一、 引言
非结构化数据[1]占据了人类数据总量的绝大部分[2],而且其比重还在不断上升[3]。作为非结构化数据的重要组成部分,文本数据的类型丰富多样(如社交网络类文本、上市公司披露类文本与媒体报道类文本),在财务与会计领域具有很高的研究价值,因而文本分析(Textual Analysis)技术正在异军突起,形成一个新的研究领域。所谓文本分析,是指以文本数据为信息来源,运用特定的技术挖掘文本的情绪、可读性、相似度等文本特征,并利用这些特征进行实证研究的技术。然而,早期的自动文本分析技术很不成熟,人工编码的研究方法又不适用于大样本研究,因此,传统的财务与会计研究在相当长的时间内,仍主要局限于利用结构化数据进行研究,文本分析研究并不多见。
随着计算机处理技术的发展,自动文本分析技术日新月异,为文本信息的结构化处理提供了新方法与新工具,极大地拓展了研究视角(Loughran and McDonald, 2011;Schütze, Manning, and Raghavan, 2008;Blei, Ng, and Jordan, 2003;Kouloumpis, Wilson, and Moore, 2011)。运用主题分析、词典法、词袋法、监督学习、无监督学习、自然语言处理等文本分析技术,通过对社交网络类文本、上市公司披露类文本、媒体报道类文本以及其他类文本信息进行挖掘,研究者能够抽取文本的情绪(Tetlock, 2007;Loughran, McDonald, and Yun, 2009;林乐和谢德仁,2016)、可读性(Lehavy, Li, and Merkley, 2011;Guay, Samuels, and Taylor, 2016)、相似度(Hober and Phillips, 2010;Lang and Stice-Lawrence, 2015)、摘要(Cardinaels, Hollander, and White, 2019; Blaseg and Bannier, 2019)、主题(Bao and Datta, 2014; Hanley and Hoberg, 2019)、分类(Frankel, Jennings, and Lee, 2016; Bandiera, Prat, Hansen, and Sadun, 2020)以及数量(Engelberg, and Gao, 2011; 俞庆进和张兵,2012)等文本特征,并进一步展开研究,为财务与会计研究领域的研究提供更丰富的研究内容与研究视角。
与国内相比,国际上在文本分析研究方面起步较早,研究成果也更为丰富。Antweiler and Frank(2004)首次使用网络信息平台预测股票市场,发现股吧留言能够预测股票交易量和波动性。Li(2008)开创性地利用大样本研究年报可读性,发现管理层可能会策略性地管理文本可读性。Li(2010)第一个采用机器学习算法研究财务报告披露,聚焦公司年报管理讨论和分析部分(MD&A)中前瞻性声明的信息内容。Loughran and McDonald(2011)创建了金融学领域专属的情绪词典。Campbell, Chen, Dhaliwal, Lu, and Steele(2014)开创性地将LDA[4]模型应用于风险披露的研究,从风险披露文本中提取风险因素。Huang, Zang, and Zheng(2014)则首次在大样本下探究分析师报告的文本内容。
总体而言,现有文献着重于改进文本分析的技术或者直接将文本分析应用于财务与会计领域的研究,但缺乏对文本分析研究方法与应用的详细系统的介绍。本文主要从以下方面对现有文本分析研究进行了梳理和总结:首先,根据不同的文本信息种类对国内外文本分析的研究分别进行梳理,有助于读者了解文本信息的来源与获取方式;然后,详细介绍了各种文本分析处理技术,包括主题分析、词典法、词袋法、监督学习、无监督学习以及自然语言处理,利于研究者熟悉文本分析处理的技术;接着,归纳了文本分析研究通常抽取的文本特征,以便读者把握文本分析在财务与会计研究领域相关研究中的主要关注点;另外,总结了文本分析研究的主要应用类型,有助于国内研究者了解文本分析研究的应用主题与角度。最后,回顾了国内文本分析研究发表的情况,便于研究者掌握文本分析相关文献的研究进展。
二、文本信息来源维度
本部分从文本信息来源的角度,对文本分析研究进行了回顾。现有文献用于研究的文本信息主要包括社交网络类文本,上市公司披露类文本(如年报、季度报表、电话会议文本、盈余公告、日志文本、招股说明书等),媒体报道类文本与其他类文本。
(一) 社交网络类文本来源
随着近年来社交网络的兴起,大量社交网络的文本信息被逐渐纳入文本分析研究的范畴,微博、股吧、Twitter等社交媒体与网络平台的文本信息逐渐成为研究的重点。
基于国外社交网络的文本数据已有大量的研究。许多研究者发现社交网络文本信息能预示股票价格波动与公司未来收益。Antweiler and Frank(2004)以雅虎财经网络论坛留言板上关于45家公司的150万条信息为样本进行了研究,发现股票留言板的信息包含着与股票定价相关的信息。类似的,Chen, De, Hu, and Hwang(2014)、Huang(2018)与Green, Huang, Wen, and Zhou(2019)分别着眼于——Seeking Alpha[5]上投资者的观点、亚马逊的客户产品评论与Glassdoor上员工对雇主的评级信息,也得到同样的结论。进一步,Jung, Naughton, Tahoun, and Wang(2018)分析标准普尔1500公司使用Twitter发布季度收益公告的情况,以探究公司是否使用社交媒体策略性地传播财务信息。也有不少研究基于社交网络文本数据以研究投资者情绪。例如,Das and Chen(2007)利用摩根士丹利高科技股指数(MSH)中24只科技股的公告板上的所有信息,构建了投资者情绪指标。Renault(2017)与Cookson and Niessner(2020)也均利用StockTwits[6]上的用户信息,分析投资者情绪并研究投资者分歧的来源。
国内社交网络平台的文本数据也日趋受到关注。何贤杰、王孝钰、赵海龙和陈信元(2016)手工搜集上市公司在新浪微博上发布的信息,发现治理水平越高的公司越倾向于开设微博,且发布更多的与公司密切相关的信息。Huang, Qiu, and Wu(2016)利用东方财富网股票留言板数据,以考察投资者关注的地域偏差。孙书娜和孙谦(2018)基于雪球社区用户的自选股信息构建了日度超额雪球关注度指标,更真实、直接、准确地反映个人投资者的关注水平。Jiang, Liu, and Yang(2019)也选取东方财富网股吧数据,探究投资者沟通对上市公司资产波动的影响。
(二) 上市公司披露类文本来源
研究者通过分析上市公司披露的文本信息,能够弥补财务数据的不足,从而挖掘出更丰富的信息。其中,针对年报、季度报表、电话会议文本、盈余公告、日志文本以及招股说明书的研究比较广泛。
国外上市公司披露的文本信息很早地受到了关注。Li(2008)首次在大样本下聚焦年报,研究年报可读性和其他词汇特征。许多学者以10-k、10-Q文件为研究对象,分别考察产品描述部分(Hoberg and Phillips, 2010; Hoberg and Phillips, 2016)、MD&A中的前瞻性陈述(Li, 2010; Mayew, Sethuraman, and Venkatachalam, 2015; Frankel, Jennings, and Lee, 2016)、文本可读性(Lehavy, Li, and Merkley, 2011; Lo, Ramos, and Rogo, 2017)、风险因素披露部分(Campbell, Chen, Dhaliwal, Lu, and Steele, 2014; Bao and Datta, 2014; Hanley and Hoberg, 2019)、财报复杂性(Guay, Samuels, and Taylor, 2016)、文本语调(Loughran and McDonald, 2011; Jiang, Lee, Martin, and Zhou, 2019)、融资约束(Buehlmaier and Whited, 2018)以及文本主题(Brown, Crowley, and Elliott, 2020)等方面内容。也有很多研究则聚焦管理层电话会议,探究CEO和CFO的语言特征(Larcker and Zakolyukina, 2012; Davis, Ge, Matsumoto, and Zhang, 2015; Jiang, Lee, Martin, and Zhou, 2019; Bochkay, Chychyla, and Nanda, 2019)、语调分散度(Allee and DeAngelis, 2015)、语言复杂性(Bushee, Gow, and Taylor, 2018)、极端语言(Bochkay, Hales, and Chava, 2020)等方面的内容。还有不少文献选取股东报告、CEO日志文本以及盈余公告等作为文本来源展开研究(Hwang and Kim, 2017; Cardinaels, Hollander, and White, 2019; Bandiera, Prat, Hansen, and Sadun, 2020)。
国内关于上市公司披露类文本方面的研究相对较少。丘心颖、郑小翠和邓可斌(2016)针对上市公司年报构造复杂性与可读性指标,并分析其与分析师跟踪、预测质量之间的关系。林乐和谢德仁(2016)基于我国上市公司2005-2012年年度业绩说明会文本的管理层语调数据,利用文本分析方法实证检验我国投资者是否会听话听音。王雄元、高曦和何捷(2018)基于2007-2016年上市公司年度报告MD&A部分中与风险有关的信息,从文本相似度视角研究年报风险信息披露与审计费用的关系。曾庆生、周波、张程和陈信元(2018)基于中国A股非金融公司2007至2014年年报语调进行文本分析,探究年报语调与年报披露后的内部人交易行为之间的关系。You(2018)与Yan, Xiong, Meng, and Zou(2019)均着眼于2007-2016年中国A股市场1320份IPO招股说明书,探究IPO招股说明书的负面基调、不确定性与投资者对新上市公司的初评估以及IPO后收益率、波动率的关系。
(三) 媒体报道类文本来源
国外媒体报道类文本研究相当丰富。大量研究基于媒体报道类文本,为政策不确定性与媒体的经济后果提供了经验证据。例如,Baker, Bloom, and Davis(2016)基于美国10家主要报纸[7]构建了月度经济政策不确定性指数。Gulen and Ion(2016)选取1987年1月到2013年12月的新闻计算政策不确定性指数,并探讨其与公司资本投资之间的关系。Manela and Moreira(2017)选取1889年至2009年华尔街日报的头版文章作为数据集,构建基于文本的指标,以度量人们对不确定性的感知。同样地,Bonaime, Gulen, and Ion(2018)探讨了经济政策不确定性如何影响企业并购。除了用于构造政策不确定指数,媒体报道类文本还能够用来分析媒体情绪。Gurun and Butler(2012)收集当地报纸发布的公司特定新闻数据,比较当地媒体在报道本地与非本地公司的新闻时,负面词汇的使用是否有差异。Frank and Sanati(2018)聚焦《金融时报》在1982年4月1日至2013年9月30日期间发布的新闻报道,发现市场对积极或消极的新信息冲击的反应存在明显差异。Baloria and Heese(2018)则统计了与企业相关的负面新闻数量变化,研究得出企业可以通过预期行动来管理其声誉资本。此外,Hillert, Jacobs, and Müller(2014)根据1989年至2010年间45家美国国家和地方报纸的220万篇文章,探索媒体报道与投资者偏见之间的关系。Allee and DeAngelis (2015)收集与上市公司并购谣言相关的首份新闻报道,研究了媒体准确性的影响因素及其对资产价格的影响。Kogan, Moskowitz, and Niessner(2018)则聚焦于金融市场的不实新闻,并探究其对股票市场的影响。
中国证监会规定上市公司必须在“七报一刊”[8]中公布相关信息,同时我国还拥有百度新闻、和讯网等网络新闻媒体,拥有丰富的媒体报道类文本信息。饶育蕾、彭叠峰和成大超(2010)搜集2000-2007年我国上市公司在新华网、人民网等77家网络媒体的新闻报道,基于新闻条数构建媒体注意力指数。游家兴和吴静(2012)选取目前在我国具有广泛影响力,知名度和权威性均很高的8家全国性财经报纸[9],从报道基调、曝光程度、关注水平三个维度构建了衡量媒体情绪指数的综合评价指标体系。汪昌云和武佳薇(2015)以中国证券报、上海证券报、证券日报和证券时报四大财经媒体以及金融时报和证券市场周刊两大专业金融媒体,构建媒体语气以度量公司层面投资者情绪。Piotroski, Wong, and Zhang(2017)选取2000-2010年177万篇关于中国上市公司的国内报纸文章,研究发现官方报纸与非官方报纸目标不同。王靖一和黄益平(2018)基于和讯网逾1700万条新闻文本数据,构建了2013年1月至2017年9月的金融科技情绪指数。Huang and Luk(2020)则以十大中国报纸[10]为研究对象,构建2000-2018年中国经济政策不确定性月度指数。
(四) 其他类文本来源
除了上述几类来源,文本信息还有网络搜索数据、分析师报告、年度问询函、专利文本、P2P网络借贷文本等诸多类型的来源。
国外其他类文本分析研究的文本来源主要包括网络搜索数据、分析师报告、年度问询函与专利文本。通过谷歌网络搜索的文本数据信息可以有效衡量不同股票、不同地区、不同关键词的谷歌搜索指数,进而反映投资者关注度并预测股价(Da, Engelberg, and Gao, 2011;Chi and Shanthikumar, 2017;Da, Engelberg, and Gao, 2015)。另外,Huang, Zang, and Zheng(2014) 与De Franco, Hope, Vyas, and Zhou(2015)则聚焦分析师报告文本,分别研究分析师文本语调与可读性。此外,Ryans(2020)将年度问询函进行分类,探讨其与财务报告质量的关系。也有不少学者关注专利文本数据,使用机器学习方法对创新进行分类并计算相似度(Chen, Wu, and Yang, 2019;Kelly, Papanikolaou, Seru, and Taddy, 2018)。
国内其他类文本研究的文本来源主要包括网络搜索数据、P2P网络借贷文本与分析师报告文本。俞庆进和张兵(2012)、曾建光(2015)分别基于百度网络搜索指数构建投资者关注度指标与投资者网络安全风险感知指标。而随着2007年以来国内P2P网络借贷的兴起,不少学者针对P2P网络借贷文本展开研究,包括P2P网络借贷成功率、借款利率、筹资效率等方面(陈霄、叶德珠和邓洁,2018;彭红枫和林川,2018)。马黎珺、伊志宏和张澈(2019)则对2009-2015年间我国A股上市公司发布的分析师报告采用支持向量机进行文本分类。
三、文本分析技术维度
本部分针对不同的文本分析技术分别进行介绍,主要包括:主题分析、词典法、词袋法、监督学习、无监督学习与自然语言处理。如图1所示,从主题分析到自然语言处理,文本分析技术的自动化程度逐渐提高。
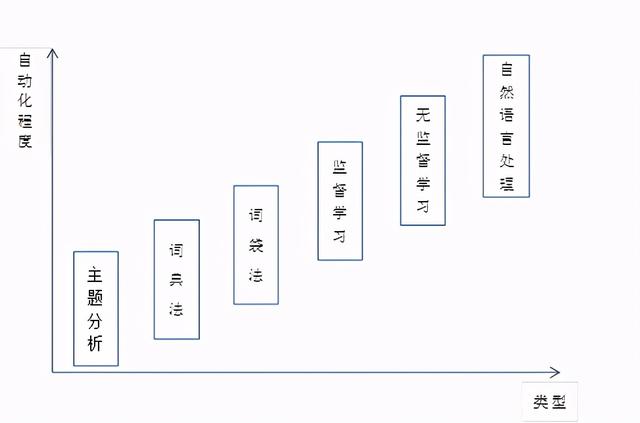
图1. 文本分析技术比较
(一)主题分析
主题分析(Thematic Analysis)是一种专家方法,需要有经验的人员基于自身经验和理解,对所研究数据进行挖掘与编码。主题分析一般与扎根理论方法相结合,基于专家自身经验和对世界的理解,产生对数据的见解,从而构建新理论(Baumer, Mimno, Guha, Quan, and Gay, 2017)。主题分析编码过程为迭代进行,在分析开始之前研究人员尚不知道类别,需要对文献和数据进行不断地比较,通常从参与者自己的语言开始(一阶编码),然后将相似的代码归为一类(二阶代码),从而开发出一系列源自文本的代码和类别(Strauss and Corbin, 1998)。主题分析常见于社会学与管理学,使用NVivo和ATLAS.ti等计算机软件可以帮助简化相关过程,但文本的分类依赖于人类编码,计算机自动化程度较低。
主题分析的优点在于使用参与者自身的认知来挖掘数据,对少量文本的理解更为深入。局限性在于其属于时间、劳动力密集型任务,不适合大规模样本,同时由于编码人员的经历和偏好不同,故编码标准不统一。
(二)词典法
词典法(Dictionary Analysis)是一种运用词典对特定文本的词语/词组的词频统计计数,将定性的文本数据压缩成定量的词组频数的文本分析技术(Reinard, 2008;Short, Broberg, Cogliser, and Brigham, 2010;Mckenny, Aguinis, and Anglin, 2016)。运用词典法的关键是具备成熟且适合所研究领域的词典,若无则需要研究者根据研究问题与文本数据,结合领域的相关专业知识构建适配的词典并加以验证。国外已先后形成了多部比较成熟的英文文本词典,如Henry词典(Henry Word Lists)、LM词典(Loughran and McDonald Word Lists)、哈佛大学通用调查词典(Harvard General Inquirer Word Lists)、文辞乐观与悲观词典(Diction Optimism and Pessimism Word Lists)等。国内大多数学者在参考英文词典及其他词库的基础上针对中文文本构建自己的词典并展开研究,如台湾大学NTUSD简体中文情感词典、知网Hownet情感词典、清华大学李军中文褒贬义词典等。一旦拥有适配的词典,则可以采用计算机软件协助文本内容分析过程,如采用软件LIWC、DICTION、Nvivo、ATLAS.ti、Python等,计算机自动化程度较高,人工工作量较低。词典法通常被运用于管理学,可运用于计算分析文本的语调情感等。
与主题分析相比,词典法的优点在于能够对所研究的文本信息进行定量分析,既大大提高了文本处理的效率,也加深了读者对于文本含义或者性质的理解与把握,同时还增强了研究的可复制性。它的局限性在于针对特定文本构建词典时,需要相关领域的专业知识,因而导致构建出来的特定词典与其他文本适配度不高,另外,词典法会忽略文档的上下文关系。
(三) 词袋法
词袋法(Bag-of-words)建立在文字词组语序不重要的假设之上,是一种将文本看作是若干个词语的集合,只计算每个词语出现次数的文本向量化的表示方法,它能将非结构化的定性的文本数据转换成计算机能理解、能直接使用的向量。词袋法是计算科学领域对文本数据的简化和压缩的方法,后续可以据此进行进一步监督学习和无监督学习,常被应用于管理学领域,可用于计算分析文本相似度等。词袋法同样可以采用计算机软件协助文本内容的分析过程,计算机自动化程度较高,人工工作量较低,如采用软件Python中的scikit-learn、gensim、nltk或者软件R中的topicmodels、stm等。
词袋法主要包括独热表示法(one-hot representation)以及词频-逆文档频率法(term frequency-inverse document frequency, TF-IDF)两种。独热表示法即将多个文档文本组织成一个文档特征矩阵,矩阵中每行代表一个文档,每列代表一个特征词,每个元素衡量每个文档中对应特征词的出现频数。而词频-逆文档频率法的主要思想是:如果某个词或短语在一篇文章中出现的频率高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。TF-IDF等于TF * IDF,TF为词频,指某一个给定的词语在该文件中出现的频率;IDF为逆向文件频率,度量词语普遍重要性,某一特定词语的IDF可以由总文件数目与包含该词语的文件数目的商取对数得到。
词袋法的编码过程忽略了词语先后顺序,因而无法反映上下文含义,牺牲文本的很多信息,变通性弱,文本分析深度低,同时当文档中词语数量过多时,向量维度过高而可能产生维度灾难。词袋法的优点则在于编码标准稳定统一,具有统计学特性与强扩展性。
(四) 监督学习
监督学习(Supervised Learning)是指将输入数据x和对应标签y作为训练集,以建立合适的模型来学习两者之间的关系,并使用所确定的模型来预测未知样本。有监督学习中预设的标签使得分类目标明确,而算法则可映射输入与输出之间的联系(Janasik, Honkela, and Bruun, 2009)。监督学习常被运用于计算机科学、政治学与管理学,可采用软件Python中的scikit-learn、gensim、nltk或者软件R中的topicmodels、stm等实现。衡量监督学习模型预测效果可采用以下评价指标评估:准确率、查准率、查全率、F得分、AUC等。有监督学习包括支持向量机、线性回归、逻辑回归、朴素贝叶斯、线性判别分析、决策树、K-近邻等。其中,朴素贝叶斯和支持向量机技术是常用的用于文本分析的监督学习算法(Schütze, Manning, and Raghavan, 2008)。
朴素贝叶斯是一种基于贝叶斯理论的有监督机器学习算法。其思想基础为根据贝叶斯条件概率公式计算已知文档属于不同文档类别的条件概率,并把该文档归为具有最大后验概率的一类文档类别。朴素贝叶斯算法优点在于算法较为稳定,缺点为数据集的属性之间往往都存在着相互关联,导致不满足数据集属性的独立性要求,进而影响分类效果。
支持向量机建立在统计学习理论和结构风险最小原理等基础理论上。支持向量机的优化目标是最大化分类间隔,基本思想是求解能够正确划分训练数据集且几何间隔最大的分离超平面。支持向量机不仅能解决非线性分类问题,还能有效避免“维数灾难”的发生,在解决小样本、非线性及高维模式识别中表现出许多特有的优势。该方法的局限为分类结果对核函数的选择较为敏感。
有监督机器学习算法的优点是允许研究者事先定义编码规则,逻辑简单,目标明确,同时适应于海量数据的研究,精确度较高。而局限性在于,不仅需要有高质量的标签变量,且训练的模型由于特征词太多容易导致过拟合。
(五) 无监督学习
无监督学习(Unsupervised Learning)指根据类别未知(没有被标记)的训练样本解决模式识别中的各种问题。与监督学习相比,无监督学习不需要给数据打标签,缺乏具有明确目的的训练方式,无法提前预知结果,也很难量化预测效果。无监督学习常被运用于计算机科学、政治学与管理学,可采用软件Python中的scikit-learn、gensim、nltk或者软件R中的topicmodels、stm等实现。聚类和降维技术是常用的用于文本分析的无监督学习算法。
聚类算法的关键是计算相似度,聚类的目的在于把相似的东西聚在一起。聚类算法分为划分方法和层次方法两种算法。划分聚类算法通过优化评价函数把数据集分割为K个部分,需要K作为输入参数,如K-means算法,K-medoids算法、CLARANS算法等。层次聚类由不同层次的分割聚类组成,层次之间的分割具有嵌套的关系,不需要输入参数,但是终止条件必须具体指定,如BIRCH算法、DBSCAN算法和CURE算法等。
常用的文本降维方法是隐含狄利克雷分布(Latent Dirichlet Allocation, 简称LDA)主题模型(Blei, Ng, and Jordan, 2003)。LDA是一种文档主题生成模型,包含词、主题和文档三层结构,可以用来识别大规模文档集或语料库中潜藏的主题信息。它认为一篇文章的每个词都是通过“以一定概率选择了某个主题,并从这个主题中以一定概率选择某个词语”这样一个过程得到。LDA模型的优势在于不需要研究者为划分类别预先指定相应的规则和关键词,文本主题分类精确且具有可复制性。局限性在于预设主题个数仍具有人的主观因素。
无监督学习的优点在于加速了数据的标注与分类,人工工作量较低。缺点为“标注”是机器按照数字特征进行的分组,需要研究者解读才可以赋予“标注”的意义,同时训练过程需要大量的调参。
(六) 自然语言处理
自然语言处理(Natural Language Processing, 简称NLP)是文本分析中自动化程度最高的形式。NLP以语言为对象,利用计算机技术模拟人类如何理解和处理语言,包括自然语言理解和自然语言生成,关注计算机和人类语言相互作用的领域(Joshi, 1991; Chowdhury, 2003;Schütze, Manning, and Raghavan, 2008;Collobert et al, 2011)。NLP考虑单词或者文字的先后顺序,可以标记句子中单词的词性(例如,名词,形容词等),将文档从一种语言翻译成另一种语言,甚至能使用句子的上下文来阐明词语的词义(Buntine and Jakulin, 2004)。NLP是一个完全计算机自动化的过程,不需要人类的理解或解释,具有丰富的用途,如采用深度学习和多模式等尖端技术进行情感分析(Kouloumpis, Wilson, and Moore, 2011)。NLP在计算机科学,信息科学,语言学和心理学等领域多被用作文本分析工具(Chowdhury, 2003),可采用Python中的nltk实现。
常见的NLP算法有词嵌入(Word Embedding)、长短期记忆网络(Long Short-Term Memory)、深度自注意力网络(Transformer)、基于语义理解的深度双向与训练模型(Bidirectional Encoder Representation from Transformers)等。NLP的优点在于计算机自动化,系统性强,能够分析语义,且执行速度快。局限性为大多数模型是个黑箱,可理解性差,模型训练比较耗时。
四、文本特征提取维度
目前,在财务与会计研究中,已有文献主要抽取的文本特征包括如下七个维度:文本情绪、文本可读性、文本相似度、文本摘要、文本主题、文本分类以及文本数量,如图2所示。
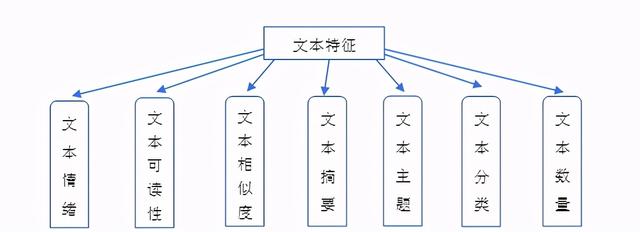
图2. 文本特征提取维度
(一) 文本情绪
文本情感分析是指对包含作者的观点、喜好、情感等的主观性文本进行检测、分析以及挖掘。文本情绪或语调分析的研究主要采用词典法和有监督机器学习方法。
运用词典法进行文本情绪分析时,除了选择准确的词典,还需要选择合适的加权方法(Jegadeesh and Wu, 2013)。多数学者使用简单比例加总权重法衡量文本情绪,公式为:
Tone=
(1)
其中Pos与Neg分别表示积极、消极词数占文本总词数的比例,Tone为净正面语调指标,Tone越大表明语调越积极。已有研究采用词典法衡量媒体报道情绪(Tetlock, 2007; Tetlock, Saar‐Tsechansky, and Macskassy, 2008; 游家兴和吴静,2012; Garcia, 2013; Solomon, Soltes, and Sosyura, 2014;汪昌云和武佳薇,2015;Frank and Sanati, 2018;Baloria and Heese, 2018)、电话会议文本语气语调(Price, Doran, Peterson, and Bliss, 2012;Larcker and Zakolyukina, 2012; Allee and DeAngelis, 2015;Davis, Ge, Matsumoto, and Zhang, 2015;Frankel, Jennings, and Lee, 2016; 林乐和谢德仁,2016;朱朝晖、包燕娜和许文瀚,2018;王靖一和黄益平,2018; Jiang, Lee, Martin, and Zhou, 2019; Bochkay, Hales, and Chava, 2020)、年报的语气语调(Loughran, McDonald, and Yun, 2009; Feldman, Govindaraj, Livnat, and Segal, 2010; Loughran and McDonld, 2011; Mayew, Sethuraman, and Venkatachalam, 2015;曾庆生、周波、张程和陈信元,2018;Jiang, Liu, and Yang, 2019)、社交网络文本语调(Chen, De, Hu, and Hwang, 2014;Renault, 2017; Cookson and Niessner, 2020)及其他文本语调(彭红枫和林川,2018;Cardinaels, Hollander, and White, 2019)进行分析。
有监督机器学习算法也是常用的研究文本情绪的方法。许多研究采用朴素贝叶斯进行文本情绪分类(Das and Chen, 2007; Li, 2010; Jegadeesh and Wu, 2013;Huang, Zang, and Zheng, 2014),还有研究采用支持向量机进行文本情绪分类(Antweiler and Frank, 2004)。
(二) 文本可读性
文本可读性是指文本信息能够被读者理解的程度(Dale and Chall, 1949;Mc Laughlin, 1969)。文本可读性高低会影响读者对于文本编辑者传达信息的理解,进而对读者的行为与决策产生影响。文本可读性通常采用迷雾指数(Gunning, 1952)、Flesch /Flesch-kincaid指数(Flesch, 1948; Thomas, Hartley, and Kincaid, 1975)、文本长度(You and Zhang, 2009)、文本电子档大小(Loughran and McDonald, 2014)衡量。早期的文本可读性研究多为小样本研究(Lewis, Parker, Pound, and Sutcliffe, 1986)。Li(2008)首次在大样本下研究年报可读性,并采用迷雾指数和年报长度度量可读性。往后多数文章采用迷雾指数衡量文本可读性(Li, 2010; Lehavy, Li, and Merkley, 2011;Lawrence, 2013)。较高的文本可读性可以更好地向投资者传递与公司相关的信息,带来正向的经济后果,例如改善分析师盈余预测、增加信息不对称、提高股票交易量、提高公司价值、提高借款成功率等(Lehavy, Li, and Merkley, 2011;Guay, Samuels, and Taylor, 2016;Lo, Ramos, and Rogo, 2017;Bushee, Gow, and Taylor, 2018;De Franco, Hope, Vyas, and Zhou, 2015;Hwang and Kim, 2017;Frankel, Jennings, and Lee, 2016;丘心颖、郑小翠和邓可斌,2016;陈霄、叶德珠和邓洁,2018)。
然而采用迷雾指数衡量文本可读性仍然存在如下一些局限:一方面,在度量商业文本时难以区分公司复杂性与年报可读性(Loughran and McDonald, 2016);另一方面,迷雾指数忽略了语言的语序和逻辑关系(Jones and Shoemaker, 1994)。之后出现了更多改进的衡量文本可读性的指标,包括为捕捉更全面的文本特征而创建的StyleWriter软件包中的Bog指数(Bonsall IV, Leone, Miller, and Rennekamp, 2017)以及采用支持向量机之类的机器学习算法等(任宏达和王琨,2018)。
(三) 文本相似度
文本相似度是从文本信息中抽取的重要文本特征之一。度量文本相似度通常有以下几种方法:基于关键词匹配的传统方法,例如,采用N-gram相似度;将文本映射到向量空间,计算余弦相似度等指标;采用深度学习算法,包括基于用户点击数据的深度学习语义匹配模型DSSM,基于卷积神经网络的ConvNet,以及Siamese LSTM等。目前使用较多的是采用余弦相似度指标来衡量文本相似度(Hober and Phillips, 2010;Hober and Phillips, 2016;Kelly, Papanikolaou, Seru, and Taddy, 2018; 王雄元等,2018)。文本相似度的研究角度较多,不仅可以研究不同企业之间披露文本的相似度(Hober and Phillips, 2010; Hober and Phillips, 2016),还可以研究同一企业不同时期披露文本的相似度(Brown and Tucker, 2011; Lang and Stice-Lawrence, 2015)。
(四) 文本摘要
文本摘要自动生成即使用计算机算法自动压缩文本内容,采用精炼的话概括总结文本文档的中心思想,使读者通过阅读摘要即可了解原文表达的含义。文本摘要自动生成有两种:抽取式(Extractive),即从原文中找到关键的句子并组合成摘要,如TextRank等;摘要式(Abstractive),即计算机读懂原文的内容并重新生成新句子组成摘要,如Seq2Seq等。目前研究相对成熟的是采用抽取式方案生成文本摘要。Cardinaels, Hollander, and White(2019)首次采用文本摘要生成法研究盈余公告、及其对投资者估值的影响,为使用计算机研究投资者行为提供了思路,其比较了机器生成的摘要和管理层披露的摘要在偏见和信息含量等特征上的差异,并分析了不同类型的摘要如何影响投资者对公司的估值。随后越来越多的文章采用文本摘要自动生成法进行研究(Blaseg and Bannier, 2019),并积极探索新的文本摘要自动生成技术(Hernandez-Castaneda, Garcia-Hernandez, Ledeneva, and Millan-Hernandez, 2020)。
(五) 文本主题
文本主题提取即抽取最能够体现文本内容主题的关键词,可用于提取年报、新闻、电话记录等文本的主题,通常采用LDA主题模型、TF-IDF模型、TextRank算法等技术手段。Campbell, Chen, Dhaliwal, Lu, and Steele(2014)第一个将LDA模型应用于风险披露文本,通过从风险披露文本中提取风险因素,发现事前风险较高的公司会披露更多的风险因素,且风险披露信息显著影响事后的贝塔系数、股票回报波动率。进一步,Bao and Datta(2014)提出了一种无监督的主题模型sent-LDA,更精确地从风险披露文本中提取风险类型,并研究了风险类型对投资者风险感知的影响。此外,Hanley and Hoberg(2019)结合LDA模型和Word2Vec技术,从银行年报中提取与风险相关的语义主题,发现金融行业新显露的风险信号有助于监管金融市场的稳定性。Brown, Crowley, and Elliott(2020)则使用LDA算法,提取财务报告的主题并研究对错报的预测能力,发现文本、语言特征能够捕捉管理层操纵企业财务信息的行为。
(六) 文本分类
文本分类是指采用计算机对文档集按照一定的分类体系或标准进行自动分类与标记的方法。具体而言,即根据一个已经被标注的训练文档集合,找到文档特征和文档类别之间的关系模型,然后利用这种学习得到的关系模型对新的文档进行类别判断。文本分类方向包括二分类、多分类与多标签分类。文本分类方法可划分为传统机器学习方法(如朴素贝叶斯,支持向量机等)与深度学习方法(FastText, TextCNN等)。例如,Antweiler and Frank(2004)采用朴素贝叶斯与支持向量机算法将股吧留言划分为买入、持有、卖出三类。Larcker and Zakolyukina(2012)根据成熟的词典,统计各类词汇在CEO/CFO电话会议记录中的词频,然后训练二项逻辑回归模型来识别欺骗性管理层讨论。Frankel, Jennings, and Lee(2016)应用支持向量回归的算法,研究了MD&A的文本内容对当期应计项目的解释能力、对未来现金流的预测能力。Manela and Moreira(2017)选取华尔街日报的头版文章作为数据集,得到468091个维度的向量,然后以期权隐含波动率作为被解释变量,采用支持向量机训练模型进行文本分类。Ryans(2020)运用朴素贝叶斯文本分类方法,将问询函划分为重述问询函和非重述问询函、减值问询函和非减值问询函。Bandiera, Prat, Hansen, and Sadun(2020)则通过机器学习算法将CEO划分为“领导者”和“管理者”,研究CEO行为与企业绩效的关系。
(七) 文本数量
文本数量能够用来刻画与指定主体相关的某类文档的累计数量,通常被研究者计算以构造投资者关注度、媒体关注度等指数。例如,在投资者关注度方面,Antweiler and Frank(2004)发现以股吧帖子数量衡量的投资者关注度指标能够有效地预测股票收益率和市场波动情况。同样地,股票的搜索频率、百度指数以及位置搜索数等也分别被研究者所采用以衡量投资者关注度(Da, Engelberg, and Gao, 2011; 俞庆进和张兵, 2012; Chi and Shanthikumar, 2017)。在媒体关注度方面,饶育蕾、彭叠峰和成大超(2010)基于新闻条数构建媒体注意力指数,检验了媒体注意力与股票收益率之间的关系。Hillert, Jacobs, and Müller(2014)也得到了类似的结论。除上述两类指数以外,Da, Engelberg, and Gao(2015)还选择了30个最负面的词语作为特定搜索关键词以构建FEARS指数。曾建光(2015)根据“余额宝被盗”的百度搜索指数构建了投资者网络安全风险感知指标。
五、文本分析应用维度
非结构化的文本数据包含着大量的信息,针对以上文本来源,文本分析研究的文献运用文本挖掘方法抽取文本特征,有助于获得传统结构化数据以外的数据信息,并探讨了这些文本特征与企业表现、股票市场行为等之间的关系。目前文本分析应用维度主要包括预测分析与因素分析两大类。
文本信息能够用来预测市场反应。Antweiler and Frank(2004)的研究结果表明股票留言板的信息并非噪音,而是与财务相关的信息,能够预测交易量和波动性。同样地,Das and Chen(2007)发现市场指数MSH与前一日的市场情绪显著相关。Loughran and McDonald (2011)构建了五个关于积极词汇、不确定性、诉讼、强势语调、弱势语调的词典,发现采用这些词典度量的语调与超额收益、交易量、回报波动率、未预期盈余等之间存在显著关系。马黎珺、伊志宏和张澈(2019)则研究得出前瞻性语句的情感积极程度与分析师报告发布后的投资者反应显著正相关。
文本信息也能够用来预测公司财务舞弊。Loughran and McDonald(2011)构建了五个词典,发现采用这些词典度量的语调能够用来预测公司财务舞弊。Larcker and Zakolyukina(2012)得出可以采用管理层在电话会议中的语言特征以识别财务错报。Brown, Crowley, and Elliott(2020)则研究财务报表的主题对公司财务错报的预测能力,发现年报的主题可用于预测财务错报。
文本信息还可以用来预测公司价值与未来发展。Li(2008)发现归因类、积极类、将来时态类词汇使用情况与公司盈余可持续性相关。Li(2010)研究了公司年报MD&A中前瞻性声明(FLS)的信息内容,发现能够预测未来期间公司盈利能力和流动性。饶育蕾、彭叠峰和成大超(2010)得出媒体关注度越高,公司下个月的平均收益率越低。Campbell, Chen, Dhaliwal, Lu, and Steele(2014)研究得出能够将风险披露信息用于预测事后的贝塔系数和股票回报波动率。Frankel, Jennings, and Lee(2016)发现MD&A的文本内容对未来现金流的预测能力。Manela and Moreira(2017)构建基于文本的指标(NVIX)以度量人们对不确定性的感知,并以此预测股票回报率和灾害。Renault(2017)研究得出前半小时内投资者情绪的变化能够有效预测当天最后半小时的回报率。马黎珺、伊志宏和张澈(2019)则证实前瞻性语句的情感积极程度与企业未来的收益增长、投资规模以及创新成果均显著正相关。
文本信息除了可以用作预测分析,还可以进行因素分析,以探究不同股票市场现象、公司特征以及管理层行为等的影响因素。Li(2010)研究了公司年报MD&A中前瞻性声明(FLS)的信息内容,发现当期绩效较好、应计项目较低、规模较小、市净率较低、股票收益波动率较低、MD&A的迷雾指数较低、历史较长的企业,倾向于有较积极的FLS语调。Bao and Datta(2014)发现宏观经济风险、流动性风险与风险感知显著正相关,而人力资源风险、规章变动风险、基础设施风险与风险感知显著负相关。Campbell, Chen, Dhaliwal, Lu, and Steele(2014)研究得出事前风险较高的公司会披露更多的风险因素,公司面临的风险类型决定了公司披露该风险的篇幅。Frankel, Jennings, and Lee(2016)聚焦MD&A的文本内容,发现其对当期应计项目具有解释能力。Cardinaels, Hollander, and White(2019)则将机器生成的摘要与管理层提供的摘要进行对比,发现管理层摘要会呈现出额外的积极偏差。
六、国内文本分析研究发表情况
为进一步考察文本分析文献的发表情况,本文以国内研究为例,选取1994—2020 年为时间窗口,以30本国家自然科学基金认定的重要管理学期刊以及《审计研究》、《中国会计评论》、《财贸经济》、《经济理论与经济管理》、《经济研究》、《中国社会科学》、《世界经济》、《经济学动态》、《北京大学学报(哲学社会科学版)》、《复旦学报(社科版)》、《国际贸易问题》、《心理学报》、《中国人民大学学报》、《新华文摘(全文转载)》、《人民日报(理论版)》、《系统管理学报》、《光明日报(理论版)》、《统计研究》、《产业经济评论(以书代刊)》、《经济学(季刊)(以书代刊)》、《营销科学学报(以书代刊)》、《中国会计评论(以书代刊)》、《中国会计与财务研究》23本期刊为来源,在知网中检索这些期刊中关键词包含“文本”的文献,并手工剔除学术讨论会综述、会议通知、征稿通知、消息、公示、期刊导读等非学术类文章以及隶属文学领域、检索系统方面等与文本分析研究无关的文献,最终获得学术论文318篇。本文统计的318篇学术论文主要包括如下两类:与文本分析研究的技术相关的学术论文,以及与财务与会计领域的文本分析的应用相关的学术论文。
1994—2020年期间文本分析文献年度分布如图3所示。由图可知,国内期刊中,首篇文本分析研究发表于1994年。1994—2009年,国内重要期刊上关于文本分析的文献每年不足10篇,此时文本分析研究没有引起过多的关注,相关研究成果不多。2010年,文本分析文献数量达到小高峰(10篇),其后至2013年,相关研究成果仍很少。2014年开始,文本分析研究逐渐增多,每年的发文量超过10篇,2017年后,每年的文献达到了二十余篇,且发表数量相对稳定。其后,文献数量迅速增加,尤其从2019年开始,每年文章超过了50篇,在2020年达到了历史新高(63篇)。总体而言,近七年来,国内的文本分析研究发文量迅速增加,这表明文本分析研究领域正愈发获得国内学者的关注。
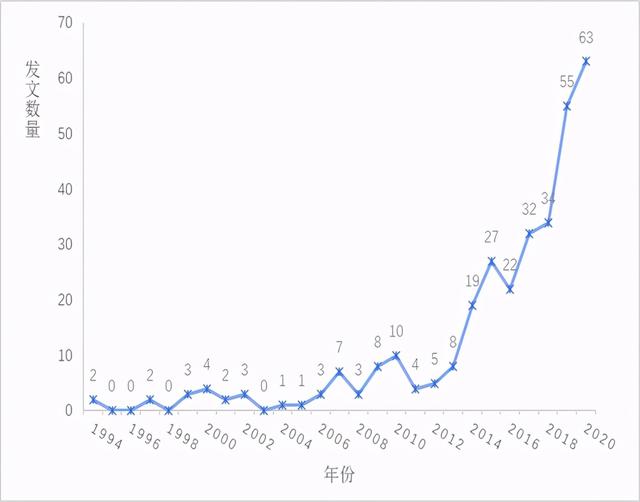
图3. 国内文本分析文献年度分布
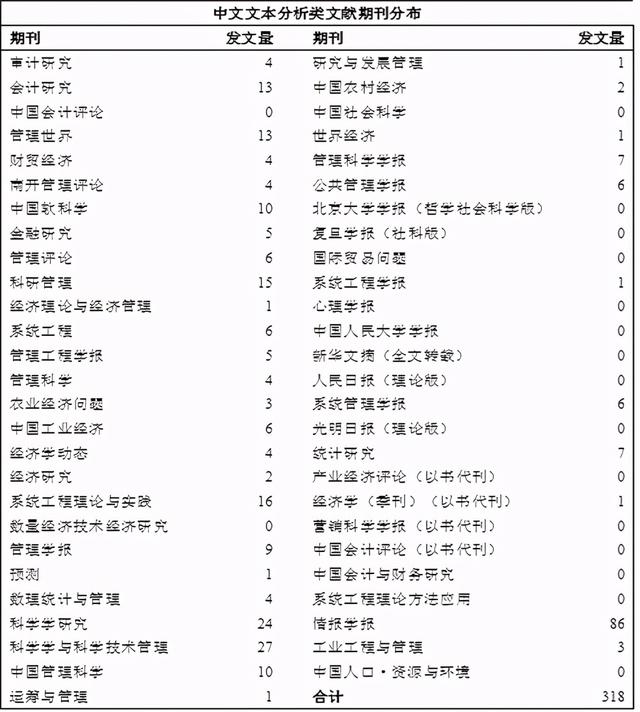
1994—2020年发表文本分析研究成果数排名前五的中文重要期刊分别为《情报学报》(86)、《科学学与科学技术管理》(27)、《科学学研究》(24)、《系统工程理论与实践》(16)与《科研管理》(15),具体各期刊的发文数量如表1所示[11]。
表1. 国内文本分析文献期刊分布
七、结论
本文根据不同的文本信息来源,梳理了国内外文本分析文献的研究内容,主要包括社交网络类文本、上市公司披露类文本、媒体报道类文本以及其他类文本等。本文总结并介绍了财务与会计研究领域主要使用的文本分析研究的技术,介绍了主题分析、词典法、词袋法、监督学习、无监督学习、自然语言处理六种文本分析技术。此外,本文将文献按照文本特征提取维度分别进行归纳,包括文本的情绪、文本可读性、文本相似度、文本摘要、文本主题、文本分类以及文本数量共七种文本特征。另外,本文总结了文本分析应用研究的角度,能够划分为预测分析与因素分析两大类。最后,本文回顾了国内文本分析研究的文献发表情况,从期刊分布与年度分布两个角度分别展开分析。本文针对文本分析研究的文献特征与研究进展进行系统介绍,有助于国内研究者了解文本分析技术与相关应用主题,有利于引起更多学者对于文本分析研究的重视。
我们认为,未来财务与会计领域有关文本分析的研究还可以从以下几个方面进一步深入探讨。首先,开拓更丰富的文本信息来源,例如公司招聘公告、业绩预告、日常经营公告、风险提示公告、公司债券预案、微信推送、政府工作报告、国务院政策文件、法院裁判文书等。其次,更多地运用自然语言处理技术进行文本分析,如今深度学习方法在自然语言处理领域已迅猛发展(如XLNet、BERT等),其不仅能够挖掘更丰富的研究内容与研究对象,还能提高文本信息提取的效率与准确性。接着,优化已有的文本信息特征指标,例如,构建更适合中国情境的情绪词典,采用深度学习法改进文本摘要自动生成方式与文本可读性衡量指标等。同时,挖掘与探讨更多的文本信息特征,如文本逻辑、文本可视化、文本复杂度等。另外,拓展财务与会计领域研究的视角,发现更多适合进行文本分析研究的主题,包括分析师行为、公司并购、审计师审计质量等。最后,提高研究的可复制性,将文本信息转化为结构化数据的过程相对比较复杂,指标、技术的选取往往很大程度影响研究结果,因此研究者应当详细地针对文档的预处理、特征抽取方式、词典选择以及算法细节等进行记录。
[1] 如办公文档、文本、图片、XML、HTML、各类报表、图像和音频视频。
[2] 据IDC研究表明,到2025年,全球数据量将会从2016年的16 ZB上升至163ZB。著名研究机构Garter也表示,全球信息量正在以59%以上的年增长率快速增长。而在这些数据中,结构化数据仅占到全部数据量的20%,其余80%都是以文件形式存在的非结构化数据,日志文件、机器数据等又占据非结构化数据的90%。
[3] 如金融行业的“双录”资料、医疗行业的影像资料、教育行业的教学文档、传媒行业的音视频素材,税务工商、社保等各类业务办理机构影像资料,公安执法的视频存档等等。
[4] 隐含狄利克雷分布(Latent Dirichlet Allocation)主题模型,多用于文档主题提取。
[5] 美国最大的投资相关社交媒体网站之一。
[6] 专注于金融市场的社交微博平台。
[7] 《今日美国》、《迈阿密先驱报》、《芝加哥论坛报》、《华盛顿邮报》、《洛杉矶时报》、《波士顿环球报》、《旧金山纪事报》、《达拉斯晨报》、《纽约时报》和《华尔街日报》。
[8] 《上海证券报》、《中国证券报》、《证券时报》、《金融时报》、《经济日报》、《中国改革报》、《中国日报》和《证券市场周刊》。
[9] 《中国证券报》、《证券日报》、《证券时报》、《上海证券报》、《中国经营报》、《21 世纪经济报道》、《经济观察报》和《第一财经日报》。
[10] 北京青年报、广州日报、解放日报、人民日报海外版、上海早报、南方都市报、新京报、今日晚报、文汇日报、羊城晚报。
[11]本次统计对较早年份的文献进行了人工筛选,手动剔除了本文选定的中文期刊中与文本分析无关的文献;由于《中国社会科学》、《北京大学学报“哲学社会科学版”》、《复旦学报“社科版”》、《心理学报》以及《中国人民大学学报》五本期刊中,以“文本”为关键词查找到的文献均属于文学领域,与本研究无关,所以进行了剔除处理;在《情报学报》期刊中,1989-2002年的文献多为检索系统方面的研究,本文将此类文献数排除在外;除上述处理外,《研究与发展管理》中有一篇文章与“超文本型组织”相关,《国际贸易问题》中的两篇以“文本”为关键词的文章并非真正意义上的本文分析,《统计研究》中有一篇文章属于统计科学研讨会会议纪要,一篇文章为期刊导读,故不将上述文章纳入统计范围。
原载:刘云菁、张紫怡、张敏:“财务与会计领域的文本分析研究:回顾与总结”,《会计与经济研究》,2021年第1期:1-21。
,