如今信息时代,数据获得并不难,关键是要做梳理,让其从冰冷的数据,变成适合自己的模式,有一个驯化的过程。如今官方数据和公开数据都已经非常透明了,权威且有效,面对海量的信息,需要投资者按照自己盈利模式和系统,去做相关的梳理,去粗取精,并且将关心的数据进行持续性跟踪,这样才会形成有效数据,今儿也是针对很多股民的案例,来解读如何建立属于自己的数据库。
将数据有效联系,立体化对比
有股民问到,如何看懂媒体热炒的几十亿元的“基金集中自购”现象?是真的大底部来了吗?
@玉名 说实话,一开始,我对此并不是太感兴趣,因为基金自购,和别的资金买差别不大,在我们大量数据中,有过研究,各路资金从自身盈利模式出发的,那么如果想要复制就需要看懂全部的盈利模式,单纯以基金为例,管理费收益这方面是普通投资者无法复制的,所以对此并不是过分关系。但如果这样单凭感觉去做决定还是武断了,后来又进行了数据方面的补充。
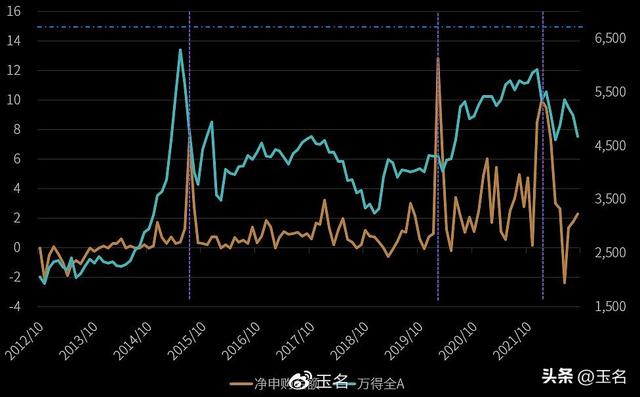
如图所示,对比WIND A股指数和机构机构净自购基金总额。在之前有过几次这样的情况,2015年7-8月,2020年春节后,2022年一季度。从基金角度来说,这些时刻,都面临比较大的赎回压力,因此,基金自购说白了,是向投资者表态“老乡别走”,传递一种信心。随后,也不意味着就是市场底部,甚至有过几次随后出现的再度跳水,因此只凭这个指标,并不能判断市场,甚至有可能是基金公司的“广告”行为,毕竟所谓的自购,对其来说只是左手递给右手而已,而投资者却是实实在在的真金白银。
那么,我们再换一个角度,从如果换成净申购规模占比来看,2022年10月这一波,基金自购金额并不算大,或者说占比规模并不大,不适合过分解读。主要是2022年疫情周期之后,基金这样的自购始终在高位的,说白了,疫情周期后日子不好过。因此,单纯靠自购来站台,很难应对和对冲外部环境因素的影响。
思考也不能就此暂停,玉名认为还能继续思考,热点的思路。如今市场并没有群体性行情,热点总是结构性展开,而从基金自购角度,风格众多,但即便是市场局部反弹(容易类似2022年5-6月份那样级别的),也只是主线热点新能源(车)的活跃,而我们思考在这个位置,市场也有机构自购现象,但真正针对这样热点的自购情况并不多,所以我们可能无法参考这个指标。这个时候,我们需要从行业角度入手,说白了,新兴行业还是需要靠自己的持续研究,而传统行业则是有现成规律的严格使用,因此,面对数据至少我们要思考到这个层次。传统行业的数据与迭代
有股民提问到,如果说传统行业是周期性的规律,那么做功课是不是就没意义了?因为都有历史数据了,重复做有意义吗?
@玉名 您提到这个问题很有意思,这也是我们经常碰到的事儿,传统行业分析的是所在趋势的位置。以猪肉为例,并不是说单纯看猪肉价格,而需要看如今猪肉价格所在的位置,所以我们不是看如今一个位置的价格,需要有一个横向和纵向的对比。在《猪肉博弈高级模式,利用猪鸡比升级利润》https://weibo.com/ttarticle/p/show?id=2309404827994635239762中就是在做了9月猪肉出栏数据后,又做了1-3季度的对比,这个时候能看到各个公司在产业链中的位置,哪些保持持续增长,哪些始终低迷,这对我们判断公司在行业中的位置非常有帮助。
还有,我们也要明白,传统行业的相关规律,类似猪周期的循环特性,这些的确是不变的,但每次又有不同,比如说非洲猪瘟带来的超级周期,让振幅都很大,但即便如此,随后的猪周期还是相对稳定。因此,不要拘泥于局部的数字,也要思考在大环境中的位置。同时,还有升级,当我们学会了更多行业之后,还可以利用行业的迭代,实现更多操作,猪鸡比的出现,就是利用这个因素。本来鸡肉的分析是比较难的,指标相比于猪肉又复杂,又琐碎,但当我们利用了学会猪周期后,相关分析,就变得简单了。类似地,新兴行业和其他行业中,也有类似的因素,值得投资者思考。
,