(newNodeSelectorSlot()); chain.addLast(newClusterBuilderSlot()); chain.addLast(newLogSlot()); chain.addLast(newStatisticSlot()); chain.addLast(newAuthoritySlot()); chain.addLast(newSystemSlot()); chain.addLast(newFlowSlot()); chain.addLast(newDegradeSlot()); returnchain; } } }
@Override publicbooleancanPass(Nodenode,intacquireCount){ returncanPass(node,acquireCount,false); } @Override publicbooleancanPass(Nodenode,intacquireCount,booleanprioritized){ //Sentinel的QPS统计使用的是滑动窗口 //当前时间窗口的QPS longpassQps=(long)node.passQps(); //这里是上一个时间窗口的QPS,这里的一个窗口跨度是1秒钟 longpreviousQps=(long)node.previousPassQps(); //同步。设置 storedTokens 和 lastFilledTime 到正确的值 syncToken(previousQps); longrestToken=storedTokens.get(); //令牌数超过warningToken,进入梯形区域 if(restToken>=warningToken){ //这里简单说一句,因为当前的令牌数超过了warningToken这个阈值,系统处于需要 预热的阶段 //通过计算当前获取一个令牌所需时间,计算其倒数即是当前系统的最大QPS容量 longaboveToken=restToken-warningToken; //这里计算警戒 QPS 值,就是当前状态下能达到的最高 QPS。 //(aboveToken*slope 1.0/count)其实就是在当前状态下获取一个令牌所需 要的时间 doublewarningQps=Math.nextUp(1.0/(aboveToken*slope 1.0/ count)); //如果不会超过,那么通过,否则不通过 if(passQps acquireCount<=warningQps){ returntrue; } }else{ //count是最高能达到的QPS if(passQps acquireCount<=count){ returntrue; } } returnfalse; } protectedvoidsyncToken(longpassQps){ //下面几行代码,说明在第一次进入新的1秒钟的时候,做同步 //题外话:Sentinel 默认地,1 秒钟分为 2 个时间窗口,分别 500ms longcurrentTime=TimeUtil.currentTimeMillis(); currentTime=currentTime-currentTime%1000; longoldLastFillTime=lastFilledTime.get(); if(currentTime<=oldLastFillTime){ return; } /令牌数量的旧值 longoldValue=storedTokens.get(); //计算新的令牌数量,往下看 longnewValue=coolDownTokens(currentTime,passQps); if(storedTokens.compareAndSet(oldValue,newValue)){ //令牌数量上,减去上一分钟的QPS,然后设置新值 longcurrentValue=storedTokens.addAndGet(0-passQps); if(currentValue<0){ storedTokens.set(0L); } lastFilledTime.set(currentTime); } } //更新令牌数 privatelongcoolDownTokens(longcurrentTime,longpassQps){ longoldValue=storedTokens.get(); longnewValue=oldValue; //当前令牌数小于warningToken,添加令牌 if(oldValue<warningToken){ newValue=(long)(oldValue (currentTime-lastFilledTime.get())* count/1000); }elseif(oldValue>warningToken){ //当前令牌数量处于梯形阶段, //如果当前通过的QPS大于count/coldFactor,说明系统消耗令牌的速度,大于冷却 速度 //那么不需要添加令牌,否则需要添加令牌 if(passQps<(int)count/coldFactor){ newValue=(long)(oldValue (currentTime- lastFilledTime.get())*count/1000); } } returnMath.min(newValue,maxToken); } }coolDownTokens 这个方法用来计算新的 token 数量,其实我也没有完全理解作者的设计:
第一、对于令牌的增加,在 Guava 中,使用 warmupPeriodMicros / maxPermits 作为增长率,因为它实现的是 storedPermits 从 0 到 maxPermits 花费的时间为 warmupPeriod。而这里是以设置的 QPS 作为增长率,为什么?
第二、else if 分支中的决定我没有理解,为什么用 passQps 和 count / coldFactor 进行对比来决定是否继续添加令牌?
我自己的理解是,count/coldFactor 就是指冷却速度,那么就是说得通的。欢迎大家一起探讨。
最后,我们再简单说说 Guava 的 SmoothWarmingUp 和 Sentinel 的 WarmupController 的区别。
Guava 在于控制获取令牌的速率,它关心的是,获取 permits 需要多少时间,包括从 storedPermits中获取,以及获取 freshPermits,以此推进 nextFreeTicketMicros 到未来的某个时间点。
而 Sentinel 在于控制 QPS,它用令牌数来标识当前系统处于什么状态,根据时间推进一直增加令牌,根据通过的 QPS 一直减少令牌。如果 QPS 持续下降,根据推演,可以发现 storedTokens 越来越多,然后越过 warningTokens 这个阈值,之后只有当 QPS 下降到 count/3 以后,令牌才会继续往上增长,一直到 maxTokens。
storedTokens 是以 “count 每秒”的增长率增长的,减少是以 前一分钟的 QPS 来减少的。其实这里我也有个疑问,为什么增加令牌的时候考虑了时间,而减少的时候却不考虑时间因素,提了issue,不过还没有得到回答。
WarmUpRateLimiterController
注意,这个类继承自刚刚介绍的 WarmUpController。它的代码其实就是前面介绍的
RateLimiterController 加上 WarmUpController。
publicclassWarmUpRateLimiterControllerextendsWarmUpController{ privatefinalinttimeoutInMs; privatefinalAtomicLonglatestPassedTime=newAtomicLong(-1); publicWarmUpRateLimiterController(doublecount,intwarmUpPeriodSec,int timeOutMs,intcoldFactor){ super(count,warmUpPeriodSec,coldFactor); this.timeoutInMs=timeOutMs; } @Override publicbooleancanPass(Nodenode,intacquireCount){ returncanPass(node,acquireCount,false); } @Override publicbooleancanPass(Nodenode,intacquireCount,booleanprioritized){ longpreviousQps=(long)node.previousPassQps(); syncToken(previousQps); longcurrentTime=TimeUtil.currentTimeMillis(); longrestToken=storedTokens.get(); longcostTime=0; longexpectedTime=0; //和RateLimiterController比较,区别主要就是这块代码,计算costTime上有区别 if(restToken>=warningToken){ longaboveToken=restToken-warningToken; //currentinterval=restToken*slope 1/count doublewarmingQps=Math.nextUp(1.0/(aboveToken*slope 1.0/ count)); costTime=Math.round(1.0*(acquireCount)/warmingQps*1000); }else{ costTime=Math.round(1.0*(acquireCount)/count*1000); } expectedTime=costTime latestPassedTime.get(); if(expectedTime<=currentTime){ latestPassedTime.set(currentTime); returntrue; }else{ longwaitTime=costTime latestPassedTime.get()-currentTime; if(waitTime>timeoutInMs){ returnfalse; }else{ longoldTime=latestPassedTime.addAndGet(costTime); try{ waitTime=oldTime-TimeUtil.currentTimeMillis(); if(waitTime>timeoutInMs){ latestPassedTime.addAndGet(-costTime); returnfalse; } if(waitTime>0){ Thread.sleep(waitTime); } returntrue; }catch(InterruptedExceptione){ } } } returnfalse; } }这个代码很简单,就是 RateLimiterController 中的代码,然后加入了预热的内容。
在 RateLimiterController 中,单个请求的 costTime 是固定的,就是 1/count,比如设置 100 qps,那么 costTime 就是 10ms。
但是这边,加入了 WarmUp 的内容,就是说,通过令牌数量,来判断当前系统的 QPS 应该是多少,如果当前令牌数超过 warningTokens,那么系统的最大 QPS 容量已经低于我们预设的 QPS,相应的,costTime 就会延长。
DegradeSlot
恭喜大家,终于到最后一个 slot 了。
它有三个策略,我们首先说说根据 RT 降级:
如果按照上面截图所示的配置:对于 getUserInfo 这个资源,正常情况下,它只需要 50ms 就够了,如果它的 RT 超过了 100ms,那么它会进入半降级状态,接下来的 5 次访问,如果都超过了 100ms,那么在接下来的 10 秒内,所有的请求都会被拒绝。
其实这个描述不是百分百准确,打开 DegradeRule#passCheck 源码,我们用代码来描述:
Sentinel 使用了 cut 作为开关,开启这个开关以后,会启动一个定时任务,过了 10秒 以后关闭这个开关。
publicList<T>values(longtimeMillis){ if(timeMillis<0){ returnnewArrayList<T>(); } intsize=array.length(); List<T>result=newArrayList<T>(size); for(inti=0;i<size;i ){ WindowWrap<T>windowWrap=array.get(i); //过滤掉过期数据 if(windowWrap==null||isWindowDeprecated(timeMillis,windowWrap)){ continue; } result.add(windowWrap.value()); } returnresult; } //判断当前窗口的数据是否是60秒内的 publicbooleanisWindowDeprecated(longtime,WindowWrap<T>windowWrap){ returntime-windowWrap.windowStart()>intervalInMs; }对于异常比例和异常数的控制,非常简单,大家看一下源码就懂了。同理,达到阈值,开启断路器,之后由定时任务关闭,这里就不浪费篇幅了。
应用和 sentinel-dashboard 的交互
这里花点篇幅介绍一下客户端是怎么和 dashboard 进行交互的。
在 Sentinel 的源码中,打开 sentinel-transport 工程,可以看到三个子工程,common 是基础包和接口定义。
如果客户端要接入 dashboard,可以使用 netty-http 或 simple-http 中的一个。为什么不直接使用Netty,而要同时提供 http 的选项呢?那是因为你不一定使用 Java 来实现 dashboard,如果我们使用其他语言来实现 dashboard 的话,使用 http 协议比较容易适配。
下面我们只介绍 http 的使用,首先,添加 simple-http 依赖:
<dependency> <groupId>com.alibaba.csp</groupId> <artifactId>sentinel-transport-simple-http</artifactId> <version>1.6.3</version> </dependency>然后在应用启动参数中添加 dashboard 服务器地址,同时可以指定当前应用的名称:
-Dcsp.sentinel.dashboard.server=127.0.0.1:8080-Dproject.name=sentinel-learning这个时候我们打开 dashboard 是看不到这个应用的,因为没有注册。
当我们在第一次使用 Sentinel 以后,Sentinel 会自动注册。
下面带大家看看过程是怎样的。首先,我们在使用 Sentinel 的时候会调用 SphU#entry :
publicstaticEntryentry(Stringname)throwsBlockException{ returnEnv.sph.entry(name,EntryType.OUT,1,OBJECTS0); }这里使用了 Env 类,其实就是这个类做的事情:
publicclassEnv{ publicstaticfinalSphsph=newCtSph(); static{ //Ifinitfails,theprocesswillexit. InitExecutor.doInit(); } }进到 InitExecutor.doInit 方法:
publicstaticvoiddoInit(){ if(!initialized.compareAndSet(false,true)){ return; } try{ ServiceLoader<InitFunc>loader=ServiceLoader.load(InitFunc.class); List<OrderWrapper>initList=newArrayList<OrderWrapper>(); for(InitFuncinitFunc:loader){ insertSorted(initList,initFunc); } for(OrderWrapperw:initList){ w.func.init(); } //... }这里使用 SPI 加载 InitFunc 的实现,大家可以在这里断个点,可以发现这里加载了
CommandCenterInitFunc类和HeartbeatSenderInitFunc类。
前者是客户端启动的接口服务,提供给 dashboard 查询数据和规则设置使用的。后者用于客户端主动发送心跳信息给 dashboard。
我们看 HeartbeatSenderInitFunc#init 方法:
@Override publicvoidinit(){ HeartbeatSendersender=HeartbeatSenderProvider.getHeartbeatSender(); if(sender==null){ RecordLog.warn("[HeartbeatSenderInitFunc]WARN:NoHeartbeatSender loaded"); return; } initSchedulerIfNeeded(); longinterval=retrieveInterval(sender); setIntervalIfNotExists(interval); //启动一个定时器,发送心跳信息 scheduleHeartbeatTask(sender,interval); }这里看到,init 方法的第一行就是去加载 HeartbeatSender 的实现类,这里又用到了 SPI 的机制,如果我们添加了 sentinel-transport-simple-http 这个依赖,那么 SimpleHttpHeartbeatSender 就会被加载。
之后在上面的最后一行代码,启动了一个定时器,以一定的间隔(默认10秒)不断地发送心跳信息到dashboard 应用,这个心跳信息中就包含应用的名称、ip、port、Sentinel 版本 等信息。而对于 dashboard 来说,有了这些信息,就可以对应用进行规则设置、到应用拉取数据用于页面展示等。
Sentinel 在客户端并没有使用第三方 http 包,而是自己基于 JDK 的 Socket 和 ServerSocket 接口实现了简单的客户端和服务端,主要也是为了不增加依赖。
Sentinel 中秒级 QPS 的统计问题
以下内容建立在你对于滑动窗口有了较为深入的了解的基础上,如果你觉得有点吃力,说明你对于Sentinel 还不是完全熟悉,可以选择性放弃这一节的内容。
我们前面介绍了滑动窗口用在 分 维度的数据统计上,当我们在说 QPS 的时候,当然我们一般指的是秒维度的数据。当然,你在很多地方看到的 QPS 数据,其实都是通过分维度的数据来得到的,包括metrics 日志文件、dashboard 中的 QPS。
下面,我们深入分析秒维度数据统计的一些问题。
在开始的时候,我们说了 Sentinel 统计了 分 和 秒 两个维度的数据:
1、对于 分 来说,一轮是 60 秒,分为 60 个时间窗口,每个时间窗口是 1 秒;
2、对于 秒 来说,一轮是 1 秒,分为 2 个时间窗口,每个时间窗口是 0.5 秒;
如果我们用上面介绍的统计分维度的 BucketLeapArray 来统计秒维度数据可以吗?答案当然是不行,因为会不准确。
设想一个场景,我们的一个资源,访问的 QPS 稳定是 10,假设请求是均匀分布的,在相对时间 0.0 -1.0 秒区间,通过了 10 个请求,我们在 1.1 秒的时候,观察到的 QPS 可能只有 5,因为此时第一个时间窗口被重置了,只有第二个时间窗口有值。
这个大家应该很容易理解,如果你觉得不理解,可以不用浪费时间在这节了
所以,我们可以知道,如果用 BucketLeapArray 来实现,会有 0~50% 的数据误差,这肯定是不能接受的。
那能不能增加窗口的数量来降低误差到一个合理的范围内呢?这个大家可以思考一下,考虑一下它对于性能是否有较大的损失。
大家翻开 StatisticNode 的源码,对于秒维度数据统计,Sentinel 使用下面的构造方法:
//2个时间窗口,每个窗口长度0.5秒 publicArrayMetric(intsampleCount,intintervalInMs){ this.data=newOccupiableBucketLeapArray(sampleCount,intervalInMs); }OccupiableBucketLeapArray 实现类的源码并不长,我们大概看一眼,可以发现它的
newEmptyBucket 和 resetWindowTo 这两个方法和 BucketLeapArray 有点不一样,也就是在重置的时候,它不是直接重置成 0 的。
所以,我们要大胆猜测一下,这个类里面的 borrowArray 做了一些事情,它是
FutureBucketLeapArray 的实例,这个类和前面接触的 BucketLeapArray 差不多,但是加了一个Future 单词。这里我们先仔细看看它。
它和 BucketLeapArray 唯一的不同是,它覆写了下面这个方法:
@Override publicbooleanisWindowDeprecated(longtime,WindowWrap<MetricBucket> windowWrap){ //Tricky:willonlycalculateforfuture. returntime>=windowWrap.windowStart(); }我们发现,如果按照它的这种定义,在调用 values() 方法的时候,所有的 2 个窗口都是过期的,将得不到任何的值。所以,我们大概可以判断,给这个数组添加值的时候,使用的时间应该不是当前时间,而是一个未来的时间点。这大概就是 Future 要表达的意思。
我们再回到 OccupiableBucketLeapArray 这个类,可以看到在重置的时候,它使用了 borrowArray 的值:
@Override protectedWindowWrap<MetricBucket>resetWindowTo(WindowWrap<MetricBucket>w, longtime){ //Updatethestarttimeandresetvalue. w.resetTo(time); MetricBucketborrowBucket=borrowArray.getWindowValue(time); if(borrowBucket!=null){ w.value().reset(); w.value().addPass((int)borrowBucket.pass()); }else{ w.value().reset(); } returnw; }所以我们大概可以猜一猜它是怎么利用这个 FutureBucketLeapArray 实例的:borrowArray 存储了未来的时间窗口的值。当主线到达某个时间窗口的时候,如果发现当前时间窗口是过期的,前面介绍过,会需要重置这个窗口,这个时候,它会检查一下 borrowArray 是否有值,如果有,将其作为这个窗口的初始值填充进来,而不是简单重置为 0 值。
有了这个思路,我们再看 borrowArray 中的值是怎么进来的。
我们很容易可以找到,只可能通过这里的 addWaiting 方法设置:
@Override publicvoidaddWaiting(longtime,intacquireCount){ WindowWrap<MetricBucket>window=borrowArray.currentWindow(time); window.value().add(MetricEvent.PASS,acquireCount); }接下来,我们找这个方法被哪里调用了,找到最后,我们发现只有 DefaultController 这个类中有调用。
这个类是流控中的 “快速失败” 规则控制器,我们简单看一下代码:
@Override publicbooleancanPass(Nodenode,intacquireCount,booleanprioritized){ intcurCount=avgUsedTokens(node); if(curCount acquireCount>count){ //只有设置了prioritized的情况才会进入到下面的if分支 //也就是说,对于一般的场景,被限流了,就快速失败 if(prioritized&&grade==RuleConstant.FLOW _GRADE _QPS){ longcurrentTime; longwaitInMs; currentTime=TimeUtil.currentTimeMillis(); //下面的这行tryOccupyNext非常复杂,大意就是说去占有"未来的"令牌 //可以看到,下面做了sleep,为了保证QPS不会因为预占而撑大 waitInMs=node.tryOccupyNext(currentTime,acquireCount,count); if(waitInMs<OccupyTimeoutProperty.getOccupyTimeout()){ //就是这里设置了borrowArray的值 node.addWaitingRequest(currentTime waitInMs,acquireCount); node.addOccupiedPass(acquireCount); sleep(waitInMs); //PriorityWaitExceptionindicatesthattherequestwillpass afterwaitingfor{@link@waitInMs}. thrownewPriorityWaitException(waitInMs); } } returnfalse; } returntrue; }看到这里,我其实还有很多疑问没有被解开 !!!
首先,这里解开了一个问题,就是这个类为什么叫 OccupiableBucketLeapArray?
Occupiable 这里代表可以被预占的意思,结合上面 DefaultController 的源码,可以知道它原来是用来满足 prioritized 类型的资源的,我们可以认为这类请求有较高的优先级。如果 QPS 达到阈值,这类资源通常不能用快速失败返回, 而是让它去预占未来的 QPS 容量。
当然,令人失望的是,这里根本没有解开 QPS 是怎么准确计算的这个问题。
下面,我思路倒回来,我来证明 Sentinel 的秒维度的 QPS 统计是不准确的:
publicstaticvoidmain(String[]args){ //下面几行代码设置了QPS阈值是100 FlowRulerule=newFlowRule("test"); rule.setGrade(RuleConstant.FLOW _GRADE _QPS); rule.setCount(100); rule.setControlBehavior(RuleConstant.CONTROL _ BEHAVIOR _ DEFAULT); List<FlowRule>list=newArrayList<>(); list.add(rule); FlowRuleManager.loadRules(list); //先通过一个请求,让clusterNode先建立起来 try(Entryentry=SphU.entry("test")){ }catch(BlockExceptione){ } //起一个线程一直打印qps数据 newThread(newRunnable(){ @Override publicvoidrun(){ while(true){ System.out.println(ClusterBuilderSlot.getClusterNode("test").passQps()); } } }).start(); while(true){ try(Entryentry=SphU.entry("test")){ Thread.sleep(5); }catch(BlockExceptione){ //ignore }catch(InterruptedExceptione){ //ignore } } }跑一下代码,然后观察下输出,QPS 数据在 50~100 这个区间一直变化,印证了我前面说的,秒级QPS 统计是极度不准确的。
小结
本文比较简单,大家应该很快就可以看完了,欢迎大家反馈阅读感受,有什么需要改进的欢迎提出。
提示:关注 转发本文 私信我“资料”,可获取更多电子书、技术教程、视频、大厂面试题等学习资料。
,


























