©原创作者 | 三金
写在前面目前短视频行业越来越火爆,推荐算法、广告算法引擎已经成为了各个大厂的核心业务系统。在此背景下,字节跳动的搜索团队就主要负责抖音、今日头条、西瓜视频等产品的搜索算法创新和架构研发工作。今天小编给大家介绍便是搜索团队的算法工程师岗位。
01 岗位介绍岗位名称:
算法工程师(搜索广告方向)
工资待遇:
35K-65K
岗位要求:
1)出色的发现、分析、建模、解决问题的能力;良好的团队合作意识和沟通能力;关注用户体验;
2)扎实的代码能力、数据结构和基础算法功底,熟悉Linux开发环境,熟练使用C 和Python语言;
3)熟悉至少一种主流深度学习编程框架(TensorFlow/PyTorch/MXNet),熟悉常用的深度学习算法 ;
工作地点:
上海/北京
从上述岗位介绍可以发现,算法工程师(搜索广告方向)薪酬较高,且可选工作地点为国内最发达的两座城市。对于岗位要求而言,其要求较为模糊,例如要求“熟悉常用的深度学习算法”,而并没有写明要求熟悉与该岗位相关的推荐算法等。值得注意的是该岗位没有学历背景要求,意味着本科生也可以进行投递。
02 面经干货面经来源:小红书(ID:茶语西瓜客)
A、一面
1. 编程题:关于二分查找。
AI面试指南参考答案:
编程题建议着重刷Leetcode HOT 100题库以及《剑指Offer》。
2. 编程题:完成一个函数,输入A、 B两个等长的0-1序列,返回max(j-i)使得sum(A[i:j]) == sum(B[i:j])
AI面试指南参考答案:
编程题建议着重刷Leetcode HOT 100题库以及《剑指Offer》。
3. 讲一讲简历上的项目。
AI面试指南参考答案:
首先要一句话介绍背景,然后介绍项目是怎么做的,最后介绍效果如何。此外还注意项目的创新点、衡量指标、你的贡献等。
4.如何判断模型是否出现了过拟合,如何判断线上效果不好是过拟合导致的还是数据分布不一致导致的。
AI面试指南参考答案:
1)过拟合即模型训练和验证数据集上都表现得很好,但是在测试数据集上却表现得很差。
2)进行数据重采样,例如上采样,若效果仍不好,则说明是过拟合导致的,反之则是数据分布不一致。
5.如何抑制过拟合?
AI面试指南参考答案:
1)从数据入手进行数据增强,从而学习到更多的特征,减少噪声的影响;
2)降低模型的复杂度,例如使用dropout、Eearly Stopping、剪枝等方法;
3)使用正则化方法,例如L1正则化、L2正则化;
4)使用集成方法,例如Bagging方法。
6.L1、L2哪一个使权重产生稀疏化?
AI面试指南参考答案:
L1使权重产生稀疏化。从导数角度来看,L1正则求导后,损失函数在0处是极小值,所以优化的时候会更容易得到权重等于0,而L2正则求导后,极小值不在0处。
B、二面
1. 编程题:不用二分、不用牛顿迭代,求解开根号问题?
AI面试指南参考答案:
使用梯度下降方法,其迭代公式如下所示,其中x为初始值,lr为学习率:

2.旋转不降数组,找到第一个不大于target值的数字的下标。
AI面试指南参考答案:
思路:二分查找法
3.文本匹配如何改进效果,从哪里入手?
AI面试指南参考答案:
选择合适的模型,例如BERT。利用BERT模型对文本进行向量化表示, 解决Word2Vec一词多义的问题, 使用Transformer编码器对文本进行特征提取, 获取文本内部信息, 并考虑两个文本之间的多层次交互信息, 最后由拼接向量推理计算出两个文本之间的语义匹配度。
4.文本分类如何进一步改进模型?
AI面试指南参考答案:
不同的文本分类场景使用不同的模型,目前BERT是文本分类任务最常用的模型。对于BERT的改进可以从以下几个方面进行:
1)从预训练模型进行改进,即采用不同的预训练模型,例如ALBERT、RoBERT等,一方面可以加快模型训练速度,使其收敛更快,另一方面通常可以使模型达到更好的效果;
2)改进[Mask]策略,从而使结果更加精准。例如,原始的BERT使用的是subword维度,改进后的BERT WWM(Google)是按照whole word维度进行mask,能够进一步学习词之间的关系。
3)在保持BERT模型分类性能的同时,进行模型压缩,从而减少推断时间以及内存开销。例如通过知识蒸馏的方法训练小模型。
5. WGAN的推土机损失
AI面试指南参考答案:
WGAN使用的是推土机距离(wasserstein_loss),即目标值与预测值乘积的均值。
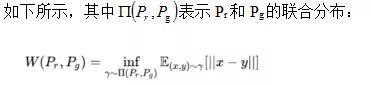
C、三面
1.项目介绍,有哪些难点,怎么解决的?
AI面试指南参考答案:
考察项目的熟悉度。
2.使用Int8量化时,如何防止数值溢出?
AI面试指南参考答案:
1)在计算卷积的时候,使用Int32作为中间值。因为Int8进行乘加操作后结果不会超出Int32范围。
2)通过线性映射的方法,即在带偏置的层中,先将Int8转为Float32计算出结果,再转为Int8。
3.ALBERT相对于BERT有哪些优点与改进。
AI面试指南参考答案:
ALBERT是轻量级BERT,ALBERT采用了一种因式分解的方法从而大幅度减少了BERT的模型参数,解决了参数过多超出内存导致无法将网络加深、加宽的问题。
4.优化BERT本身结构进而实现加速的模型。
AI面试指南参考答案:
1)DistilBERT:在BERT的基础上用知识蒸馏技术训练出来的小型化BERT。
2)ALBERT :轻量级BERT,采用了一种因式分解的方法,从而大幅度减少了BERT的模型参数;
3)TINYBERT:在DistilBERT的基础上做了改进——针对Transformer结构的知识蒸馏以及针对pre-training和fine-tuning两阶段的知识蒸馏。
5. BERT模型蒸馏是如何做的?
AI面试指南参考答案:
1)精调阶段蒸馏。例如在Distilled BiLSTM中,教师模型采用精调过的BERT-large,学生模型采用BiLSTM ReLU进行蒸馏,蒸馏的目标是hard labe的交叉熵和logits之间的MSE。
2)蒸馏隐层知识。例如BERT-PKD是从教师模型的中间层提取知识,从而避免了蒸馏最后一层导致过拟合的风险。
3)预训练阶段进行蒸馏。例如DistillBERT是在预训练阶段进行知识蒸馏,新增加了一个损失函数——cosine embedding loss。
4)蒸馏注意力矩阵。例如MiniLM只蒸馏最后一层,并且只蒸馏教师、学生两个矩阵的KL散度。
6.判重项目,非Bert模型与Bert模型是如何结合的,bagging吗?
AI面试指南参考答案:
两种模型一般是如何结合的?
可以通过模型融合的方法,例如
1)简单的加权融合;
2)通过集成学习的方法。
7.模型集成有哪些手段,各自的优缺点是什么,有哪些应用的场景。
AI面试指南参考答案:
1)Boosting方法:训练基分类器使用串行的方式,即分而治之,大部分情况下,经过 boosting 得到的结果偏差(bias)更小,缺点是数据不平衡导致分类精度下降,训练比较耗时。例如Adaboost 和 Gradient boosting。
2)Bagging方法:训练基分类器使用并行的方式,即集体投票决策,大部分情况下,经过 bagging 得到的结果方差(variance)更小,缺点数据样本量小的时候性能表现较差,而且有时未必能保证基分类器之间相对独立,例如随机森林。
8.时间序列模型有哪些?
AI面试指南参考答案:
1)使用RNN来做CTR预估的模型。其中RNN适用于有序列(时序)关系的数据,CTR预估重点用于学习组合特征。
2)DeepFM模型。该模型兼顾了低阶和高阶特征,可以处理搜索广告中与时间序列相关的数据。
9.场景题:抖音场景下,措建一个搜索广告系统,如何平衡一个广告的商业价值和用户体验呢?
AI面试指南参考答案:
主要从两个方面考虑:1、让用户不用思考;2)不能引发用户的防备。
例如打开APP之前的广告展示,时间不能太长,广告内容可以与用户经常搜索的内容相关。
10.如何优化广告搜索场景中的“相关性”?
AI面试指南参考答案:
通过用户行为、用户信息、时空信息、用户的输入、视频文字理解等海量特征来找出符合用户需求的结果。
11.代码题:正则表达式匹配
AI面试指南参考答案:
1)思路一:回溯法,搜索全部场景匹配。
2)思路二:动态规划。
相似例题参考:https://blog.csdn.net/kayle1995/article/details/106487236
03 结语看完上面的面经,你觉得难度系数几颗星呢?小编提醒,在这份面经干货中,三次面试都有问到编程题,由此可见刷题的重要性!建议大家着重刷Leetcode HOT 100题库以及《剑指Offer》。
此外,大家对自己简历上的项目一定要十分熟悉,面试官可能会根据项目进行深入提问,特别是技术路线、衡量指标等细节。
最后,希望屏幕前的你能够成功上岸!
私信我领取目标检测与R-CNN/数据分析的应用/电商数据分析/数据分析在医疗领域的应用/NLP学员项目展示/中文NLP的介绍与实际应用/NLP系列直播课/NLP前沿模型训练营等干货学习资源。
,




