一、简述
对于C语言基础相关方面的表面理解,简单介绍。
二、二进制
生活中常用的是十进制,基数0,1,2,3,4,5,6,7,8,9,。满10进1。
时钟60进制。基数0,1,2...57,58,59。满60进1。60秒为1分钟,60分钟为1小时。
计算机二进制,基数0,1。满2进1。高电平代表1,低电平代表0。计算机的指令和数据都是用0和1来表示的。
三、计算机部分组成
CPU 内存 外存。
CPU执行指令,CPU包括运算器、控制器。(包括多个寄存器)运算器负责逻辑运算,控制器包括对数据和指令的存取操作。
内存运行当前的程序(代码 数据),(代码可以看做是一系列的指令)内存可以划分为很多个单元,每个单元一个字节并对应一个编号,这个编号称为地址。(断电了就数据没了)
外存可以简单认为是硬盘。(存放数据、应用程序等,断电了数据还在)
程序运行:程序test.exe放在硬盘,CPU将test.exe读取到内存,然后逐条执行指令。
虚拟内存:操作系统为了更好、更高效地使用内存,管理内存,将实际物理内存进行了映射,对应用程序屏蔽了物理内存的细节,有利简化程序的编写。假设物理内存只有1G,有三个应用程序同时在运行,系统会将物理内存的一部分映射为3个大小均为4G的虚拟内存,让每一个应用程序都以为自己拥有4G内存(实际并不是,虚拟内存经过一定的方式映射为物理内存),这样极大地方便了应用程序的数据和代码的组织。
内存4区:栈区,堆区,全局区,代码区。

总线:计算机各部分通过总线连接。包括地址总线,数据总线,控制总线。地址总线:比如有32根地址总线,每一根线有高电平1,低电平两种状态0,那么可以表示0x00000000~0xFFFFFFFF总共2的32次方这么多个地址,一个地址可以表示一个内存单元。一般来说,地址总线越多,可以表示的地址越多。指针变量就是存放地址的,比如:int i = 10; int *p = &i;若i的地址为0x00800400;那么p指针变量存放的值就是0x00800400,是一个有实际地址意义的整数。因为是32根地址总线,所以sizeof(p) = 4 (字节)。数据总线:比如有8根数据线,那么同时可以存取8位数据,一般来说数据总线越多,同时存取的数据越多,执行效率越高。控制总线:控制、协调计算机各部分工作,存取指令。一般来说总线还可以拓展。
四、变量
内存分为一个一个单元,一个单元一个字节,并且一个单元对应一个地址编号。
在汇编语言中,可以直接对内存地址进行操作,如:MOV AL,[2000H] ;将内存地址0x2000的内容送到AL寄存器中。
汇编中,直接将数据存放到某个内存地址,如将学生学号放到某个地址,学生姓名放到某个地址。到时候读取的时候,直接读取某个地址。这样子固然程序执行效率高,但是如果数据一多,难免会记不住哪个数据对应哪个地址,看到一个地址,自己还得想一下之前这个地址(这一段内存)存放的是什么数据,写起代码也不方便。时间一长,就算是自己编写的代码都要花很多时间才能看懂,而且维护起来也比较麻烦。
这样我们将数据对应的一段内存起一个名字,这个名字就代表着一片内存,到时候直接操作着个名字就相当于操作这一片内存,这个名字就是我们所说的变量。起一个与数据相关的有意义的名字,方便我们编程。如:C语言中,我们可以将存放学生学号的那一段内存叫做id,将存放学生姓名的那一段内存叫做name。这样我们就可以通过id,name这两个变量名类读取或存储学生的id信息和姓名信息,到时候我们一看变量名name,我们就能想到这是存放姓名信息的。
变量:对应一片内存,内存可以存放不同的数据,变量,变化的量。变量的地址就是对应的那一片内存首地址。如果变量占据多个内存单元,首个内存单元的地址就是变量的地址。程序中定义一个变量就在内存中开辟一片内存空间(系统为程序分配一片内存空间,如int i = 0;在32位系统中,系统会分配4字节的内存空间,在单片机中就可能是在RAM中分配2字节(16位) )。
五、数据类型
为了方便,或者是为了执行效率,计算机采用了二进制,通过低电平或断电状态表示0,通过 通电或高电平状态表示1。这样一来,计算机只认识0和1,也只能表示0和1。那么我需要表示其他数字:2,3,4....字符:a,b,c...怎么办?我们可以使用多个0和1来代表其他数字和字符,并统一为一个表。
..............00110000
数字000110001
数字100110010
数字2...............01000100
大写字母D01000101
大写字母E................
在内存中,表达整数0我们可以用 00110000,表达整数4亿我们可以用 00111111100011000011110。
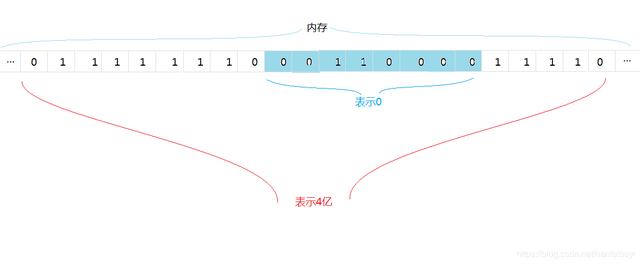
上面这样子表示,我们可以知道这一段的0和1表示这整数0,那一段0和1表示4亿,但是实际上我们“看”不到内存,我们不知道从这个位置开始,到哪里结束表示着一个数据。我们需要明确规定多少个0和1表示一个整数,假设我们约定8位0和1表示一个整数,这样我们知道了内存首地址,往后读取8个0和1然后就可以读取到一个数据(整数)。就像加密的电报一样,"滴滴"表示1,“滴”表示0。按照多少个0和1代表一个字,才能正确的解密。

所以我们需要指定多少个0和1来表示一个数据。8个0和1可以表示2的8次方==〉256个数。要是有正负值,表示范围为-128-127。比如在32位系统中,C语言的整型int用32位即4字节表示,可以表示2的32次方==〉4294967296个数,有符号的表示范围为-2147483648——2147483647。有一些数据范围不大,只需几十个,如果用32位表示一个数据就显得浪费内存。有一些数据范围很大,用32位表示又不够表示,于是就有16位的short类型,64位的long long类型(不同的系统有可能类型的位数不一样)。就像用盒子打包物品一样,有一些物品比较小,有一些物品比较大。要是统一用一种尺寸的盒子装,盒子过小,大的物品又装不下,盒子过大,用来装小的有显得有点浪费,于是多种尺寸的盒子就产生了-多种数据类型。还有一个原因:就是在表达小数,或者是非常大的数时就算是64位也有点无能为力,但是如果改变存储方式,同样是64位,却可以表示更大范围的数。于是有了新的数据存储方式,这是针对浮点数的。(如果将整数和浮点数采用同样的存储方式,计算机结构会更加复杂化,甚至会降低执行效率)

数据的大小范围不一,整数,浮点数的存储方式不一样(读取的时候解析的方式也不一样),为了合理利用内存,提高执行效率,方便开发等原因,我们需要不同的数据类型。
不同的数据类型意味着数据的大小不同(多少位0和1表示一个数据,也就是这种数据类型占多少个字节),数据的存储方式(数据的解析方式)不同。也就是说同一个内存首地址,按照不同的数据类型,即按照不同的位数解读内存数据,就会读取出不一样的数据,按照不同的解析方式,也会读取出不一样的数据。就像加密电报一样,按照不同的位数一样的译码表也会解读出不一样的译文,按照一样的位数不一样的译码表也会解读出不一样的数据。如果仅仅知道数据的地址,不知道数据类型(包含数据大小、数据的解析方式),是无法正确解读数据的。如有一数据的首地址是0x0F48000,从这个地址开始存储着:10100011010101110100010100001011101000111011010010000101010100000101001100001010010010010110101010011
不知道数据类型,那么到哪里结束才是整个数据?就算知道了到哪里结束,又该怎么解析?(要知道还有用户构造类型--结构体类型)。因此,用地址操作数据 需要配合数据类型。
定义不同数据类型的变量,系统根据数据类型分配相应的内存大小,程序填充数据时根据相应的存储方式,读取数据时按照相应的方式解析,不然读取不到正确的数据。如float类型的数据,如果直接按照int类型数据读取,那么读取出来的不是正确的数据。如float类型的数据12.0,如果按照int类型数据解读,就得不到我们"期望"的12。

int类型存放整数,char类型存放字符,float类型存放浮点数,那么有没有一种变量是存放地址的呢?当然有--指针。
在32位系统环境,一般来说指针变量大小就是32位(4字节),那么为什么还有指针的数据类型呢?因为我们知道一个内存首地址以及数据大小,还需要确定怎么解析数据,类型就是用来指示解析/存储数据的。
六、修改内存数据
对于程序自己申请的内存,作为拥有者,可以对这一片内存进行读取或修改数据,其他程序一般没有权限读取或修改。但是可以通过一些方式可以进行修改。

七、发展历史,应用场景,编译器
对于发展历史,就有必要提及兼容性,和各种名词的由来。
有时候我们会有这种疑惑,为什么这样子设计,为什么不能简单一点呢?
有可能是为了兼容以前的版本,或者是预留拓展接口。
有时候我们会有这种疑惑,为什这样子命名?一点都不形象。
有可能是它原来就很形象的,只是它被改进了。就像刚接触电脑时,感慨电脑的功能真是强大,不愧"电脑"之称。
为什么会被叫做计算机呢?因为它本来最初设计的时候,它就是一台只会计算的机器。(原理上,它的核心也只会计算)
了解一样东西的发展过程,或者说了解一样东西的创造过程、改进过程。
可以拓展我们的思维,可能在以后的创造和设计中不知不觉的就进行模仿,参照比较。
关于应用场景,就有必要谈及优缺点,有优势才有"前途"。
(也许是意外的"接触"到C语言,但是如果想要深入学习的话,就有必要了解它究竟能"做什么")
编译器:将我们编辑的代码翻译为计算机所"认识"的机器代码。
(这个机器代码:或者说计算机指令,可以简单认为是我们预定义的动作代号)
有时候编译器不会听话,不会按照我们的代码一成不变的"翻译",它还会"做手脚"。
比如有一些编译器会对代码进行优化,如:
int i; int j; for(i=0; i<200; i ) { for(j=0; j<102; j ); }
编译器发现循环里面什么都没做,它就会将这一段代码,去掉,
然后再发现,i,j都没有使用,又将定义i,j的语句去掉。
有时候,我们就是想通过这样来实现一定的延时呢?
别担心,一般的编译器不会默认优化,而且可以设置是否优化以及优化的级别。
编译器会帮我们分析词法、语法。不同的版本有差异,或者说它支持的标准不同。
如C99标准的支持如下格式:
for(int i=0; i<200; i ) {}
C89就不支持了。
编译器参照的标准不一样,写法就可能存在差异。
平台的差异(Windows, Linux...),写法就可能存在差异。
八、待整理待补充
1、码(ASCII码,原码,反码,补码。。。) 字符、负数的存储方式。 2、基本数据类型(char, int, float, double, long。。。) 了解其大小,存储/解析方式,数值的表示范围。(数值溢出回绕) 3、关键字,变量 变量的命名方式 4、运算符 算术运算符( -*/),逻辑运算符(&&,||,!)、关系运算符(>,<,=),运算符结合性、优先级。。。) 5、表达式 算数表达式,逻辑表达式,关系表达式, 逗号表达式。。。 6、控制结构 if-else、switch、for、while、do-while、goto;(break与continue) 7、函数 函数调用过程、递归、变参函数、内联函数 8、数组 数组特点、数组嵌套 9、指针 指针含义、指针操作、多级指针,指针与数组 10、文件操作 读写、增删改查、文本文件、二进制文件 11、内存布局 内存堆、栈、全局区、代码区 12、组合数据类型 结构体(内存对齐)、共用体、枚举 13、字符串操作、编译过程、头文件、宏定义、条件编译、定义声明、变量的生命周期、作用域、可见域 14、数据结构 链表(单向链表,循环链表,双向链表)、堆、栈、树(二叉树、平衡二叉树、红黑树) 15、线程、进程 并发任务、线程锁 16、网络编程 TCP、UDP,网络字节序(字节序:大端序、小端序)
内存对齐:为了提高CPU的访问效率(存取数据的速度),编译器会对数据进行字节对齐。
地址线、数据线的条数决定CPU一次最大能够同时存取访问多少字节的数据。
在32位机器中,CPU一次最大能够同时存取访问32位(4字节)数据,一般数据都大于4字节,为了加快CPU存取效率,
CPU每次都取4字节(无论数据有没有4字节,CPU都会取出来4字节)。







