
你可以利用CUDA和GPU的并行处理能力来加速深度学习和其他计算密集型应用程序。
CUDA是由Nvidia开发的并行计算平台和编程模型,用于在其自己的GPU(图形处理单元)上进行通用计算。CUDA使开发人员能够利用GPU的强大功能来加速计算密集型应用程序的可并行化部分。
虽然有其他GPU的API,如OpenCL,也有来自其他公司的竞争GPU,如AMD,但CUDA和Nvidia GPU的结合主导了几个应用领域,包括深度学习,并且是一些世界上最快的计算机的基础。
显卡可以说和PC一样古老——如果你把1981年的IBM单色显示适配器看作显卡的话。到1988年,你可以从ATI(该公司最终被AMD收购)那里得到一张16位2D VGA Wonder卡片。到1996年,你可以从3dfx Interactive购买一个3D图形加速器,这样你就可以全速运行第一人称射击游戏Quake。
同样是在1996年,英伟达开始试图在3D加速器市场上与低端产品竞争,但随着时间的推移,它学会了如何去做,并在1999年推出了成功的GeForce 256,第一张被称为GPU的显卡。当时,拥有GPU的主要原因是游戏。直到后来,人们才将GPU用于数学、科学和工程。
CUDA的起源
2003年,由伊恩•巴克(Ian Buck)领导的一个研究小组公布了Brook模型,这是第一个被广泛采用的用数据并行结构扩展C的编程模型。Buck后来加入英伟达,并于2006年领导CUDA的推出,这是首个针对GPU的通用计算的商业解决方案。
OpenCL与CUDA
CUDA竞争对手OpenCL于2009年由Apple和Khronos Group推出,旨在为异构计算提供标准,不仅限于采用Nvidia GPU的Intel / AMD CPU。虽然OpenCL因其通用性而听起来很有吸引力,但它在Nvidia GPU上的表现并不如CUDA,并且许多深度学习框架要么不支持它,要么只在它们的CUDA支持发布后作为事后补充支持它。
CUDA性能提升
多年来,CUDA已经改进并扩大了其范围,或多或少与改进的Nvidia GPU保持同步。从CUDA 9.2版开始,使用多个P100服务器GPU,可以实现比CPU高50倍的性能提升。对于某些负载,V100(此图中未显示)的速度提高了3倍。 上一代服务器GPU K80比CPU提供了5到12倍的性能提升。
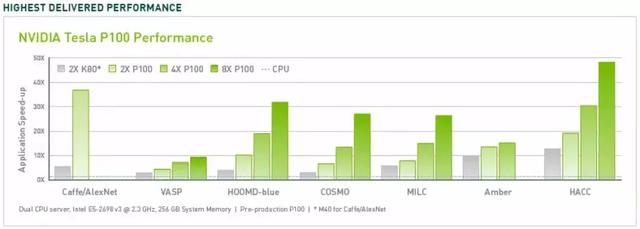
GPU的速度提升已经到了高性能计算的时间。由于芯片制造商遇到物理限制,包括芯片掩模分辨率的大小限制和制造过程中的芯片产量,因此随着时间的推移,CPU的单线程性能提升(摩尔定律建议每18个月翻一番)已经放缓至每年10% 运行时的时钟频率和热限制。

CUDA应用领域

CUDA和Nvidia GPU已被许多需要高浮点计算性能的领域采用,如上图所示。 更全面的清单包括:
- 计算金融
- 气候,天气和海洋模拟
- 数据科学和分析
- 深度学习和机器学习
- 国防和情报
- 制造/ AEC(建筑,工程和施工):CAD和CAE(包括计算流体动力学,计算结构力学,设计和可视化以及电子设计自动化)
- 媒体和娱乐(包括动画,建模和渲染;色彩校正和谷物管理;合成;整理和效果;编辑;编码和数字发行;播出图形;现场,评论和立体工具;以及天气图形)
- 医学影像
- 油和气
- 研究:高等教育和超级计算(包括计算化学和生物学,数值分析,物理学和科学可视化)
- 安全保障
- 工具和管理
CUDA深度学习
深度学习对计算速度的需求非常大。例如,为了在2016年训练谷歌翻译模型,谷歌大脑和谷歌翻译团队使用GPU进行了数百次为期一周的TensorFlow运行;他们为此目的从Nvidia购买了2,000台服务器级GPU。如果没有GPU,这些训练将花费数月而不是一周的时间来收敛。对于那些TensorFlow翻译模型的生产部署,Google使用了新的自定义处理芯片TPU(张量处理单元)。
除了TensorFlow之外,许多其他DL框架依赖CUDA来支持GPU,包括Caffe2,CNTK,Databricks,H2O.ai,Keras,MXNet,PyTorch,Theano和Torch。在大多数情况下,他们使用cuDNN库进行深度神经网络计算。该库对于深度学习框架的培训非常重要,使用给定版本的cuDNN的所有框架对于等效用例具有基本相同的性能数字。当CUDA和cuDNN从版本改进到版本时,更新到新版本的所有深度学习框架都会看到性能提升。从框架到框架的性能往往不同的地方在于它们扩展到多个GPU和多个节点的程度。
CUDA编程

CUDA工具包
CUDA工具包包括库,调试和优化工具,编译器,文档和用于部署应用程序的运行时库。 它具有支持深度学习,线性代数,信号处理和并行算法的组件。一般而言,CUDA库支持所有Nvidia GPU系列,但在最新一代产品上表现最佳,例如V100,它比深度学习培训工作负载的P100快3倍。使用一个或多个库是利用GPU的最简单方法,只要需要的算法已在相应的库中实现。
CUDA深度学习库
在深度学习领域,有三个主要的GPU加速库:cuDNN,我之前提到它是大多数开源深度学习框架的GPU组件; TensorRT,这是Nvidia的高性能深度学习推理优化器和运行时; 和DeepStream,一个视频推理库。 TensorRT可帮助优化神经网络模型,以高精度校准低精度,并将经过培训的模型部署到云,数据中心,嵌入式系统或汽车产品平台。

CUDA线性代数和数学库
线性代数支持张量计算,因此深度学习。BLAS(基本线性代数子程序)是1989年在Fortran中实现的矩阵算法的集合,自此以后一直被科学家和工程师使用。cuBLAS是BLAS的GPU加速版本,也是使用GPU进行矩阵运算的最高性能方式。cuBLAS处理矩阵密集; cuSPARSE处理稀疏矩阵。

CUDA信号处理库
快速傅里叶变换(FFT)是用于信号处理的基本算法之一;它将信号(例如音频波形)转换为频谱。cuFFT是GPU加速的FFT。
编解码器使用H.264等标准编码/压缩和解码/解压缩视频以进行传输和显示。Nvidia Video Codec SDK使用GPU加速了这一过程。

CUDA并行算法库
并行算法的三个库都有不同的用途。NCCL(Nvidia Collective Communications Library)用于跨多个GPU和节点扩展应用程序;nvGRAPH用于并行图分析; 和Thrust是基于C 标准模板库的CUDA的C 模板库。Thrust提供了丰富的数据并行原语集合,如扫描,排序和缩减。

CUDA与CPU性能
在某些情况下,可以使用drop-in CUDA函数而不是等效的CPU函数。例如,BLAS的GEMM矩阵乘法例程可以简单地通过链接到NVBLAS库来替换为GPU版本:

CUDA编程基础知识
如果无法找到CUDA库例程来加速程序,那么将不得不尝试低级CUDA编程。现在这比在21世纪末第一次尝试它时要容易得多。除了其他原因之外,还有更简单的语法,并且有更好的开发工具可用。 唯一不足的是,在MacOS上,最新的CUDA编译器和最新的C 编译器(来自Xcode)很少同步。必须从Apple下载较旧的命令行工具并使用xcode-select切换到它们以获取CUDA代码进行编译和链接。
例如,考虑这个简单的C/C 例程来添加两个数组:
void add(int n, float *x, float *y) { for (int i = 0; i < n; i ) y[i] = x[i] y[i]; }
可以通过在声明中添加__global__关键字将其转换为将在GPU上运行的内核,并使用三括号语法调用内核:
add<<<1, 1>>>(N, x, y);
还必须将malloc/new和free/delete调用更改为cudaMallocManaged和cudaFree,以便在GPU上分配空间。最后,在使用CPU上的结果之前,需要等待GPU计算完成,可以使用cudaDeviceSynchronize来完成。
上面的三重括号使用一个线程块和一个线程。当前的Nvidia GPU可以处理许多块和线程。 例如,基于Pascal GPU架构的Tesla P100 GPU具有56个流式多处理器(SM),每个处理器能够支持多达2048个活动线程。
内核代码需要知道它的块和线程索引,以便在传递的数组中找到它的偏移量。并行化内核通常使用网格跨步循环,如下所示:
__global__ void add(int n, float *x, float *y) { int index = blockIdx.x * blockDim.x threadIdx.x; int stride = blockDim.x * gridDim.x; for (int i = index; i < n; i = stride) y[i] = x[i] y[i]; }
如果查看CUDA工具包中的示例,会发现除了上面介绍的基础知识外,还有更多需要考虑的问题。例如,某些CUDA函数调用需要包含在checkCudaErrors()调用中。此外,在许多情况下,最快的代码将使用诸如cuBLAS之类的库以及主机和设备存储器的分配以及来回复制矩阵。
总之,可以在多个级别使用GPU加速应用程序。可以写CUDA代码;可以调用CUDA库; 并且可以使用已经支持CUDA的应用程序。
原文链接:
https://www.infoworld.com/article/3299703/deep-learning/what-is-cuda-parallel-programming-for-gpus.html
,




