在围棋之后,即时战略游戏星际争霸是人工智能研究者们的下一个重要目标。近日,中科院自动化所提出了一种强化学习 课程迁移学习方法,让 AI 智能体在组队作战的条件下掌握了微操作的能力,该研究或许可以让多智能体 AI 方向的发展向前推进一步。该论文已被学术期刊 IEEE Transactions on Emerging Topics in Computational Intelligence 收录。
该研究的代码和结果已公开:https://github.com/nanxintin/StarCraft-AI
人工智能(AI)在过去的十年中已经有了巨大的进展。作为 AI 研究的绝佳测试平台,游戏自从 AI 诞生之时就在其身边推动技术的发展,与人工智能产生联系的游戏包括古老的棋盘游戏、经典的 Atari 街机游戏,以及不完美信息博弈。这些游戏具有定长且有限的系列动作,研究人员只需要在游戏环境中控制单个智能体。此外,还有多种更加复杂的游戏,其中包含多个智能体,以及复杂的规则,这对于 AI 研究非常具有挑战性。
在本论文中,我们专注于即时战略游戏(RTS)来探索多智能体的控制。RTS 游戏通常需要即时反应,这与棋盘游戏的回合制不同。作为最为流行的 RTS 游戏,《星际争霸》拥有庞大的玩家基础和数量众多的职业联赛——而且这个游戏尤其考验玩家的策略、战术以及临场反应能力。对于游戏 AI 的研究,星际争霸提供了一个理想的多智能体控制环境。近年来,星际争霸 AI 研究取得了令人瞩目的进展,这得益于一些星际争霸 AI 竞赛,以及游戏 AI 接口(BWAPI)的出现。最近,研究人员开发出了一些更加有效的平台来推动这一方向的发展,其中包括 TorchCraft、ELF 和 PySC2。
图 1:智能体-环境交互在强化学习中的表示。
图 2:课程迁移学习图示。存储通过解决源任务而获得的知识,逐渐应用到 M Curricular 任务上以更新知识。最终,知识被应用于目标任务。
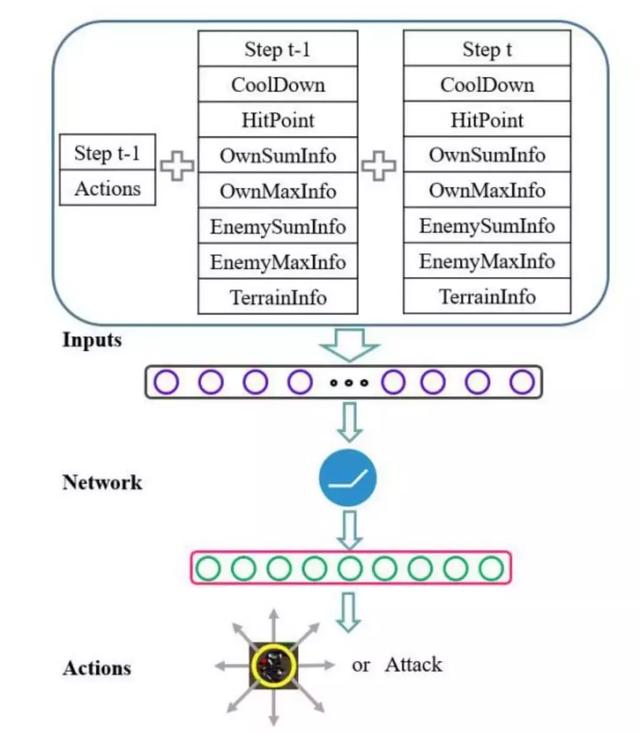
图 3:一个单位在星际争霸微操场景中的学习模型表示。状态表示含三个部分,神经网络被用作函数逼近器。网络输出移动的 8 个方向和攻击动作的概率。
在这一研究中,星际争霸微操被定义为多智能体强化学习模型。我们提出了参数共享多智能体梯度下降 Sarsa(λ)(PSMAGDS)方法来训练模型,并设计了一个奖励机制作为促进学习过程的内在动机。整个 PS-MAGDS 强化学习范式如图 4 所示:
图 4:StarCraft 微操场景中的 PS-MAGDS 强化学习图示。
微操场景中不同单元的属性对比
图 5:实验中 StarCraft 微操场景中的表征。左:人族巨人 vs. 狂热者;中:人族巨人 vs. 狗;右:机枪兵 vs. 狗。
结果
机枪兵 VS. 狗的微操的课程设计。M:机枪兵,Z:狗。
两个大场景中使用基线方法的模型的性能对比。M:机枪兵,Z:狗。
不同课程场景和未知场景中的胜率。M:机枪兵,Z:狗。
图 12:3 个人族巨人 vs. 6 个狂热者的微操场景中的样本游戏回放。
图 13:3 个人族巨人 vs. 20 只狗的微操场景中的样本游戏回放。
图 14:20 个机枪兵 vs. 30 只狗的微操场景中的样本游戏回放。
论文: StarCraft Micromanagement with Reinforcement Learning and Curriculum Transfer Learning
论文链接: https://arxiv.org/abs/1804.00810
摘要:近年来,即时战略游戏已成为游戏 AI 的一个重要领域。本论文展示了一种强化学习和课程迁移学习方法,可在星际争霸微操中控制多个单元。我们定义了一种高效的状态表征,破解了游戏环境中由大型状态空间引起的复杂性,接着提出一个参数共享多智能体梯度下降 Sarsa(λ)(PS-MAGDS) 算法训练单元。学习策略在我们的单元中共享以鼓励协作行为。我们使用一个神经网络作为函数近似器,以评估动作价值函数,并提出一个奖励函数帮助单元平衡其移动和攻击。此外,我们还用迁移学习方法把模型扩展到更加困难的场景,加速训练进程并提升学习性能。在小场景中,我们的单元成功学习战斗并击败了胜率为 100% 的内置 AI。在大场景中,课程迁移学习用于渐进地训练一组单位,并展示在目标场景中一些基线方法上的出众性能。通过强化学习和课程迁移学习,我们的单元能够在星际争霸微操场景中学习合适的策略。
,