你也许听说过这种说法: 中文是最有效率的一种语言。同样一篇文章,比如联合国宪章,中文版本永远是最薄的。问题是这种说法到底科学吗?今天就跟大家聊聊这个问题。科学家确实找到了一种方法去衡量一种语言的效率,甚至可以定量分析,这就是"信息熵"。

1948年,英国数学家克劳德·香农提出了一个表征符号系统中单位符号平均信息量的指标–信息熵,还给出了一个计算信息熵的公式,这个公式十分简洁。请大家看下这期节目介绍,里面有这个公式:
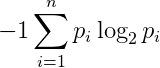
公式里出现的是指某种符号系统中,某个符号出现的频率。
比如文字就是一种符号系统,每个汉字就是一种符号。而频率就是某个字在全体文字材料中出现的比例。比如,如果你统计了一本一百万字的书,这本书中某个字出现了1万次,那么这个字的频率就是:1万/1百万=0.01=1%。
而香农这个公式就是要把某个符号系统中的符号频率全都统计出来,代入上述公式,就是这个符号系统的信息熵。
听上去有点抽象,我们来点实际运算就容易多了。比如,如果符号系统只有一个符号,信息熵会如何?
因为只有一个符号,那么它的频率必然就是100%,也就是1。1的对数是0,所以按这个公式的计算结果就是0。
这个结果就香农给出的解释是,如果一个符号系统只有1个符号,那么这个符号系统什么信息都不能传递,单个字符能传递的信息是0。如果一种文字只有一个字母a,一a到底,那么这种语言真的啥信息能不能传递。
那么两种符号会如何?我们先假设两种符号的出现频率都是50%=0.5。那么总信息熵,按照公式就是:

所以这种符号系统的信息熵就是1, 意思就是:这种符号系统的每个符号可以传递1比特信息。此时我们能看出之所以公式前面要有一个乘以-1,就是为了使结果总是大于等于0,因为人对正数的感受比较直观。
而我们的另一个发现是,影响信息熵的有两个因素:一个是符号的多少,一个是符号的频率分布。那我们可以固定一个变量,看看其中一个变量对信息熵的影响。
我们先假设每个符号的频率是相等的,字符数不断增加会如何?假设某符号系统有n个符号,每个符号的频率是1/n,则该系统的信息熵是:
即有n个符号的符号系统,它的信息熵是。也就是符号越多,信息熵越大。
那我们再考虑一下,如果符号数量固定,符号的频率分布改变,对信息熵的值影响如何?你稍加计算就会发现,如果符号的频率分布越不均匀,则信息熵越小。比如如果只有两个符号,其中一个符号的出现频率占90%,另一个只占10%,则代入公式,可以算出这种符号系统的信息熵是0.47左右。而之前算过两个符号频率相等的话,信息熵是1。
计算结果有了,我们来解读一下。先解读下为什么符号越多信息熵越大,也就是单个符号提供的信息越多。
你可以设想,英语不是26个字母,而是有1000个字母了。那么,即使元音字母还是只有a,e,i,o,u这5个,而每个单词要求至少有一个元音字母,那么用1000个字母,你也可能构造出个两个字母的单词。而大学英语六级的词汇量也就是6000左右,1万个单词已经非常多了。如果考虑三个字母的组合,那就够用了。
所以,英语文章如果可以用1000个字母的系统改写,那么几乎其中所有单词都可以用3个或更少的字母的组合来表示,这本书将大大变薄,所以单个字母的信息量是不是就增加非常多?
而汉字系统,恰恰有点像有几千个字母的拼写系统,所以中文单个字的信息熵会比字母会高。
再看看为什么符号频率越均匀,信息熵越高。这是因为符号频率越均匀,说明符号前后出现的关联性越小,也就是每个符号都很关键,都不能丢,所以符号信息量大。反之,符号出现的关联越强,则有些符号就可以省略了,说明这些符号提供的信息少。
比如,英语里,很多单词的拼写中的字母组合是经常一起出现的,比如ing, tion 等等。 这些组合中,你即使丢掉了一个字母,也不妨碍你阅读。网上曾经出现过一个段子,就是一长串英语句子,其中每个单词的拼写都丢掉了1-2个字母,但是你阅读起来完全无障碍,甚至你都不会注意到这些单词拼错了。这就说明这些字母提供的信息少。
而中文的话,字与字之间的关联就小多了,一句话丢掉很多字的话,这句话的意思就很难还原了。而关联小,也就是字与字之间出现的频率差距不大,你不容易猜到下一个字,这时,每个字提供的信息量就大。
那英语与中文的信息熵就究竟有多大?不久前国外知名数学博主John D.Cook就发表了一篇,他计算了一下中文的信息熵。他使用的中文词频数据是2004年,一位美国大学的发布在网上的。统计结果中,出现频率最高的汉字是 "的",大概是4.1%。第二位是"一",频率就只有1.5%了。Cook根据这个词频,计算出单个汉字的信息熵是9.56。而一般认为单个英文字母的信息熵为3.9,中文的优势是很大的。

(上图:美国大学研究者Jun Da 笪骏 jda@mtsu.edu,2004年对中文词频的统计)
但这样是否就可以说中文的信息熵比英文高一倍多呢?还不那么简单,因为信息熵的比较还有一些不确定因素,比如比较的对象。之前是比较英文字母和汉字,但你也可以比较英文单词和汉字。
实际上英文单词虽然组合多了,但是一句话前后的关联太多,所以单词的信息熵更低了,香农当初计算计算出单个英文单词的信息熵是只有2.62。你也可以对中文也按词来统计,但是中文怎么切词仍然是个问题。

(上图:香农计算的英语信息熵,英语单词的信息熵只有2.62。"27 letter"是指将"空格"也作为一个字母统计。)
另外一个因素是有关词频的统计。同样是中文,古文和白话文的词频肯定是不一样。不同领域里的文章里的词频也会有很大差异 。不过有一点确定的是,不论哪种语言,数学论文的单位字符信息熵肯定远大于其他类型的文章,这也是数学论文那么难懂的原因。数学家是能用公式,就不用文字,能用"显然"或"易得"就绝不给你展开。往往一个公式你就要在那里琢磨好几分钟。而大老李虽然讲的啰嗦点,但是能让你懂对不对?

(上图:某数学论文的一页)
但不管怎样,目前不同统计方式下中文的信息熵都还是领先的。 Cook提出了一种新的比较标准,即不同语言在单位时间内的输出信息量,并且他提出一个猜想:不同语言在单位时间内输出量是接近的。比如同样一本圣经,中文版肯定比英文版薄,但是让你抄写一遍,因为中文笔画多,中文抄得比较慢,所以最终抄写时间可能差不多。
当然,现在电脑时代,更应该比较在电脑上输入的时间。我觉得可以比较一下平均输入一本中英文版圣经所需要的打字次数(均使用最佳带联想功能的输入法),望有心的读者可以尝试研究。
另外,如果考虑语音输出的效率,会有一些更有意思的发现。有一点是可以肯定,中文当以语音形式输出时,单个汉字的信息量大大减少,因为汉字至少有5千多个,但是对发音组合,考虑声调时,大概只有1200多种,不考虑声调的话 ,只有300多种组合。如果像大老李这样前后鼻音不区分的人,信息量就丢失更多了。这就可以解释生活中的很多现象。
中文带声调拼音组合频率前十为: de, 4.63% shi4, 2.23% yi1, 1.71% bu4, 1.49% ta1, 1.21% zai4, 1.13% le, 1.10% ren2, 0.97% you3, 0.96% shi2, 0.90%
中文无声调拼音组合频率前十为: de, 5.05% shi, 3.60% yi, 3.04% ji, 1.58% bu, 1.52% zhi, 1.42% you, 1.42% ta, 1.23% ren, 1.20% li, 1.20%
比如:中文没法改成拼音文字,写出来完全没法读,同音字太多。
(上图:只有拼音的文章念起来是很累的)
再比如:大家玩过一个耳语传话的游戏,就是一些人,以耳语的形式把一句话传给下一个人,结果到6、7人之后这句话就被传的面目全非。下次各位可以试试看看传一句简单的英语,看看是不是容易保持原来的句子。
下次再有老外问:为什么你们中国人讲话总是这么大声?你可以回答: 为中文语音的信息熵低,我不得不大声说,确保对方每个字都听清楚。
另外,为什么很多人都讨厌微信上总是发语音的人,也可以用信息熵来解释,就是相比文字,语音在单位时间内接传递的信息太少了,也容易失真。
总之,Cook猜想,不同语言在单位时间的输出信息熵是类似的,这一点有兴趣的听众大可以自己研究一下。
再解释下为什么香农对这个表征信息量大小的这个指标命名为"信息熵"?它与物理中的"熵"有何联系?当然是有联系的。物理中的"熵"一种直观的定义就是表征一个系统的混乱程度,越混乱,熵值越大,越有序,则熵值越低。
维基百科上对"熵"的定义: 化学及热力学中所谓"熵"(英语:entropy),是一种测量在动力学方面不能做功的能量总数,也就是当总体的熵增加,其做功能力也下降,熵的量度正是能量退化的指标。熵亦被用于计算一个系统中的失序现象,也就是计算该系统混乱的程度。熵是一个描述系统状态的函数,但是经常用熵的参考值和变化量进行分析比较,它在控制论、概率论、数论、天体物理、生命科学等领域都有重要应用,在不同的学科中也有引申出的更为具体的定义,是各领域十分重要的参量。
那在信息熵中,为什么语言越"混乱",信息量也越大?这一点还是可以从语言的上下文关联度来考虑。比如英语单词中的字母相关度是很高的,之前提到过的ing, tion,还有等等各种前缀后缀。
因为相关度大,那么你看到ing或者在tion这样的后缀组合里拿掉一个字母,完全不影响阅读,说明这些组合中单个字母提供的信息量很小。而中文的上下文关联度就低很多,所以单个汉字信息量大。而上下文关联度高,也可以理解为符号系统越"有序",而关联度小就是越“无序”,所以把信息量用"熵"来命名再恰当不过了,而它确实与物理中的熵有许多类似性质。
最后,讨论下信息量的单位。从公式里看,信息熵是没有单位的,但有时我们也用bit作为其单位(就是计算机中,比特位的比特)。比如中文平均单个汉字信息熵是9.56,也可以说成,单个汉字提供的信息量是9.56比特。这是为什么呢?这其实是一个符号编码的问题。
现在我们的计算机系统中的字符一般采用的是等长的编码方式,即每个字符的编码长度是相等的。比如unicode编码系统中,每个字符用16bit的二进制位来编码。那么理论上,它可以对2^16=65536中字符进行编码,它已经足够对世界上所有文字符号进行编码,甚至现在我们还不断在其中增加表情符(emoji)。
(上图:unicode已经足够对世界上所有文字符号编码)
但如果你的目标是使目标文本的编码总长度最短的话,那么等长编码方式就不是最优方案了。因为每个字符的频率不同,我们可以考虑对频率高的字符用比较短的长度进行编码。
比如之前提到,中文文本中,"的"这个字的使用频率最高,那我就可以对"的"用1位的"0"进行编码,其他所有汉字都用"1"开始的二进位编码。中文中第二频率高的字符是"一",那就用"10"两位对它对编码,用"110"给第三位频率的汉字编码等等。这样频率高的汉字编码长度短,而且不同汉字的编码在开始的二进位都是可以区分的,所以可以互相之间还是可以区分。
这种编码方式在计算机算法中称为"哈夫曼编码"或"前缀码",因为不同的字符使用编码的前缀来区分。当然,汉字中"的"出现的频率,还没有高到值得用1位二进制对其编码。但有一种算法,可以根据不同字符的频率表,得出平均码长最短的编码方式,此时的编码结果称为"最优前缀码"。
在计算机数据处理中,霍夫曼编码使用变长编码表对源符号(如文件中的一个字母)进行编码,其中变长编码表是通过一种评估来源符号出现几率的方法得到的,出现几率高的字母使用较短的编码,反之出现几率低的则使用较长的编码,这便使编码之后的字符串的平均长度、期望值降低,从而达到无损压缩数据的目的。
而对某个汉字字符的频率表,如果你计算出信息熵是9.56,那对同一张频率表,对其进行最优前缀码编码,你会发现,单个汉字的平均编码长度就是9.56!(具体原因,请各位自行分析。)但也因此,我们也可以说,信息熵的单位就是"比特"。
到这里又会有一个很有意思的洞察,就是考察不同语言文本文件的压缩率。比如都是用unicode编码的中英文版圣经,分别比较用rar软件压缩后文件大小的变化量。因为压缩软件,本质上就是去除文本中的冗余信息,用接近最优编码方式对文件进行编码的方式,那么如果一个文本压缩后,能压缩的很小,就说明原来的文本信息比较冗余,单位字符的信息量低。反之,如果压缩后,文件大小变化不大,就说明原来的文本信息冗余量少,单位字符信息量大。
实际情况当然很多人也做了实验,中文也不负众望,中文本文的压缩率在各种语言的比较中,总是最低的,所以这也侧面验证了,中文是主流语言中最有效率的语言。
那么有关信息熵的话题聊的差不多了,我最大感想是香农用如此简单的一个公式,给了我那么多的启发和思考,我觉得以后,在提到"最美公式"的时候,香农的这个应该有一席之地。
而中文在符号上提供的信息量大,是基本上可以确定的。而中文在语音上会丢失的信息的劣势也是很明显的(所以大家爱看有字幕的视频)。
最后,为什么大家喜欢听播音演员的语音呢?可能就是他们清晰,详略得当,使得听众可以在单位时间内接收到恰好多的信息。而大老李因为没有受过训练,所以不可能达到播音演员的语音效果。但我可以保证,大老李的节目如果你都听懂的话,你在单位时间内接收到的信息量是很大的。下期再见!
,







