孙宏达:
中国人民大学高瓴人工智能学院直博三年级,研究兴趣包括药物发现、机器学习、自然语言处理等。
报告简介
人工智能赋能的药物推荐已成为医疗保健研究领域的一项重要任务,它为帮助人类医生提供更准确、更高效的药物处方提供了额外的视角。通常,药物推荐是基于病人在电子健康记录中的诊断结果做出决策。我们假设在药物推荐中需要解决三个关键因素:1)消除由于可观察信息的限制导致的推荐偏差;2)更好地利用历史健康状况;3)协调多种药物以控制安全性。为此,我们提出了 DrugRec,一种基于因果推断的药物推荐模型。该因果图模型可以通过前门调整来识别和消除推荐偏差。同时,我们在因果图中对多轮就诊进行建模,以表征病人的历史健康状况。最后,我们将药物-药物相互作用 (DDI) 建模为可满足性 (SAT) 问题,解决该 SAT 问题有助于更好地协调推荐。实验结果表明,我们提出的模型在广泛使用的电子病历数据集 MIMIC-III 和 MIMIC-IV 上实现了最优的性能,证明了我们方法的有效性和安全性。
任务定义
药物推荐和一般商品推荐具有很强的相似性,比如 user-item 与 patient-drug 的对应关系,但同时也具有重要区别。
药物推断的整体框架是根据病人当前健康状态以及历史就诊信息来给病人当前就诊开处方,其中涉及到的关键实体有症状 (symptom, S),诊断疾病 (diagnosis, D),手术 (procedure, P) 和药物 (medication, M)。
从病人的第二次就诊开始,我们就需要考虑病人先前就诊中的健康状态以及开药结果等历史信息。我们跟踪病人 j 的第 t 次就诊记录,将其用以下形式表示:

总结起来,忽略特定病人的上标,我们的输入可分为以下三部分。
1) 病人的当前健康状态:

2) 病人的历史就诊信息:

3) 推荐药物组合的安全性信息。如药物 u 和药物 v 不能同时服用,我们用 drug-drug interactions (DDI) 的关系来表示:

在推荐安全性这一关键点上,药物推荐和商品推荐具有明显差异。我们在药物推荐过程中需要控制DDI的出现比例,即使得推荐药物之间的副作用越少越好。药物推荐模型的输出是针对各种药物的推荐概率。
挑战与动机
药物推荐当前所面临的几项挑战:
1) 有时记录中的诊断信息不足以充分描述病人的健康状况,由于可观察到的信息局限性,可能会导致推荐偏差。我们需要考虑病人潜在而有价值的诊断信息做去偏的药物推荐 (Debiased);
2) 利用带有偏差的历史推荐信息的序列建模可能导致误差的进一步累积。我们需要更好地利用病人的历史信息进行去偏药物推荐 (Longitudinal);
3) 药物间副作用 (DDI) 的大量存在会影响药物的安全性。我们需要尽量降低 DDI 对药物安全性造成的影响 (Coordinated)。
综上,我们根据这三个挑战提出了针对性的三个方面的药物推荐建模方案:Debiased, Longitudinal, and Coordinated Drug Recommendation.
背景
在正式介绍我们的药物推荐方案以前,我们首先从一个因果图的简例开始入手,了解后续涉及到的因果推断的基本知识。
因果图中的关键变量

在这个图模型中,主要关注的是treatment变量 T 到outcome变量 Y 的影响。如果忽略 C 的存在,只考虑 T-W-Y 这一条路径,这样的建模方法体现的是 T与Y 之间的关联关系,用条件概率表示,而它不能体现 T到Y 的因果关系。
上述因果图中具有两种路径:前门路径和后门路径。前门路径为背向treatment变量 T 的路径,即 T-W-Y,而后门路径为指向treatment变量 T 的路径,即 T-C-Y。其中 W 作为mediator变量,与混淆因子 C 没有直接的连边。由于 C 的存在,建模 T到Y 的因果关系需要对 T 进行一个干预的操作,即切断所有到达 T 的路径,并将 T 的变量设为某个固定值 t。通过干预我们就可以识别 T到Y 的因果关系,而非相关关系。相应地,我们将传统的条件概率替换为以下的干预概率:

这个概率也可以直观地反映了 T对Y 的因果效应。
因果药物推荐
接下来的问题是如何将因果的方法合理应用到药物推荐这个具体的下游任务场景中。我们参考模拟了现实医生开处方的过程,设计出如下的药物推荐因果图。根据现实医生“对症下药”的逻辑,我们以症状 (S) 作为treatment变量,以推荐结果 Y 作为outcome变量。首先,需要先根据病人的症状记录其诊断结果(诊断疾病 D 与手术 P),然后将病人全部的健康状态信息 (S, D, P) 整合为病人当前访问表示 R,最后针对是否推荐给定药物 (M) 做出决策 (Y)。

我们在药物推荐方案上的创新点在于将不可观测的关键信息导致的推荐偏差作为混淆因子 C,考虑其在药物推荐中的影响作用。C 同时作用在 S 和 Y 上,形成了一条后门路径。由于 C 的存在,为了识别 S到Y 的真正因果效应,需要对 S 进行干预操作。
因果图中的因果效应并不总是可识别的,需要保证建模的是可识别的因果效应。我们验证了药物推荐因果图满足前门准则的三个条件,以证明 S到Y 的因果效应是可识别的。识别因果效应的关键是去除干预概率中的 do算子,将其转换为可计算的条件概率求和形式。具体地,我们使用前门调整公式,将 S到Y 的因果效应表示为:

多轮因果药物推荐
以上建立的因果图其实是基于单次药物推荐的场景,如何利用病人的历史健康信息是我们建模的第二个关键点,即如何把因果效应从 singal visit 拓展到 multi-visit。
我们针对 multi-visit 药物推荐提出了两种建模方案:
1) DrugRec-a
将历史的就诊变量 (S, D, P, Y) 表示压缩到一个历史因果图中,在为第t次就诊推荐药物时把第1次到第t-1次的信息整合为一个表示,再将整合的表示和当前的信息进行链接,就可以识别联合的因果效应:

我们发现最终的推荐概率推导结果中,病人历史药物推荐的概率部分和当前药物推荐的概率部分是可分离的。
2) DrugRec-k
只考虑距当前就诊最近的前k次的历史信息,因为再之前的历史就诊数据由于距今时间过久,对当前的开处方决策没有显著影响,甚至可能有一定的信息是误导性的。以症状S为例,该方案的具体链接路径如下:

类似于DrugRec-a,DrugRec-k中可以识别如下的联合因果效应,并具有类似的分离概率结果。

Controllable DDI with 2-SAT
为了减少 DDI 的出现比例,我们设计了一种创新的方案来保证药物推荐的安全性。首先,成对的 DDI 关系被储存在一个医疗知识图谱 A 中。若 Auv 的取值为1,药物 u 和药物 v 之间存在 DDI 的不良影响;若为0,则没有影响。
传统的方法通过设计 DDI-related training loss 来考虑 DDI 的影响:

对于具有 DDI 关系的两种药物,该训练目标最小化它们二者同时推荐的概率以控制 DDI 的产生。然而,这样的处理影响到二者各自的最终推荐概率,并且在出现 DDI 矛盾时无法给出更倾向于保留或移除的药物。
因此,我们考虑在 inference 阶段对 DDI 的问题进行后处理。我们巧妙将 DDI 的关系转化成了二元可满足性 (2-SAT) 问题,即给定若干命题逻辑表达式作为条件,判断一组布尔变量是否有解的问题。我们将是否推荐某一种药物作为一个布尔变量,每个 DDI 的关系可以用二元命题逻辑表达式表示,即二者不同时推荐,如

2-SAT 问题已被证明是多项式时间可解的,通过求解 2-SAT 问题,就可以在药物推荐结果中控制 DDI 的出现。然而,即使已知解是存在的,还是需要可以尽可能地找到最优解,对应最准确的药物推荐结果。如果模型过于保守而不推荐任何药物,即所有布尔变量取值为0形成平凡解,它虽然符合所有的 DDI 条件,但并没有任何意义。因此,传统的 SAT求解工具并不能满足药物推荐的特定需求,我们设计了一个新的启发式算法,结合了先前药物推荐的结果,来获得该 2-SAT 问题更准确的非平凡解。具体的求解方法大致分为以下几个部分:
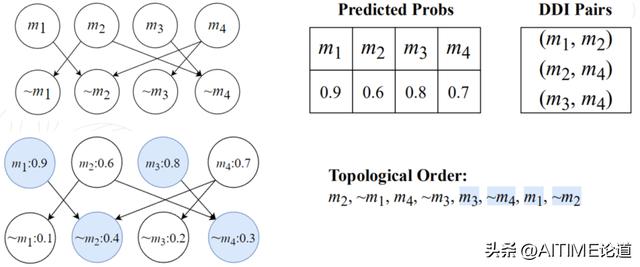
1) 为每个布尔变量分配两个节点,并基于DDI关系构建逻辑图。
2) 利用 Tarjan算法找到图中所有的强连通分量 (SCC),其中一个 SCC 如下图例所示。

3) 对每个 SCC 做启发式的拓扑排序。
结合因果图输出的推荐概率,我们每次在寻找入度为0的节点时不再随机,而是优先从推荐概率小的开始循环,这样的启发式算法可以增强拓扑排序的结果。最终,我们在拓扑排序的后置位上得到最终结果,在出现 DDI 的矛盾时,我们成功地保留推荐概率相对较大的药物 m1 和 m3,舍弃推荐概率相对较小的药物 m2 和 m4,实现了推荐上的优化。
模型框架
整个模型框架分为四个模块:(a) 输入表示;(b) 更新网络;(c) 评分网络;(d) 基于 2-SAT 的可控 DDI。

输入表示

对于输入表示,我们分别用了两层的 Transformer encoder 来处理症状 (S)、诊断疾病 (D) 和手术信息 (P)。每个药物有对应分子的 SMILES 编码,我们使用一个分子的预训练模型对 SMILES 进行处理来得到它的初始表示。
更新网络
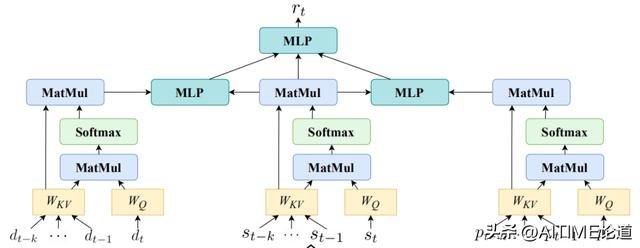
对于更新网络,我们以第二种多轮建模方案 DrugRec-k 为例,通过Attention机制来建模过去 k 次的信息对于当前第t次信息的影响。之后,我们再将三方面的信息整合到当前的病人就诊表示 rt 中。
评分网络
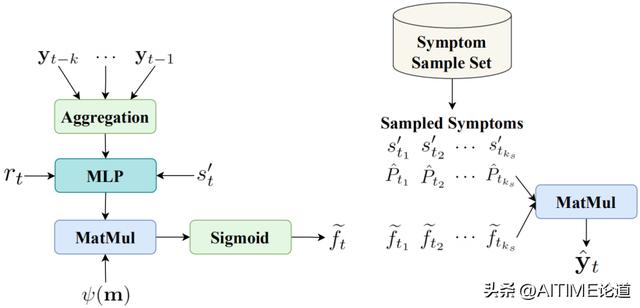
对于评分网络,我们使其融合了当前药物的表示、更新网络中的病人就诊表示 rt 和症状集抽取的症状表示 st’ 这三部分信息,实现最终的药物推荐概率预测。
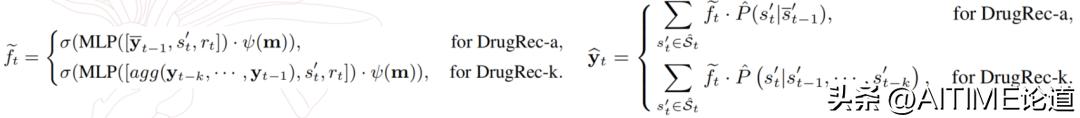
训练目标
对于训练目标,我们共引入了以下几方面的 loss:
1)Recommendation accuracy

2)Coordination of drug combination
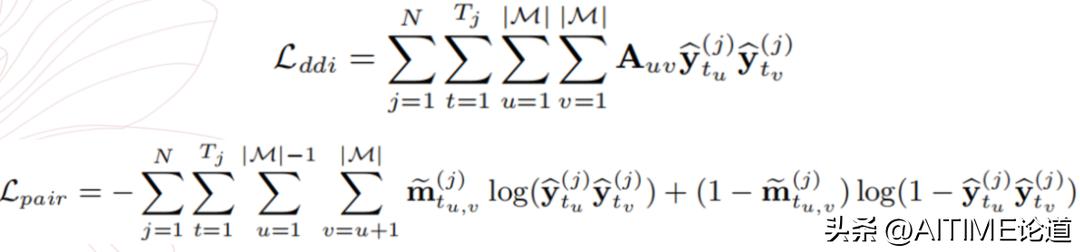
3)Average treatment effect (ATE)
我们创新地引入一个基于因果推荐的 loss,旨在最大化观测症状的效应和什么都观测不到情况下效应的差异 ATE 来实现推荐药物的优化。

Controllable overall loss
最终,整体的 loss 会根据 DDI 的实时取值来做一个动态的调整。
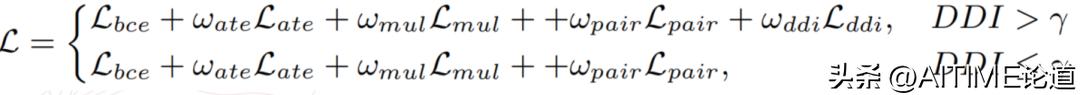
实验
数据集:
Benchmark MIMIC-III / MIMIC-IV
评估指标:
Effectiveness:Jaccard, F1, PRAUC
Safety: DDI Rate
主实验

由上表主实验的结果可知,我们在推荐准确率的指标上达到了最优的结果,并且DDI的比例也有明显下降,甚至可以低于ground truth中DDI的比例。
消融实验分析

消融实验结果表明我们对于 Debiased, Longitudinal, Coordinated 三方面的药物推荐建模都是有必要的。
关键超参数分析

下面,我们还对 DrugRec-k 建模方案中 k 值的选取作为关键超参数的研究。我们选取 k=1,k=2和k=3三种模型方案,并将测试集按病人的总就诊次数 (2, 3, >3) 进行分组。综合来看,k=2 时的表现在各组中基本是最优的。这也证实了对病人历史信息的建模并不一定是考量越多次就诊信息效果就越好,相距时间越久的历史信息的影响会越小,甚至带有误导性。
总结
1) 我们首次为药物推荐设计专门的因果图模型,并通过识别因果图中的因果效应缓解药物推荐偏差,达到更好的推荐效果。
2) 我们设计了两种建模方案来将因果图的建模拓展到多种推荐,更好地利用了病人的历史信息做多轮药物推荐。
3) 我们将DDI问题建模成了一个二元可满足性问题,然后实现了药物安全性的控制。同时,我们还采用了启发式算法来优化推荐结果。
,




