英伟达在去年的GTC 2022上,推出了Grace CPU Superchip。这是在原有的Grace CPU基础上做了进一步的扩展,将两个Grace CPU封装在一起。其使用了Arm的Neoverse N2平台,支持PCIe 5.0、DDR5、HBM3、CCIX 2.0和CXL 2.0等特性。
近日,英伟达官方介绍了Grace CPU Superchip的设计、性能和能效。

Grace CPU Superchip采用了台积电4N工艺制造,共有144个Arm v9架构CPU内核,以4个128位的方式配置了两组SIMD矢量指令集,分别是SVE2和NEON,每核心64KB一级指令缓存、64KB一级数据缓存、1MB二级缓存,所有核心共享234MB三级缓存。利用英伟达设计的可扩展一致性总线(SCF),这种网状结构和分布式缓存架构,通过3.2TB/s的超高带宽,实现内核、NVLink-C2C、内存和I/O之间的联通。
Grace CPU Superchip支持带有ECC校验功能的LPDDR5x内存,带宽达到了1TB/s,最大容量为960GB;配备了8组PCIe 5.0 x16接口,总带宽1TB/s,还有用于管理的额外低速PCIe通道;通过英伟达最新的NVLink-C2C进行连接,提供了900 GB/s的连接带宽,以保证芯片到芯片互联之间的低延迟和一致性,并允许连接的设备在同一个内存池上工作;支持Arm的AMBA CHI协议,支持与其他互连处理器完全一致且安全的加速器;TDP为500W。
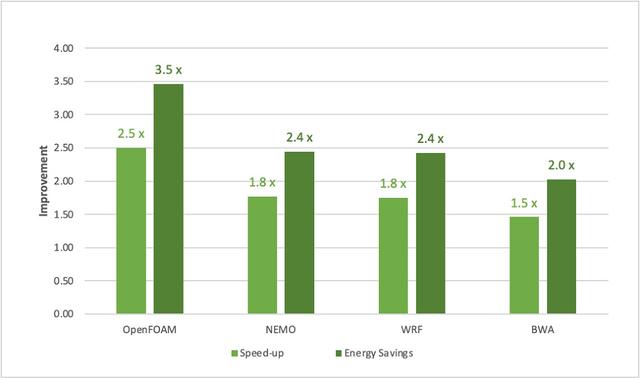
英伟达称,Grace CPU Superchip的FP64峰值运算性能达到了7.1TFlops。相比于AMD基于Zen 3架构的EPYC 7763处理器(64核心)搭建的双路系统,Grace CPU Superchip性能是其1.5至2.5倍,能效是其2至3.5倍。
英伟达表示,Grace CPU Superchip旨在为AI和高性能计算应用设计,可以运行所有英伟达软件堆栈和平台,包括了NVIDIA RTX、HPC、NVIDIA AI和NVIDIA Omniverse。通过NVLink-C2C技术,可以创建由CPU、GPU、DPU、NIC和SoC等不同类型的小芯片构建的集成产品。由于支持最新推出的UCIe规范,未来其定制芯片可以选择使用UCIe或NVLink-C2C的方式进行互连。
,




