
Mysql中可以通过explain来查看一个sql的执行计划,通常结果如下

这里我们来详细介绍下执行计划中type的含义,它是表示mysql如何去获取数据的,类型有多种,按照性能来看结果如下
null->system->const->eq_ref->ref->fulltext->ref_or_null->index_merge ->range->index->ALL
一般我们看到type在range之下就表示或许有优化的余地,但优化也要按照实际情况去做,并不是说看到all了就说明sql一定有问题,比如我们去查询一个数据量小的堆表那type肯定就是all了,但数据只有10条,所有要进行sql优化首先要对各个参数都非常了解之后,还要根据实际情况来优化。
All全表扫描,这个比较简单明了,就是整个表数据都用到了,所有就是scan,一般如果有某个表只是需要一部分少量数据,但是该表却用了scan,并且影响到性能了,那就有优化的必要了,但如果该表很小 或者并没导致性能下降,那么scan也问题不大。总之针对执行慢的sql ,如果发现有all出现,就要引起我们的注意
explain
SELECT * FROM sakila.city

全索引表扫描,这里注意是全索引表,也就是整个索引都用到了,只不过不是scan表数据,而是遍历整个索引表,我们在来看下city表中city_id是主键,如果我们需要通过该主键查找数据是不用遍历整颗索引树的,但我们如果要排序呢? 看下面sql
SELECT *
FROM sakila.city
order by city_id;

很显然,这里用到了index,但这个sql是需要优化的吗? 答案是不需要,而且这个sql还是最好的,不信我们换个排序字段试试
explain
SELECT * FROM sakila.city
order by city

对同样的数据进行排序,使用不同的字段排序所消耗的资源是不同的,用主键排序 虽然是index 但其实它节省了sort的开支,而使用非主键字段排序则需要额外的sort损耗,看第二个图中 Extra字段 显示了 Using filesort,这个操作是非常耗资源的,也是我们日常sql优化的重点
Range对索引进行范围查找,这里重点是查询使用到索引了,并且数据肯定在总数据中占比较小,能从索引中使用一个较小范围获得数据,哪怕数据是分散的。
City表数据一共有600条记录,city_id 从1自增到600,我们先写个sql来展示range使用
explain
SELECT * FROM sakila.city
where country_id <10
;

我们看到type的确是range,我们把10 改成50看下效果
explain
SELECT * FROM sakila.city
where country_id <50
;

就是将数字变化一下,但执行计划似乎全变了,首先type变成了all,也就是全表扫描了,或许查询引擎认为都50了总条数才600,那就直接扫描表吧不用再费劲走索引了,注意两个图的filtered字段和extra字段, filtered是我们需要的数据和实际返回的数据的比例,这里应该我们需要50条但实际返回了600条,比例45.83 并不正确,注意这里也是给你一个评估值,我们可以参考,当filtered不是100%时候,就提醒我们要注意了,extra 的值也是从using index condition变了 using where,前者对索引进行筛选,后者是使用书签查找,具体细节大家可以从网上查找,注意这些都是给我们的提示,并不一定说using where 一定慢,而using index condition就一定快,还是要实际问题实际分析。
INDEX_MERGE合并索引,使用多个索引搜索条件的的结果进行交集运行,比如city表中country_id是一个索引,city也是一个索引那么下面的语句就会将两个索引的结果先交集运算,再用这个交集去取数据
explain
SELECT * FROM sakila.city
where country_id =10
or city like 'a%'
;

和ref类似,只不过多了一个null的判断,ref即先从非聚集索引中获取所需数据范围,但是又有字段并不再索引中,需要跳转到聚集索引获取其他字段数据,也就是我们说的书签跳转,我们来看你下面的sql
explain
SELECT * FROM sakila.city
where country_id =1
or country_id is null;

注意这里 country_id 是一个非唯一的非聚集索引,并且country_id是可以为空的,所以才能用到ref_or_null,如果country_id不为空,则使用的是 ref,哪怕我们sql中有or country_id is null; 也是如此
Fulltext查询过程中用到了fulltext索引,一般我们是用不到这个的,当我们建立了全文索引并使用它时就会使用该类型
现在我们在city表的 city字段上添加一个全文索引并进行查询
SELECT * FROM sakila.city
where match(city) against('Addis')
;


非聚集索引查询需要一次页签跳转,性能也不错
explain
SELECT * FROM sakila.city
where country_id=2;
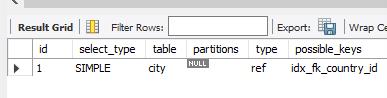
两个表关联,关联字段为一个表的主键或唯一索引,另一个表没有索引,这个时候就会在主键字段的表上使用eq_ref,比如我们有两个表 一个城市city表 一个国家country表,进行关联后,因为city表的country_id字段并没有创建相应的索引,所以执行计划就变成了先遍历city表然后用city表的country_id去country表进行关联
explain
SELECT *
FROM sakila.city as c
inner join sakila.country as co on co.country_id=c.country_id

从执行计划的顺序来看,这种执行计划的效率并不很好,如果给city表的country_id添加一个索引后,效率会提高很多,而且这种情况也不复合先小表后大表的执行建议
Const使用主键或唯一索引的seek操作,返回一条数据,效率是很好的
explain
SELECT *
FROM sakila.city
where city_id=10






