我们先从主成分分析PCA开始看。在解释这个方法之前,我们先快速回顾一下什么是特征的降维。在机器学习领域中,我们要进行大量的特征工程,将物品的特征转换成计算机所能处理的各种数据。通常,如果我们增加物品的特征,就有可能提升机器学习的效果。可是,随着特征数量不断增加,特征向量的维数也会不断升高。这不仅会加大机器学习的难度,还会形成过拟合,影响最终的准确度。针对这种情形,我们需要过滤掉一些不重要的特征,或者是将某些相关的特征合并起来,最终达到在降低特征维数的同时,尽量保留原始数据所包含的信息。了解了这些背景信息,我们再来看PCA方法。本节先从它的运算步骤入手讲清楚每一步,再解释其背后的核心思想。
14.1.1 PCA的主要步骤和协同过滤的案例一样,我们使用一个矩阵来表示数据集。我们假设数据集中有

个样本、

维特征,而这些特征都是数值型的,那么这个集合可以按照如表14-1所示的方式来展示。
表14-1 数据记录及其特征
|
样本ID |
特征1 |
特征2 |
特征3 |
... |
特征
|
特征
|
|
1 |
1 |
3 |
−7 |
... |
−10.5 |
−8.2 |
|
2 |
2 |
5 |
−14 |
... |
2.7 |
4 |
|
... |
... |
... |
... |
... |
... |
... |
|
|
−3 |
−7 |
2 |
... |
55 |
13.6 |



那么这个样本集的矩阵形式就是这样的:

这个矩阵是

维的,其中每一行表示一个样本,每一列表示一维特征。我们将这个矩阵称为样本矩阵,现在我们的问题是能不能通过某种方法找到一种变换,其可以减少这个矩阵的列数,也就是特征的维数,并且尽可能保留原始数据中的有用信息?针对这个问题,PCA方法提出了一种可行的解决方案。它包括以下4个主要的步骤。
(1)标准化样本矩阵中的原始数据。
(2)获取标准化数据的协方差矩阵。
(3)计算协方差矩阵的特征值和特征向量。
(4)依照特征值的大小挑选主要的特征向量,以转换原始数据并生成新的特征。
1.标准化样本矩阵中的原始数据之前我们已经介绍过基于Z分数的特征标准化,这里我们需要进行同样的处理才能让每维特征的重要性具有可比性。需要注意的是,这里标准化的数据是针对同一种特征,也是在同一个特征维度之内。不同维度的特征不能放在一起进行标准化。
2.获取标准化数据的协方差矩阵首先,我们来看一下什么是协方差(covariance),以及协方差矩阵。协方差用于衡量两个变量的总体误差。假设两个变量分别是
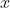
和

,而它们的采样数量都是

,那么协方差的计算公式就是如下这种形式:

其中,

表示变量

的第

个采样数据,
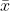
表示这

个采样的均值。当两个变量是同一个变量时,协方差就变成了方差。
那么,协方差矩阵又是什么呢?我们刚刚提到了样本矩阵,假设

表示样本矩阵

的第1列,

表示样本矩阵

的第2列,依次类推。
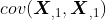
表示第1列向量和自身的协方差,
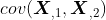
表示第1列向量和第2列向量之间的协方差。结合之前协方差的定义,我们可以得知:

其中,

表示矩阵中第

行、第

列的元素。

表示第

列的均值。有了这些符号表示,我们就可以生成下面这种协方差矩阵:
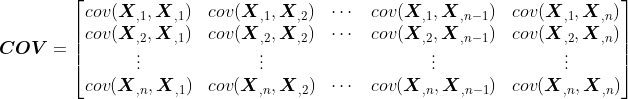
从协方差的定义可以看出,

,所以
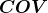
是个对称矩阵。另外,我们刚刚提到,对
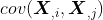
而言,如果
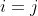
,那么
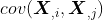
也就是
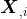
这组数的方差。所以这个对称矩阵的主对角线上的值就是各维特征的方差。
3.计算协方差矩阵的特征值和特征向量这里所说的矩阵的特征向量(eigenvector)和机器学习中的特征向量(feature vector)完全是两回事。矩阵的特征值和特征向量是线性代数中两个非常重要的概念。对于一个矩阵
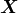
,如果能找到向量
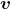
和标量

,使得下面这个式子成立:

那么,我们就说
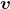
是矩阵

的特征向量,而
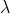
是矩阵

的特征值。矩阵的特征向量和特征值可能不止一个。说到这里,你可能会好奇,特征向量和特征值表示什么意思呢?我们为什么要关心这两个概念呢?简单来说,我们可以将向量

左乘一个矩阵

看作对

进行旋转或伸缩,如我们之前所介绍的,这种旋转和伸缩都是由于左乘矩阵

后产生的“运动”导致的。特征向量

表示矩阵

运动的方向,特征值

表示运动的幅度,这两者结合就能描述左乘矩阵X所带来的效果,因此被看作矩阵的“特征”。PCA中的主成分就是指特征向量,对应的特征值的大小就表示这个特征向量或者说主成分的重要程度。特征值越大,重要程度越高,越要优先使用这个主成分,并利用这个主成分对原始数据进行转换。
我们先来看看给定一个矩阵,如何计算它的特征值和特征向量,并完成PCA的剩余步骤。计算特征值的推导过程如下:


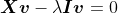
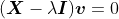
其中,

是单位矩阵。对于上面推导中的最后一步,需要计算矩阵的行列式:
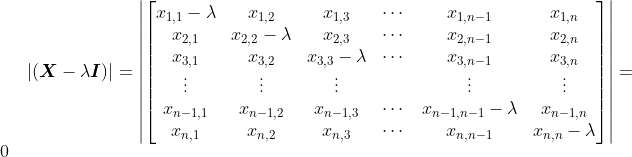
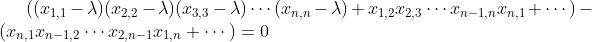
最后,通过解这个方程式,我们就能求得各种

的解,而这些解就是特征值。计算完特征值,我们可以将不同的

值代入

来获取特征向量。
4.依照特征值的大小挑选主要的特征向量假设我们获得了

个特征值和对应的特征向量,就会有:
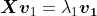
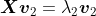
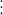
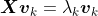
按照所对应的
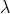
数值的大小,对这

组的
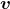
排序。排名靠前的

就是最重要的特征向量。假设我们只取

个特征中前

个最重要的特征,那么我们使用这

个特征向量,组成一个
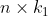
维的矩阵
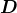
。将包含原始数据的

维矩阵
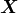
左乘矩阵

,就能重新获得一个
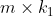
维的矩阵,从而达到降维的目的。
有的时候,我们无法确定

取多少合适。一种常见的做法是,看前

个特征值的和占所有特征值总和的百分比。假设一共有10个特征值,总和是100,最大的特征值是80,那么第一大特征值占整个特征值总和的80%,我们就认为它能表示80%的信息量,如果还不够多,我们就继续看第二大的特征值,它是15,前两个特征值之和是95,占比达到了95%,如果我们认为足够了,那么就可以只选前两大特征值,将原始数据的特征维数从10维降到2维。
所有这些描述可能有一些抽象,让我们尝试一个具体的案例。假设我们有一个样本集合,包含了3个样本,每个样本有3维特征

、

和

,对应的矩阵如下:

在标准化的时候,需要注意的是,我们的分母都使用

而不是

,这是为了和之后Python中sklearn库的默认实现保持一致。首先需要获取标准化之后的数据。第一维特征的数据是
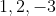
,均值是

,方差是

。所以,标准化之后第一维特征的数据是

,

,

。以此类推,我们可以获得第二维和第三维特征标准化之后的数据。当然,全部手工计算的工作量不小,这时可以让计算机做它擅长的事情:重复性计算。代码清单14-1展示了如何对样本矩阵的数据进行标准化。
代码清单14-1 矩阵标准化
import numpy as np
from numpy import linalg as LA
from sklearn.preprocessing import scale
# 原始数据,包含了3个样本和3个特征,每一行表示一个样本,每一列表示一维特征
x = np.mat([[1, 3, -7], [2, 5, -14], [-3, -7, 2]])
# 矩阵按列进行标准化
x_std = scale(x, with_mean=True, with_std=True, axis=0)
print('标准化后的矩阵:\n', x_std, '\n')
其中,scale函数使用了
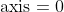
,表示对列进行标准化,因为目前的矩阵排列中,每一列代表一个特征维度,这一点需要注意。如果矩阵排列中每一行代表一个特征维度,那么可以使用

对行进行标准化。最终标准化之后的矩阵是这样的:
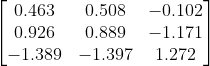
接下来是协方差的计算。对于第一维向量的方差是

。第二维和第二维向量之间的协方差是

。以此类推,我们就可以获得完整的协方差矩阵。同样,为了减少推算的工作量,使用代码清单14-2获得协方差矩阵。
代码清单14-2 获取协方差矩阵
# 计算协方差矩阵,注意这里需要先进行转置,因为这里的函数是看行与行之间的协方差
x_cov = np.cov(x_std.transpose())
# 输出协方差矩阵
print('协方差矩阵:\n', x_cov, '\n')
和sklearn中的标准化函数scale有所不同,numpy中的协方差函数cov除以的是
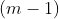
,而不是

。最终完整的协方差矩阵如下:

然后,我们要求解协方差矩阵的特征值和特征向量:

通过对行列式的求解,我们可以得到:
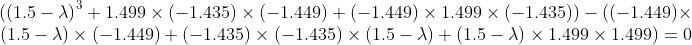
最后化简为:


所以

有3个近似解,分别是0、0.0777和4.4223。对于特征向量的求解,如果手工推算比较烦琐,我们还是利用Python语言直接求出特征值和对应的特征向量,如代码清单14-3所示。
代码清单14-3 获取协方差矩阵
# 求协方差矩阵的特征值和特征向量
eigVals, eigVects = LA.eig(x_cov)
print('协方差矩阵的特征值:', eigVals)
print('协方差矩阵的特征向量(主成分):\n', eigVects, '\n')
我们可以得到3个特征值及它们对应的特征向量,如表14-2所示。
表14-2 特征值和特征向量
|
特征值 |
特征向量(主成分) |
|
4.42231151e 00 |
|
|
−3.76638147e−16 |
|
|
7.76884923e−02 |
|



注意,Python代码输出的特征向量是列向量,而表14-2中列出的是行向量。我们继续使用下面的这段代码,找出特征值最大的特征向量,也就是最重要的主成分,然后利用这个主成分,对原始的样本矩阵进行转换,如代码清单14-4所示。
代码清单14-4 找出主成分并转换原有矩阵
# 找到最大的特征值,及其对应的特征向量
max_eigVal = -1
max_eigVal_index = -1
for i in range(0, eigVals.size):
if eigVals[i] > max_eigVal:
max_eigVal = eigVals[i]
max_eigVal_index = i
eigVect_with_max_eigVal = eigVects[:, max_eigVal_index]
# 输出最大的特征值及其对应的特征向量,也就是第一个主成分
print('最大的特征值:', max_eigVal)
print('最大特征值所对应的特征向量:', eigVect_with_max_eigVal)
# 输出转换后的数据矩阵。注意,这里的3个值表示3个样本,而特征从3维变为1维了
print('转换后的数据矩阵:', x_std.dot(eigVect_with_max_eigVal), '\n')
很明显,最大的特征值是4.422311507725755,对应的特征向量是是[−0.58077228 −0.57896098 0.57228292],转换后的样本矩阵是:

该矩阵从原来的3个特征维度降维成1个特征维度了。Python的sklearn库也实现了PCA,我们可以通过代码清单14-5来尝试一下。
代码清单14-5 找出主成分并转换原有矩阵
import numpy as np
from sklearn.preprocessing import scale
from sklearn.decomposition import PCA
# 原始数据,包含了3个样本和3个特征,每一行表示一个样本,每一列表示一维特征
x = np.mat([[1, 3, -7], [2, 5, -14], [-3, -7, 2]])
# 矩阵按列进行标准化
x_std = scale(x, with_mean=True, with_std=True, axis=0)
print('标准化后的矩阵:\n', x_std, '\n')
# 挑选前2个主成分
pca = PCA(n_components=2)
# 进行PCA分析
pca.fit(x_std)
# 输出转换后的数据矩阵。注意,这里的3个值表示3个样本,而特征从3维变为1维了
print('方差(特征值): ', pca.explained_variance_)
print('主成分(特征向量)\n', pca.components_)
print('转换后的样本矩阵:\n', pca.transform(x_std))
print('信息量: ', pca.explained_variance_ratio_)
这段代码中,我们将输出的主成分设置为2,也就是说挑出前2个最重要的主成分。相应地,转换后的样本矩阵有2个特征维度:

除了输出主成分和转换后的矩阵,sklearn的PCA还提供了信息量的数据,输出如下:
信息量: [0.98273589 0.01726411]
它是各个主成分的方差所占的比例,表示第一个主成分包含原始样本矩阵中的98.27%的信息,而第二个主成分包含原始样本矩阵中的1.73%的信息,可想而知,最后一个主成分提供的信息量很少,我们可以忽略不计了。如果我们觉得95%以上的信息量足够了,就可以只保留第一个主成分,将原始的样本矩阵的特征维数降到1维。
14.1.2 PCA背后的核心思想当然,学习的更高境界,不仅要“知其然”,还要做到“知其所以然”。即使现在你对PCA的操作步骤了如指掌,可能也还是有不少疑惑,例如,为什么我们要使用协方差矩阵?这个矩阵的特征值和特征向量又表示什么?为什么选择特征值最大的主成分,就能涵盖最多的信息量呢?不用着急,接下来会对此做出更透彻的解释,让你不仅明白如何进行PCA,同时还明白为什么要这么做。
1.为什么要使用协方差矩阵首先要回答的第一个问题是,为什么我们要使用样本数据中各个维度之间的协方差来构建一个新的协方差矩阵?要弄清楚这一点,首先要回到PCA最终的目标:降维。降维就是要去除那些表达信息量少,或者冗余的维度。我们首先来看如何定义维度的信息量大小。这里我们认为样本在某个特征维度上的差异越大,那么这个特征包含的信息量就越大,就越重要。反之,信息量就越小,需要被过滤掉。很自然,我们就能想到使用某维特征的方差来定义样本在这个特征维度上的差异。另外,我们要看如何发现冗余的信息。如果两种特征有很高的相关性,那么我们可以从一个维度的值推算出另一个维度的值,这两种特征所表达的信息就是重复的。第二篇“概率统计”介绍过多个变量间的相关性,而在实际应用中,我们可以使用皮尔森(Pearson)相关系数来描述两个变量之间的线性相关程度。这个系数的取值范围是[−1.0, 1.0],绝对值越大,说明相关性越强,正数表示正相关,负数表示负相关。图14-1展示了正相关和负相关的含义。左侧的
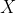
曲线和
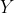
曲线有非常近似的变化趋势,当
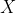
上升的时候,

往往也是上升的,

下降的时候,
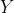
往往也下降,这表示两者有较强的正相关性。右侧的
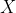
和

两者相反,当
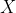
上升的时候,

往往是下降的,

下降的时候,
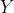
往往是上升的,这表示两者有较强的负相关性。
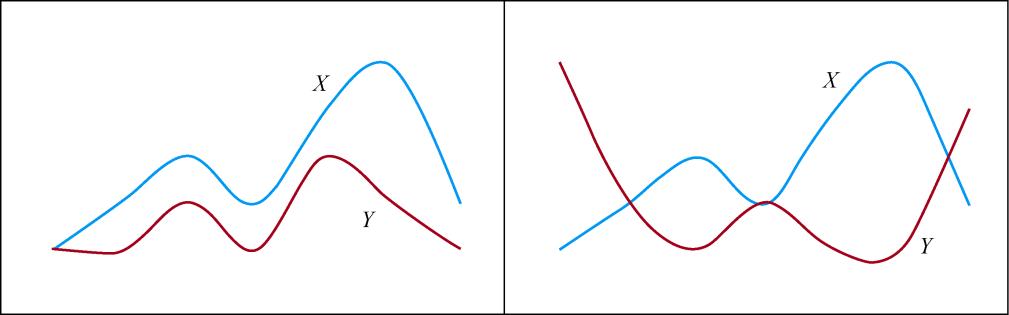
图14-1 两个变量的正负相关性
使用同样的矩阵标记,皮尔森系数的计算公式如下:

其中,
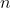
表示向量维度,

和

分别为两个特征维度

和
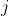
在第

个采样上的数值。

和

分别表示两个特征维度上所有样本的均值,

和
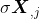
分别表示两个特征维度上所有样本的标准差。我们将皮尔森系数的公式稍加变化,来观察一下皮尔森系数和协方差之间的关系:

从上式可以看出,变化后的分子就是协方差。而分母类似于标准化数据中的分母。所以在本质上,皮尔森相关系数和数据标准化后的协方差是一致的。考虑到协方差既可以衡量信息量的大小,又可以衡量不同维度之间的相关性,因此我们就使用各个维度之间的协方差所构成的矩阵,作为PCA的对象。就如前面说讲述的,这个协方差矩阵主对角线上的元素是各维度上的方差,也就体现了信息量,而其他元素是两两维度间的协方差,也就体现了相关性。既然协方差矩阵提供了我们所需要的方差和相关性,那么下一步,我们就要考虑对这个矩阵进行怎样的操作了。
2.为什么要计算协方差矩阵的特征值和特征向量关于这一点,我们可以从两个角度来理解。
第一个角度是对角矩阵。所谓对角矩阵,就是只有矩阵主对角线之上的元素有非零值,而其他元素的值都为0。我们刚刚解释了协方差矩阵的主对角线上的元素,都是表示信息量的方差,而其他元素都是表示相关性的协方差。既然我们希望尽可能保留大信息量的维度,而去除相关的维度,那么就意味着我们希望对协方差进行对角化,尽可能地使得矩阵只有主对角线上有非零元素。假如我们确实可以将矩阵尽可能地对角化,那么对于对角化之后的矩阵,它的主对角线上的元素就是或者接近矩阵的特征值,而特征值本身又表示转换后的方差,也就是信息量。此时,对应的各个特征向量之间基本是正交的,也就是相关性极弱甚至没有相关性。
第二个角度是特征值和特征向量的几何意义。之前我们介绍过,在向量空间中,对某个向量左乘一个矩阵,实际上是对这个向量进行了一次变换。在这个变换的过程中,被左乘的向量主要发生旋转和伸缩这两种变换。如果左乘矩阵对某一个向量或某些向量只产生伸缩变换,而不对这些向量产生旋转的效果,那么这些向量就称为这个矩阵的特征向量,而伸缩的比例就是特征值。换句话说,某个矩阵的特征向量表示这个矩阵在空间中的变换方向,这些方向都是趋于正交的,而特征值表示每个方向上伸缩的比例。如果一个特征值很大,那么说明在对应的特征向量所表示的方向上,伸缩幅度很大。这也是我们需要使用原始数据去左乘这个特征向量来获取降维后的新数据的原因。因为这样做可以帮助我们找到一个方向,让它最大限度地包含原始的信息。需要注意的是,这个新的方向往往不代表原始的特征,而是多个原始特征的组合和缩放。
以来内容摘自《程序员的数学基础课:从理论到Python实践》

本书紧贴计算机领域,从程序员的需求出发,精心挑选了程序员真正用得上的数学知识,通过生动的案例来解读知识中的难点,使程序员更容易对实际问题进行数学建模,进而构建出更优化的算法和代码。
本书共分为三大模块:“基础思想”篇梳理编程中常用的数学概念和思想,既由浅入深地精讲数据结构与数学中基础、核心的数学知识,又阐明数学对编程和算法的真正意义;“概率统计”篇以概率统计中核心的贝叶斯公式为基点,向上讲解随机变量、概率分布等基础概念,向下讲解朴素贝叶斯,并分析其在生活和编程中的实际应用,使读者真正理解概率统计的本质,跨越概念和应用之间的鸿沟;“线性代数”篇从线性代数中的核心概念向量、矩阵、线性方程入手,逐步深入分析这些概念是如何与计算机融会贯通以解决实际问题的。除了理论知识的阐述,本书还通过Python语言,分享了通过大量实践积累下来的宝贵经验和编码,使读者学有所用。
本书的内容从概念到应用,再到本质,层层深入,不但注重培养读者养成良好的数学思维,而且努力使读者的编程技术实现进阶,非常适合希望从本质上提升编程质量的中级程序员阅读和学习。
,




