从文本数据中提取价值
机器学习教育的许多重点都围绕有监督的学习—预测值或分类—在您开始使用现实世界的数据集之前,一切都很好。与创建模型相比,以一致的格式获取表格数据可能要花费更多时间。当使用文本数据时,这是很明显的,因为您可能对许多文本感兴趣的人都不关心质量或格式。生成非结构化数据的速度比结构化数据的增长速度快,因此使文本数据具有一致性是一项有用的技能。提取重要信息对我来说是一个经常遇到的挑战,因此这里简要介绍了如何使用Watson Knowledge Studio。

> Photo by Markus Spiske from Pexels
定义类型系统Watson Knowledge Studio是一个注释引擎,旨在从一段文本中提取实体和实体之间的关系。定义实体和关系(统称为类型系统)是此过程的第一步。实体是您要提取的现实世界中的事物。它们可能具有子类型或多个角色(例如,"纽约"具有GeoPolitical角色和Destination角色)。实体也可能是共同引用的一部分,共同引用表示两个标记何时引用同一事物(例如,"汽车坠毁,但未受到损坏")中的"汽车"和"它"是同一实体。关系是实体之间的二进制关系(例如,"崩溃"和"汽车"在前面的示例中可能具有" eventOf"关系)。

> Watson Knowledge Studio Entity Recognition
如果您有一个具有许多实体和关系的类型系统,或者您的文档来自于技术含量很高的领域,则在创建ML模型的过程中请一名主题专家,并且可能需要类型系统。该类型系统可以从一个模型导入/导出到另一个模型中,以加快您的训练过程,这在您要训练需要识别两个用例共有的实体的多个模型时非常有用。
人工注释创建类型系统后,需要选择要提取的数据的代表性文档。目标是文档长度从一段到2000字不等。这些文档可以拆分并分配给不同的注释器,分配之间要有一定程度的重叠,以确保准确性。注释之间的冲突会被标记,并且可以由主题专家或项目经理解决。注释者之间确实会出现分歧,因此最佳实践是使文档保持注释原则,以帮助指导团队。注释非常简单,只需突出显示单词并选择要为其添加标签的实体即可。可以在标记的实体之间画线以创建关系。可以通过双击要添加到共同引用中的实体来创建共同引用。

> Create relationships between entities
创建一个预注释者在完成一定程度的注释后,您可能会注意到文档中的常见模式。您可以使用三种工具来创建自动预注释器,以节省注释时间。虽然您可以在开始人工注释之前从技术上创建一个预注释器,但是最好手动进行一些操作,以更好地了解您可能希望该预注释器捕获的常见模式。您的预注释者创建的误报可能会根据需要删除。
辞典词典使您可以自动将特定单词标记为实体的成员。例如,您可以将单词" Honda"设置为自动识别为Manufacturer实体的一部分。同义词也可以应用于每个实体,以帮助识别。您可以有多个词典(每个词典都有很多条目),可以将它们导出,然后导入到其他模型中,从而帮助Watson收集对您的领域的了解并加快模型创建过程。
规则规则可让您根据单词周围的实体将单词分类为特定的实体。在本文的第一张图片中,文字包含短语" 2005 Ford Escape",该短语遵循一种常见的年份模型来描述车辆。如果我们的词典将"福特"一词捕获为制造商,那么我们可以创建一条规则,规定当制造商后接4个字符的数字词时,我们可以将其后的单词标记为Model。
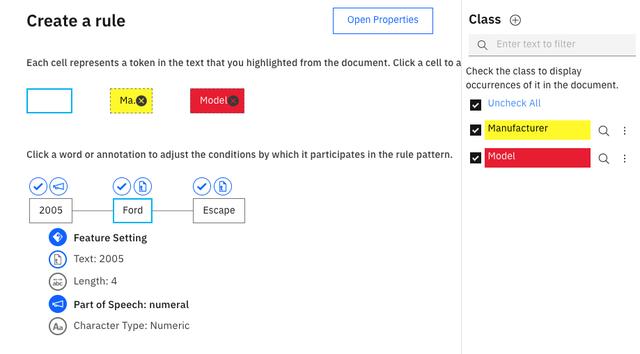
> Demonstration of a rule
正则表达式正则表达式可以帮助您自动标记遵循特定模式的文本片段,而无需像字典中那样提供特定示例。例如,电子邮件,电话号码或ID码。如果您想标记不特定于您的用例的模式(例如电子邮件),我建议您谷歌搜索电子邮件RegEx并复制它,以获取特定于您域的模式,请寻求以下帮助您团队中知道正则表达式的人。
训练您的注释模型一旦您的团队为您要通过模型提取的每个实体标记了大约40个示例,则只需单击WKS用户界面中的"训练和评估"按钮,即可简单地训练模型。然后将建立一个ML模型,以找出应从文本中提取哪些数据。我没有注释足够的文档来创建此示例的模型,但是有关模型版本的指标将在下面显示。
> Train and evaluate your model
一旦拥有模型的版本1,添加到批注中的新文档将被自动批注,然后您可以确认这些自动批注。这样可以加快注释过程的速度,并帮助您快速获得出色的版本2。
部署方式WKS的另一个好处是一键式部署。该模型可以作为API部署到Watson自然语言理解(NLU),或者可以导出以用于自定义环境或增强Watson Discovery(用于查找个人/内部公司文档的搜索引擎)。模型的JSON响应将告诉您实体在什么字符处开始和结束,实体之间的关系以及元数据(例如语言或词性)。
结论如果需要生成结构化数据进行分析,则需要以可重复的过程进行操作,以使生产数据不依赖任何手动步骤。建立注释器是从具有比例尺的文本中提取格式化数据的最佳选择。提取数据的目的甚至可能不是生成用于机器学习的数据,也可能是发现有关评论的基本分析,协助生成聊天机器人对话或从书面说明中提取产品属性的数据。
此外,在某些组织中,非结构化数据最多可占数据的80%,并且可能每两年左右翻一番。如果不是迫切需要提取结构化数据,那么它很有可能会成为现实。率先采用AI解决方案来解决任何问题都是巨大的财富。在您的NLP努力中祝您好运!
(本文由闻数起舞翻译自Md Kamaruzzaman的文章《Generating Structured Data from Unstructured Data》,转载请注明出处,原文链接:https://towardsdatascience.com/generating-structured-data-from-unstructured-data-366839c63c89)
,




