出品 | 智东西公开课
讲师 | 邱建斌 瑞芯微Toybrick AI开发平台负责人
提醒 | 关注智东西公开课公众号,并回复关键词 嵌入式01,即可获取课件。
导读:
瑞芯微Toybrick AI开发平台负责人邱建斌今年3月曾在智东西公开课进行了嵌入式AI合辑第一讲的直播讲解,主题为《AI开发平台如何帮助嵌入式开发者加速应用产品化落地》。
在本次讲解中,邱建斌老师首先从嵌入式AI的发展现状与挑战入手,介绍了两款Toybrick AI开发平台主要在用的两款芯片及在平台部署的优势,最后介绍了后续的产品规划。
本文为此次专场主讲环节的图文整理:
正文:
大家好,我是瑞芯微Toybrick AI开发平台负责人邱建斌,很荣幸能在智东西公开课和大家一起分享今天的课题。今天分享的主题为《AI开发平台如何帮助嵌入式开发者加速应用产品化落地》,主要分为以下4个部分:
1、嵌入式AI的发展现状与挑战
2、Toybrick AI开发平台解析
3、Toybrick系列在嵌入式视觉应用高效开发与部署上的优势
4、Toybrick的后续产品规划
嵌入式AI的发展现状与挑战
嵌入式AI一般也会被称作边缘计算,针对边缘计算与云端的AI计算,以前很多的算法公司都会在PC或者显卡上面做一些计算,所以云端计算能力会强一些,而且云端计算的能力可以比较平滑的去做一些事情。但云端计算也面临一些局限性,比如AI运算的及时性、运算速度及算力上成本的局限性等,所以很多算法公司需要把一些算法转化成产品,他们就会希望采用边缘计算方式,提高研发成果转化到市场的过程。所以,现在很多AI的算法公司,包括一些研究的机构会去摸索如何快速的把研发成果转化成产品,这样它们才能在市场上赢得先机。
但现在的问题是各家NPU的IP都不太相同,以前在PC上面做的事情到边缘计算上会面临很多问题,它会花费比较长的时间去熟悉不同的平台。第二点是很多算法公司及一些研究机构,不具备硬件开发能力,有些甚至不太了解底层硬件的平台。所以他们在开发过程中会相对比较困难、周期比较长。 我们把相对应的这部分硬件平台做的相对完善,并且可以提供一些案例给到一些开发者,让他们可以快速在一些原先的算法上做一些评估,最终可以快速的转化成产品。
Toybrick AI开发平台解析
在2019年Toybrick AI开发平台,硬件上提供不同系列开发平台和参考设计满足不同用户群体,软件上提供稳定可靠的系统平台、丰富的开发工具、AI教学案例和开源的社区。我们平台希望是可以提供高效、便捷、稳定的开发环境,让开发者迅速上手AI应用开发,加速AI行业产品研发进程,提升行业应用生态。

现在平台上面主要是用我们的两款带有NPU芯片做的。首先,第一款是RK3399Pro芯片,如果有一些同学用过3399可能比较清楚,与3399相比,3399Pro只是多了一款NPU。首先介绍下NPU的规格,这款NPU有1920个INT8的MAC计算单元,192个的INT16的计算单元,64个FP16的计算单元,最高可以跑800MHz。其他的性能也比较强,像CPU有双核的A72 A53,GPU为Mali的4核T860,同时支持5.1的eMMC。在视频编辑码这块能力也比较强,可以也是4K 60帧,264、265都可以解,可以支持1080p的编码,也支持安全的OP-TEE架构,包括支持Widevine Level1和PlayReady相关。显示接口也是比较丰富,比如有4k的输出等,视频输入的接口是比较多的,所以它可以广泛运用不同的场景。我们有两路的13MPixel ISP与MIPI CSI-2接口,USB处理单元,这两路是独立的。我们还有Type-C跟USB 3.0以及PCIe接口。

第二款就是RK1808芯片,对于RK 1808这款芯片,它有双核的A 35,它的NPU与3399相同,其他具体的参数信息可以看上图。RK1808不带GPU,所以与3399 pro的差别是除了NPU以外,3399 pro的计算性能更强以及视频编解码能力比较强,1808相对比较弱一点,因为它定位于做一个企业处理预算,做AI的NPU的推理工作,它也有一些接口可以做通讯,像RGMII还有PCIe、USB3.0,这些都是可以用。
我们有两款基于RK 1808芯片做的产品:神经网络计算棒以及Mini-PCIe的子卡,他们的主要工作是做 AI的推理。PCIe的子卡主要是U3的结果通讯,会在后面详细的介绍。
对于NPU的预算性能,我们跑了一些比较常见的模型,像VGG 16有46.4 FPS,ResNet50是70 FPS,MobileNet可以跑到190FPS。MobileNetV2_SSD可以达到84.5FPS,YOLO_v2可以达到43.4FPS。同时还支持一些语音识别的模型,我们也提供一些工具,可以比较快速的转化像Caffe、TesnsorFlow、PyTorch主流架构的模型。

上图是我们现在在网上有发售的,我们把芯片相关的一些比较高速的接口已经标出来,可以供大家可以直接使用,然后快速的在他们产品上面去做评估。它是比较高速的,比如说PCIe、USB等,同时它也可以跑Android 8.1和Linux,在板上设计上面都有提供,而且曾做过比较大的稳定性测试,整个板子的稳定性跟系统稳定性都比较好。
下面介绍下核心版的产品,因为许多客户没有硬件能力,所以我们核心版的方式是客户可以自己设置底板,然后根据它的产品形态,可以去设计不同的规格。核心板器的尺寸是69.6毫米×70毫米,采用紧凑尺寸的方式去实现。
1808上面也有所介绍,我们目前给开发者可以快速评估的就是计算棒。人工智能计算棒,我们提供相应的案例,让我们的客户可以直接在不同的平台上运行,比如在windows、Android及比较低端的平台也都可以运行。我们还有一种形态是Mini-PCIe,因为它可以部署到产品上面,如果平台上有PCIe接口,可以比较平滑的升级它的产品,只要把它放上去,原先产品就可以附着一个AI的功能,然后加上相应的软件去配合。
现在AI很多都是基于机器视觉相关的,围绕在摄像头这块。所以我们有一些开发套件,配合视频解码芯片,后面的分析模块是1808。其实它是通用于38mm*38mm安防标准尺寸,这样一些安防的客户可以直接把板子塞到他原先的模具里面,可以快速的升级原先的产品形态,并附着一个AI的功能。相较之下,其他芯片厂商灵活性会差一点点,我们其实相对会有更open一点,所以很多不同的模型及算法都可以在我们上面去跑。

下面简单介绍下RK3399Pro NPU应用典型架构,从前面的Camera进来,他的GPU可以做一些前处理,通过OpenGL负责画图以及显示,NPU主要是做推理,CPU可能是做系统调度,这样可以比较好的协调各个预算单元,专门去做对应专业的一个事情,这样产品的功耗也比较低,而且它的帧率也比较高,因为它不用去协助做推理,而且也有利于降低CPU跟GPU的负载。这也是NPU比较有利的一点,它可以大大降低CPU跟GPU的负载。
对于数据处理流程,整个流程是比较简单,它通过USB的HOST端,它这边有可能是PC或者我们的一个板子,或者我们原先的已有的平台,然后把模型的数据通过USB传输到我们的计算棒,然后在计算棒上面进行推理,可以得到结果,然后再通过你的画面进行后处理,就可以显示出来。
针对我们的NPU有提供RKNN ToolKit,它其实是一些转换工具。因为不同的框架像Caffe,TensorFlow、PyTorch都是不一样的,我们要先转换成RKNN的模型,因为在上一级可以提供模型转换、推理跟性能评估。由于它是一个工具,所以在使用过程中可以做一些模拟调试,性能预估或内存预估,这是在开发过程中是一定会用到的。
开发流程也相对比较简单,第一步是需要把不同框架的深度模型转换过来,像TensorFlow、Caffe、TF Lite、ONNX、Darknet模型都需要用我们的工具先进行转换,转换完之后把转换成出来的RKNN模型,放到NPU的预算单元里面,然后我们会加载模型文件,之后再把输入数据,像音频、视频图像,但是你可能需要一些前处理,需要做一些scale,把一些图像进行裁剪,接下来就可能调一个函数接口进行模型的推理,处理完之后就可以得到接口,比如说你放一个车牌的图片进去,我就可以得到一个车牌的号码,这是一个大致的开发流程。
不同的模型通过RKNN转换完之后,它可以通过Python或者C 的接口进行调用,开发工具其实是做一个模型的快速转换、性能的评估,以及进度的预测,然后可以进行最终的一些调试,验证最终的精度。
Toybrick系列在嵌入式视觉应用高效开发与部署上的优势
在AI这方面我们也做了一些初步的demo,我们称为Rock-X AI SDK,这块我们其实已经做了很多,比如现在比较常见的一些模型算法,像人体骨骼关键点、人脸特征点、手指的关键点、人脸检测、人脸识别、活体检测、人头检测、人脸属性分析及车牌识别。
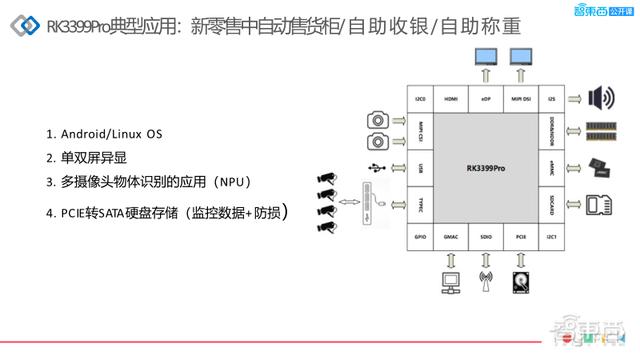
对于新零售现在有两个方向,像自动售货柜、自助收银、自助称重。现在很多都有双屏异显的一个需求,因为它上面可能会推动一些广告,我们从上面的框图可以看到,它最主要是摄像头采集,对于摄像头的接口,我们可以支持MIPI的接口,USB可以接多个,甚至摄像头的数据可以通过网口的进来,显示接口也比较多,可以支持eDP跟HDMI。我们支持默认系统DDR&NDDR跟eMMC的SD卡,同时有PCIe的接口可以支持转接SATA硬盘存储。
现在新零售的自动售货柜,它基本上都会有4-6个的摄像头,有时客户做物体识别,基本上一个摄像头可以跑满30帧左右,我们可以解4k 60帧,你也可以换算下其他的分辨率,最高可以是4k 60帧的多路视频。
第二个就是大型商超做自助收银,它可以直接识别物体,不像原来会扫码的动作,而且也可以通过摄像头 算法防止商品的丢失。它接口上面的差异可以通过网口来获取数据,因为摄像头有可能在比较高处,对比传统的方案,大型商超和小型商超如果你用显卡的服务器来做,它可能相对布线比较复杂一点,然后灵活性没那么高。如果用边缘计算这种方式,它直接到终端,部署比较方便,然后它的成本也会相对较低,所以现在很多不同的公司都会往这边去发展,用3399Pro实现这样的一个功能。
还有一个应用是3399 Pro与1808现在很多人做边缘计算服务器,在终端做NVR跟AI网关,它直接就可以跑Linux OS,其实安卓相较于Linux的一个优势是安卓尽量可能做的更漂亮一点,不像刚才新零售需要做一些广告或者其他的部分,它的接口部分的差别是摄像头数据是通过网络进来的,其他部分外围相对比较少,本地也可以把对内的数据存下来,通过PCIe的SATA接口转为硬盘存储。
它应用场景比较广的,像做边缘服务器用NVR和AI都可以用,包括做智能路灯之类,而且一个边缘计算服务器可以处理多个摄像头,不单单是一个摄像头,有多个数据出来,可以时分复用的方式去处理。

上图是一些应用场景,比如1808在安防摄像机,做人脸的检测与跟踪、智能运动检测、区域入侵、绊线检测与车牌识别。这也是我们为什么会做一个安防的套件,因为嵌入式AI很大比例的产品集中在机器视觉,这主要依靠摄像头来做。
还有零售的摄像机,它做人流统计、热点统计及动作检测,包括对行为的分析。对于家用安防摄像头,它可以做人、宠物与汽车的检测和识别,快递包裹放下和拿走的检测。边缘计算在这些产品上有一些优势,它可以直接拿原始数据进行处理,这样特征更丰富一些,相对之前的云端计算,它可以减少网络的传输,响应速度更快,功耗更低,成本也会更低。
另一种方向是现在做DMS,DMS是在客车上面做安全,像两客一危,一辆车上面会有多个摄像头去检测,比如说你前端去检测驾驶员打哈欠、抽烟、打瞌睡、看手机、打电话之类的动作。这样客车公司可以拿这些数据来做一些检查之类的,还可以做一些ADAS的功能,车道偏移报警,碰撞预警,交通标志识别,同时也可以做做盲点探测、行车记录、语音交互。我们可以接多个摄像头,例如也可以N4的板,最多可以接6路,编码我们可以6-8路的编码。
因为你原先的产品形态上面,在1808上面通过比较小的改动,就可以做比较好的产品设计,你原先可能不止在这一块,通过PCIe模块或者设计的一个小模块,对接到我原先的产品平台上面,它可以变成一个支持AI功能的产品,可以比较方便来做产品升级。扫地机器人通过激光导航 Camera实现检测物体,智能避障,还有儿童故事机,指尖识别,同时也支持麦克语音阵列。
对于NPU,有些客户的模型会比较大或者摄像头的路数比较多,还需要比较强的计算能力。我们可以通过多个计算棒或者平台模块进行算力叠加。比如一个NPU或一个 1808计算棒,它可能只能处理几路,这需要根据实际的模型的情况来定,如果有很多路就有可能就要多个,所以我们也有一个多路的 demo。
Toybrick的后续产品规划
后续的规划主要集中在RKNN,像Pytorch已经支持了,前面做了一些工作是混合量化、联机调试,做了一些优化加快模型的加载时间,然后也对接上Tensorflow 2.0,最后也会对TF-Keras做一些优化。我们也会提供一些案例,像条码和二维码、OCR、语音识别等。
后续还会根据我们新的产品、芯片以及不同的产品方向,推出一些硬件平台,来给予我们的开发者可以快速的开发。
,