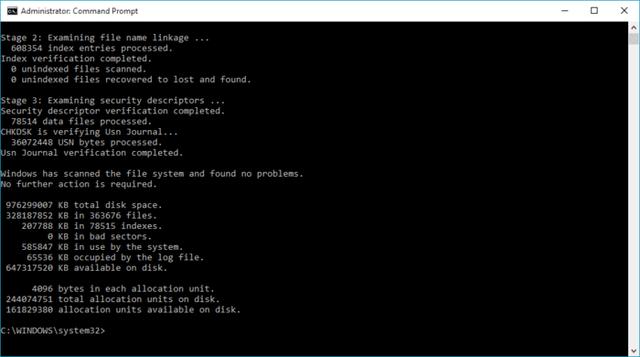
在本教程中,我将尝试对Python中最重要的两个库做一个简短的描述Numpy和熊猫...我们不要再拖延了,让我们过去吧Numpy第一。
入门Python其实很容易,但是我们要去坚持学习,每一天坚持很困难,我相信很多人学了一个星期就放弃了,为什么呢?其实没有好的学习资料给你去学习,你们是很难坚持的,这是小编收集的Python入门学习资料关注,转发,私信小编“01”,即可免费领取!希望对你们有帮助
Numpy
numpy是Python中科学计算的核心库。它为处理这些数组提供了一个高性能的多维数组对象和工具。Numpy是一个强大的N维列阵对象,它是Python的线性代数。Numpy数组本质上有两种类型:矢量和马曲 . 矢量严格地说是一维数组,而矩阵是2D但是矩阵只能有一行/列。
现在使用numpy在程序中,我们需要导入模块。一般来说,numpy包定义为np为了方便起见。但是你可以使用你想要的任何东西来导入它。
import numpy as np np.array([1, 2, 3]) # Create a rank 1 array np.arange(15) # generate an 1-d array from 0 to 14 np.arange(15).reshape(3, 5) # generate array and change dimensions
现在要了解更多关于numpyPakage及其功能--您可以直接跟踪https://numpy.org/官方网站。在这里,我们将讨论一些重要的命令和函数numpy图书馆。

在上面的例子中,我们可以观察到numpy首先导入,然后导入1-d numpy列阵a被定义。然后,我们可以使用上述命令检查数组的类型、维度、形状和长度。下面是创建数组的一些重要命令:
np.linespace(0,3,4) #create 4 equally spaced points 0-3 range inclusively np.linespace(0,3,4, endpoint=False) # remove endpoint and other equally spaced values. np.random.randint(1,100,6) #create array of 6 random values in 0-100 range. np.random.randint(1,100,6).reshape(3,2) #reshape the array according to row and column vectors. np.random.rand(4) #create an array of uniform distribution (0,1) np.eye(3) #create a 3*3 identity matrix np.zeros(3) #create array([0,0,0]) np.zeros((5,5)) #create a 5*5 2-d array of zeros np.random.randn(2,2) #return standard normal distribution vcenter around zreo. np.empty((2,3)) # uninitialized np.arange(0, 2, 0.3) # from 0 to a number less than 2 with 0.3 intervals np.ones((2,3,4), dtype=np.int16) # all element are 1 np.array([[1,2],[3,4]], dtype=complex) # complex array np.array([(1.5,2,3),(4,5,6)]) # two-dimensional array np.array([2,3,4]) # one-dimensional array
的重要属性达雷对象
ndarray.shape数组的尺寸。这是一个整数元组,指示每个维度中数组的大小。的矩阵n行和m列,形状将是(n,m) .
ndarray.ndim数组的轴数(尺寸)。
ndarray.dtype*如果您想知道数组的数据类型,可以查询D型...描述数组中元素类型的对象。可以创建或指定D型使用标准Python类型。
此外,蒙皮提供自己的类型。numpy.int32 , numpy.int16,和numpy.float64就是一些例子。

属性达雷对象
ndarray.itemsize数组中每个元素的大小(以字节为单位)。例如,类型为Float 64的元素数组具有项目大小8(=64/8),而类型之一络合32有项目大小4(=32/8)。它相当于ndarray.dtype.itemsize。
ndarray.size数组的元素总数。这等于形状元素的乘积。
打印数组:打印数组时,numpy以类似于嵌套列表的方式显示它,但使用以下布局:从左到右打印最后一个轴,从上到下打印第二个到最后一个,其余部分也从上到下打印,每个切片与下一个切片之间用空行分隔。

基本操作:
A = np.array([[1,1],[0,1]]) B = np.array([[2,0],[3,4]]) A B #addition of two array np.add(A,B) #addition of two array A * B # elementwise product A @ B # matrix product A.dot(B) # another matrix product B.T #Transpose of B array A.flatten() #form 1-d array B < 3 #Boolean of Matrix B. True for elements less than 3 A.sum() # sum of all elements of A A.sum(axis=0) # sum of each column A.sum(axis=1) # sum of each row A.cumsum(axis=1) # cumulative sum along each row A.min() # min value of all elements A.max() # max value of all elements np.exp(B) # exponential np.sqrt(B) # squre root A.argmin() #position of min value of elements A.argmax() #position of max value of elements A[1,1] #member of a array in (1,1) position
索引、切片和迭代 蒙皮 :
a = np.arange(4)**3 # create array a a[2] # member of a array in 2nd position a[::-1] # reversed a a[0:4,1] # each row in the second column of b a[1,...] # same as a[1,:,:] or a[1] a[a>5] # a with values greater than 5 x = a[0:4] # assign x with 4 values of a x[:]=99 # change the values of x to 99 which will change the 4 values of a also.
如果将数组的任何位置分配给另一个数组,并将其广播为新值,则原始数组也会更改。这是因为蒙皮不想为同一个数组使用更多的内存。如下图所示,a的值更改为x,它是数组的一部分。a .

当我们在数组中使用比较运算符时,它会返回一个布尔数组。然后使用布尔数组,我们可以从原始数组中有条件地选择元素。
熊猫
pandas的基础上构建的开放源代码库。蒙皮为Python编程语言提供高性能、易于使用的数据结构和数据分析工具.它允许快速的分析和数据的清理和准备。它在业绩和生产力方面都很出色。它可以处理来自多种来源的数据。pandas适用于许多不同类型的数据:表格数据、时间序列数据、带有行和列标签的任意矩阵数据以及任何其他形式的观测/统计数据集。要在系统中安装熊猫,可以使用以下命令pip install pandas或conda install pandas .
import numpy as np #importing numpy import pandas as pd #importing pandas arr=np.array([1,3,5,7,9]) #create arr array s2=pd.Series(arr) #create pandas series s2 print(s2) #print s2 print(type(s2)) #print type of s2
产出:
0 1 1 3 2 5 3 7 4 9 dtype: int64 <class 'pandas.core.series.Series'>
制作系列片pandas我们需要用pd.Series(data, index)格式data是输入数据和index为数据选择索引。为了充分理解它,我们可以遵循下面的例子。

熊猫系列的工作方式是相同的列单和蒙皮数组以及字典还有。 面板 三维数据结构,有三个轴,
轴线0 ( 项目 ), 轴1 ( 主轴),以及轴2 ( 短轴 ). 轴线0对应于二维DataFrame。对应于轴2对应于DataFrame的列。下面的示例使用蒙皮生成一个三维随机数,然后将其应用于
pandas.Panel()...输出显示,Panel对象为尺寸2 ( 项目)x3 ( 主轴)x4 ( 短轴)是被创造出来的。如果你抬头看p[0]从Panel对象p,您可以看到显示了DataFrame,它是Axis 0的第一个元素。

熊猫数据帧创建带有标记轴(行和列)的表格数据结构。DataFrame的默认格式是pd.Dataframe(data, index, column)...您需要提到数据、索引和列值来生成DataFrame。数据至少应该是二维 , 指数将是行名和柱列的值。

例熊猫系列 & DataFrame
下面我提到了熊猫库中使用的一些基本命令以及它们的用法:
s4=pd.DataFrame(np.random.randn(20,7), columns=['A','B','C','D','E','F','G']) s4[(5<s4.index) & (s4.index<10)] # s4 with values that satisfy both conditions s4.head() # First five rows of s4 s4.tail() # Last five rows of s4 s4.describe() # statistical information of data s4['B'] # data of the 'B' column s4[['B','E']] # data of the 'B' and 'E' column s4[0:3] # data of the 1~3 rows s4.iloc[0:3] # data of the 1~3 rows s4.loc[[2,3],['A','B']] # value of row 2,3 column 'A' ,'B' s4[2 < s4] # s4 with values matching conditions s4.mean() # means of each column s4.mean(1) # mean of each row s4.drop('A') # delete row 'A' s4.drop('D',axis=1) # delete 'D' column s4.drop('D',axis=1, inplace=True) # delete 'D' column permanently s4['H']=np.random.rand(20,1) # add a new column of same length.
字典可以用来创建熊猫系列和数据框架。字典可以用作数据来创建表格数据,但是价值应该是多过 一为每个键所有 价值 应该是 同长 而在熊猫系列中,不同的价值长度是可以的。

熊猫系列和达菲通过字典
要重置框架的索引并将前一个索引添加到列中,我们需要遵循以下命令。重置索引将是数值。
df.reset_index(inplace=True) df.set_index('Name') #index will be 'Name' column but not permanent. df.set_index('Name', inplace=True)#permanent new index 'Name' column
大多数DataFrames有几个非数值在不同的列中。有时我们需要移除非数或者用别的东西代替它们。我们可以删除或替换非数在熊猫数据框架中的价值如下:
df.dropna() # remove the rows that have Nan value df.dropna(inplace=True) # remove the Nan value rows parmenentlydf.dropna(axis=1) # remove columns that has Nan value df.dropna(axis=1, inplace=True) # remove the Nan valued columns parmanently. df.fillna(value='Arman') # fill Nan values with 'Arman'. df.fillna(value='Arman', inplace=True) #fill values parmanently. df.fillna(value=df.mean(), inplace=True) #fill Nan value with each column mean value. df['A'].fillna(value=df['A'].mean()) #fill Nan value of column 'A' with its mean.
在我的下一篇教程中,我将尝试总结一下Matplotlib和Seabon这两个主要使用的可视化库。我将尽快为本教程添加一个回购程序。谢谢你的时间和任何类型的建议或批评是非常值得赞赏的。你可以跟着我的个人资料看几个教程。
,