IT之家编辑注:作为国产芯片“代言人”,龙芯在中国半导体行业的地位不可小觑。去年4月,龙芯推出了新一代代表国产最高水平的芯片,其中之一便是龙芯 3A3000,相信关注它的用户都比较好奇,龙芯 3A3000 的实力究竟多大?现在,有IT之家的热心网友针对龙芯3A3000进行了测试,并且将测试的结果和其分析的心得和大家进行了分享,内容有些专业,感兴趣的小伙伴不妨看一下。

使用phoronix-test-suite对龙芯3A3000以及X270笔记本电脑的i5-7200U处理器性能进行了测试。
一、测试的前提:
1、 X270笔记本,i5-7200U处理器(14nm),双核4线程,关掉省电,调成性能模式。关掉自动睿频(turbo),CPU主频固定在2.5GHz。
2、龙芯3A3000主板,主频1.4GHz,4核处理器(28nm)。
3、操作系统一致,均为debian testing。注意,龙芯3A3000主板装的操作系统没有针对龙芯进行优化。内核为龙梦提供的4.14版本。
二、测试的内容和结果
测试内容为pts中压缩性能测试部分,包括7z、pbzip2、gzip和LZMA四种压缩软件。
测试结果:
主要的结果如下图所示:
点击可查看大图
对以上测试的结果,我做了一个简单的分析:
点击可查看大图
如果测试到此结束,从以上的测试,可以简单得出结论,龙芯最新的处理器处理器单核的性能仅仅相当与Intel笔记本处理器的1/5~1/2。但考虑到龙芯主频较低,龙芯处理器单核/GHz的性能相当于Intel i5-7200U处理器的40%~90%。
问题在于,使用PTS是否真的能够发挥CPU的性能?运行在龙芯上的程序,其性能还能否进一步优化?针对以上的四个测试,我分别进行了分析。
三、深入分析
1.、7z性能优化
7z benchmark跑分的结果,与线程数是相关的。在i5-7200U处理器上,分别使用1~10
个线程测试发行版所提供的7z程序性能,结果如下:
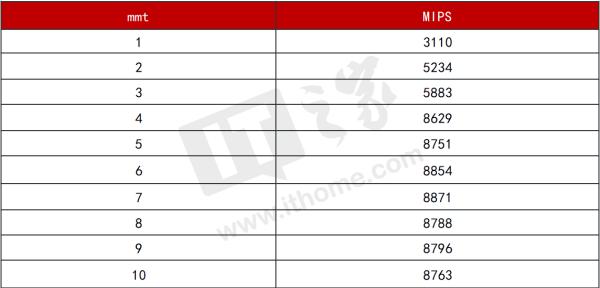
当线程数目达到7时,7z达到其峰值性能,约为8871MIPS。当线程数目为4时,峰值性能为8629,达到最高峰值性能的97%。
而对龙芯3A300来说,同样使用4个线程,是远远无法发挥其最高性能的!
类似的,使用不同的线程数目,对7z的性能进行了测试,结果如下:

在没有使用编译器优化的前提下,仅增加7z运行的线程数目,7z成绩从3478提高到了4137,性能提升达到了19%。
接着,参考龙芯官方提供的优化指南,更改了一些编译选项。Phornix-test-suite中7z编译时,默认采用的参数为:
OPTFLAGS=-O -s
更改后的编译选项为:
-march=loongson3a-mtune=loongson3a-O3-s-mabi=n32-ffast-math
-funroll-all-loops -floop-optimize
经过优化编译选项,编译的7z程序在使用不同的线程数目时性能如下所示:
经过以上的优化,龙芯3A3000运行7z的跑分可以从3478提高到4929,提升的幅度高达42%。按照4949MIPS的跑分,龙芯3A3000性能相当于i5-7200U(8871 MIPS)的56%,单核/GHZ性能的性能相当于i5-7200U的50%。
2. Pbzip2
Pbzip2程序可以分为两个部分,一部分是bzip库,一部分是使之并行话的pbzip2。
在Pbzip2运行时,同样需要指定运行的线程数目。首先,使用不同的线程,对压缩的效果
进行了测试。测试内容是对大小为612MB的linux-4.3.tar的Linux内核源码包进行压缩。
压缩所使用的命令为:
#!/bin/sh
cd pbzip2-1.1.12/
./pbzip2 -c -p$NUM_CPU_CORES -r -5 ../linux-4.3.tar > /dev/null 2>&1
测试压缩所使用的时间。
随后,对二进制文件的编译进行了优化。增加了编译的优化选项。
-march=loongson3a -O3 -s-mabi=n32 -ffast-math
优化后,压缩文件耗时由51.2秒减少到43.2秒,速度提高了18.6%。
3. Lzma
Lzma测试内容为使用lzma源码,编译出lzma可执行文件,然后用它对一个大小为
563MB的linux-4.0.1.tar的文件进行压缩,统计压缩消耗的时间。测试命令为
./lzma_/bin/lzma -q -c linux-4.0.1.tar > /dev/null 2>&1
需要注意的是,LZMA测试本身是单线程的,反映的是处理器的单核性能。
首先,我对lzma的编译进行了优化。
./configure? CXXFLAGS="-march=loongson3a-O3-s-mabi=n32? -ffast-math
-funroll-all-loops? -floop-optimize"CFLAGS="-march=loongson3a? -O3? -s-mabi=n32
-ffast-math -funroll-all-loops -floop-optimize"
测试表明,压缩时间从1106秒减少到981.6 s,速度提升了13%。
4. Gzip
经过分析pts/compress-gzip的测试流程,我发现在测试中直接调用了操作系统提供的tar程序来实现压缩和解压缩,并没有下载gzip源码进行编译的过程。因此,测试反映的是操作系统自带tar程序在本地CPU上的性能。
经过优化以后,龙芯CPU和Intel CPU的性能对比如下:
从优化测试的结果看来,4核龙芯3A3000处理器综合性能相当于双核四线程Intel i5-7200U处理器的60%,单核性能相当于i5-7200U处理器的1/3~1/2。如果龙芯3A4000处理器的综合性能能够达到3A3000的2倍左右,差不多就可以赶上i5-7200U这款低电压的笔记本处理器了。
四、总结
以上的测试也表明,对龙芯处理器来说,针对特定程序的性能优化是非常关键的,能够让应用软件的性能有很大的提升。在龙芯处理器性能还没有追平国外先进处理器的阶段尤其需要深度的优化,需要“app by app,feature by feature.pixel by pixel”地去进行优化。为此,也希望龙芯方面能够在编译器和工具链的优化上多做工作,使软件开发者能够更好地优化自己的程序。
,







