
作者:余敦刚(玄苏)
命名是对事物本质的一种认知探索,是给读者一份宝贵的承诺。糟糕的命名会像迷雾,引领读者走进深渊;而好的命名会像灯塔,照亮读者前进的路。命名如此美妙,本文将一步步揭开它的神秘面纱!
命名来源生活

从左到右:正三角形,正方形、正六边形 正表示边长相等,从而得到正XXX的边长一定是相等的。
这些事物的特征比较明显,容易被人们所记忆。但是也有一些比较难以命名,比如化学有机物:

相比于化学有机物,软件世界的事物更加繁多,命名将更加的困难。
Phil Karlton (菲儿·卡尔顿)曾说过:在计算机科学中只有两件困难的事情:缓存失效和命名规范。
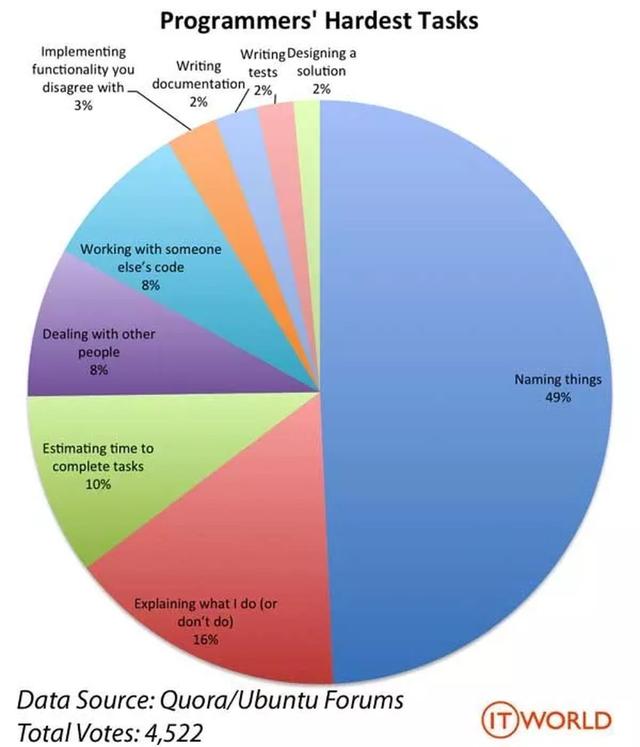
命名一直是软件领域的难题,好的命名能够信达雅:
译事三难:信、达、雅。
—— 严复
信:含义准确达:通顺流畅雅:简明优雅
命名的坏味道查看下面代码,说出其含义:
public List<int[]> getThen(){
List<int[]> list1 = new ArrayList<int[]>();
for (int[] x: theList)
if (x[0] == 4)
list1.add(x);
return list1;
}
问题不在于代码的简洁度,而是在于代码的模糊度:即上下文在代码中未被明确体现的程度。
- theList 中是什么类型的东西?
- theList 零下表条目的意义是什么?
- 值4的意义是什么?
- 我如何使用返回的列表
问题的答案没体现在代码段中,可那就是它们该在的地方。
再看看重命名后的代码:
public List<int[]> getFlaggedCells(){
List<int[]> flaggedCells = new ArrayList<int[]>();
for (int[] cell: gameBoard)
if (cell[STATUS_VALUE] == FLAGGED)
flaggedCells.add(cell);
return flaggedCells;
}
注意,代码的简洁性并未触及。运算符和常量的数量全然保持不变,嵌套数量也全然保持不变。但代码变得明确多了。
站在使用者的角度,还可以更近一步吗?
虽然getFlaggedCells一名表明方法会返回FlaggedCells,但是返回的数据结构并未表达出来:
public List<Cell> getFlaggedCells(){
List<Cell> flaggedCells = new ArrayList<Cell>();
for (Cell cell: gameBoard)
if (cell.isFlagged())
flaggedCells.add(cell);
return flaggedCells;
}
能否看出代码的两处差异点?
稍微仔细点观察,就会发现有两个点被改进:
- int[] -> Cell : 将数据进行建模,赋予其含义
- cell[STATUS_VALUE] == FLAGGED ==> cell.isFlagged()
- 建模后可以竟然可以将这条语句语义化,可读性增强了;
- STATUS_VALUE、FLAGGED 都被隐藏至Cell,更加了内聚;
只要简单改了以下名称,就能轻易知道发生了什么,这就是命名的力量。
命名的游戏首先来做一个游戏,游戏名为 “我们住在哪个房间?”,如下会为你提供一张图片,请你说说看这是什么房间。

从上面的图片不难看出,这肯定是客厅。基于一件物品,我们可以联想到一个房间的名称,这很简单,那么请看下图。

基于这张图片,我们可以肯定的说,这是厕所。通过上面两张图片,不难发现,房间的名称只是一个标签属性,有了这个标签,甚至我们不需要看它里面有什么东西。这样我们便可以建立第一个推论:
推论1:容器(函数)的名称应包含其内部所有元素
如果有一张床?那么它就是卧室。我们也可以反过来进行分析。
问题:基于一个容器名称,我们可以推断出它的组成部分。如果我们以卧室为例,那么很有可能这个房间有一张床。这样我们便可以建立第二个推论:
推论2:根据容器(函数)的名称推断其内部组成元素
现在我们有了两条推论,据此我们试着看下面这张图片。
问题 3/3

好吧,床和马桶在同一个房间?根据我们的推论,如上图片使我们很难立即做出判断,如果依然使用上述两条推论来给它下定义的话,那么我会称它为:怪物的房间。
这个问题并不在于同一个房间的物品数量上,而是完全不相关的物品被认作为具备同样的标签属性。在家中,我们通常会把有关联的,意图以及功能相近的东西放在一起,以免混淆视听,所以现在我们有了第三条推论:
推论3:容器(函数)的明确度与其内部组件的密切程度成正比
这可能比较难理解,所以我们用下面这一张图来做说明:

如果容器内部元素属性关联性很强,那么更容易找到一个用来说明它的名字;反之,元素之间的无关性越强,越难以描述说明。
属性维度可能会关系到他们的功能、目的、战略,类型等等。关于命名标准,需要关联到元素自身属性才有实际意义。
在软件工程方面,这个观点也同样适用。例如我们熟知的组件、类、函数方法、服务、应用。罗伯特·德拉奈曾说过:“我们的理解能力很大程度与我们的认知相关联”,那么在这种技术背景下,我们的代码是否可以使阅读者以最简单的方式感知到业务需求以及相关诉求?
命名的原则名副其实
命名应该描述其所做的所有事情(或者它的意图)。
当读者读到上文命名的坏味道里面讲的例子中getThen(),并不能理解 getThen()的意图是什么?是获取什么呢?getFlaggedCells()就能比较准确地表达出来。
// 槽糕的命名
public List<int[]> getThen();
// 好的命名
public List<Cell> getFlaggedCells();
// 槽糕的命名
private Date userCacheTime;
// 好的命名
private Date customerStayTotalTime;
避免误导
避免留下掩藏代码本意的错误线索。
- 别用accountList来指称一组账号,除非它真的时List类型。
List一词对于程序员来说有特殊含义。如果包纳账号的容器并非真实一个List, 就会引起错误的判断。所有建议用accountGroup 或 bunchOfAccounts, 甚至是 accounts都会好一些。
- 避免变量名使用小写字母l和大写字母O。
这样的拼写方式容易误导读者或者让读者花较大的力气去辨别。
有意义的区分
如果同一作用范围内有多个命名,最好让它们之间有区分度。
public static void copyChars(char a1[], char a2[]){
for (int i = 0; i < a1.length; i ){
a2[i] = a1[i];
}
}
这里参数a1,a2是依义进行命名的,完全没有提供正确的信息,没有提供导向作者意图的线索。
如何进行有意义的区分呢?
如果参数改为source 和 destination,这个函数的命名就更符合其用途。
public static void copyChars(char source[], char destination[]){
for (int i = 0; i < source.length; i ){
destination[i] = source[i];
}
}
- 准确使用对仗词可以提高命名的区分度。
命名时遵守对仗词的命名规则有助于保持一致性,从而也可以提高可读性。像first/last这样的对仗词就很容易理解;而像FileOpen() 和 _lclose() 这样的组合则不对称,容易使人迷惑。下面列出一些常见的对仗词组:
|
add/remove |
increment/decrement |
open/close |
|
begin/end |
insert/delete |
show/hide |
|
create/destory |
lock/unlock |
source/target |
|
first/last |
min/max |
start/stop |
|
get/put |
next/previous |
up/down |
|
get/set |
old/new |
- 尽量不要使用info/data为结尾去命名类名或变量名。
info和data的含义过于宽泛,导致没有额外的信息量,反而增加了读者的阅读成本,得不偿失。
风格一致
让同一个项目中的代码命名规则保持统一。
比如:
- 每个class的Logger取名为logger、log还是LOGGER,取哪个名字均可,但是需要保持项目统一;
- 类属性的getter/setter方法的命名统一。getName()还是name()均可,但是需要保持项目统一;
- 注释的风格统一。
/**
* 用户的姓名
*/
public Sring userName;
/** 用户的姓名 **/
抽象一致
让同一作用域内的变量或方法具有相同的抽象。
public class Employee {
...
public String getName(){...}
public String getAddress(){...}
public String getWorkPhone(){...}
public boolean isJobClassificaitionValid(JobClassification jobClass){...}
public boolean isZipCodeValid(Address address){...}
public boolean isPhoneNumberValid(PhoneNumber phoneNumber){...}
public SqlQuery getQueryToCreateNewEmployee(){...}
public SqlQuery getQueryToModifyEmployee(){...}
public SqlQuery getQueryToRetrieveEmployee(){...}
...
}
查看这个类,看看它有几个抽象层次?
通过函数名可以查看:
- getName、getAddress、getWorkPhone 都是获取 Employee 的主要属性,符合Employee的抽象;
- isJobClassificaitionValid 是 校验JobClassification 对象是否有效,属于JobClassification的抽象层次,与Employee 无关;
- isZipCodeValid是校验Address的合理性,属于Address的抽象层次,而Address是Employee 的属性,不是一个抽象层次。isPhoneNumberValid 同理;
- getQueryToCreateNewEmployee/getQueryToModifyEmployee/getQueryToRetrieveEmployee 看似与Employee 有关,但是这里暴露SQL语句查询细节,是实现细节,层次比Employee要低。
多个不同层次的方法会让这个类看起来非常怪,就像将晶体管、芯片零件、手机放在一个台面上一样。
public class Employee {
...
public String getName(){...}
public String getAddress(){...}
public String getWorkPhone(){...}
public String createEmployee(...){...}
public String updateEmployee(...){...}
public String deleteEmployee(...){...}
...
}
命名建模
如果在一个项目中,发现有一段组装搜索条件的代码,在几十个地方都有重复。这个搜索条件还比较复杂,是以元数据的形式存在数据库中,因此组装的过程是这样的:
- 首先,我们要从缓存中把搜索条件列表取出来;
- 然后,遍历这些条件,将搜索的值填充进去。
//取默认搜索条件
List<String> defaultConditions = searchConditionCacheTunnel.getJsonQueryByLabelKey(labelKey);
for (String jsonQuery : defaultConditions) {
jsonQuery = jsonQuery.replaceAll(SearchConstants.SEARCH_DEFAULT_PUBLICSEA_ENABLE_TIME,
String.valueOf(System.currentTimeMillis() / 1000));
jsonQueryList.add(jsonQuery);
}
//取主搜索框的搜索条件
if (StringUtils.isNotEmpty(cmd.getContent())) {
List<String> jsonValues = searchConditionCacheTunnel.getjsonQueryByLabelKey(
SearchConstants.ICBU_SALES_MAIN_SEARCH);
for (String value : jsonValues) {
String content = StringUtil.transferQuotation(cmd.getContent());
value = StringUtil.replaceAll(value, SearchConstants.SEARCH_DEFAULT_MAIN, content);
jsonQueryList.add(value);
}
}
简单的重构无外乎就是把这段代码提取出来,放到一个Util类里面给大家复用。然而我认为这样的重构只是完成了工作的一半,我们只是做了简单的归类,并没有做抽象提炼。
简单分析,不难发现,此处我们是缺失了两个概念:一个是用来表达搜索条件的类——SearchCondition;另一个是用来组装搜索条件的类——SearchConditionAssembler。只有配合命名,显性化的将这两个概念表达出来,才是一个完整的重构。
重构后,搜索条件的组装会变成一种非常简洁的形式,几十处的复用只需要引用SearchConditionAssembler就好了。
public class SearchConditionAssembler {
public static SearchCondition assemble(String labelKey) {
String jsonSearchCondition = getJsonSearchConditionFromCache(labelKey);
SearchCondition sc = assembleSearchCondition(jsonSearchCondition);
return sc;
}
}
由此可见,提取重复代码只是我们重构工作的第一步。对重复代码进行概念抽象,寻找有意义的命名才是我们工作的重点。
因此,每一次遇到重复代码的时候,你都应该感到兴奋,想着,这是一次锻炼抽象能力的绝佳机会,当然,测试代码除外。

语境通用化
- 别抖机灵
如果你使用的命名来自一个比较冷门的语境,比如俗语或者俚语,不知道这个语境的人将很难理解它的含义。
如:用whack来标识kill,wsBank来标识网商银行
- 使用问题领域的名称
如果不能用程序员熟悉的术语命名,就采用从所涉及问题领域而来的名称,至少维护代码的程序员就能去请教领域专家了。这样至少问题域的专家能清晰理解开发者命名的语境,读者可以询问领域专家或者查询领域词汇含义。
以消息中间件领域为例:topic、、message、tag、offset、commitLog
|
名词 |
含义 |
|
topic |
消息的类型 |
|
broker |
消息处理代理者 |
|
message |
消息主题 |
|
tag |
Topic下的次级消息类型 |
|
offset |
消费者的消费进度 |
|
commitLog |
消息的存储文件 |
如果子程序名称、类名、变量 含糊不清或者名不副实时,就需要对这个变量进行改名或者重构。
改变函数声明

好的命名让读者一看看出函数的用途,而不必查询实现代码。
1 动机
函数名:
改进函数声明的小技巧:先写一句注释描述这个函数的用途,再把这句注释变成函数的名字。
函数的参数:
函数的参数列表阐述了函数如何与外部世界共处,是函数和函数使用者共同的依赖,这其实也是一种耦合
- 最小使用原则:函数的参数列表正是函数所依赖的,不会依赖没有用到的信息:
- 例如:一个函数的用途是把某人的电话号码转换成特定的格式,并且这个函数的参数是一个人,那么我就没法用这个函数来处理公司的电话号码。如果把函数接收的参数由“人”改成“电话号码”,这段处理电话格式的代码就能被更广泛地使用;
- 根据函数的意图引入函数参数:
- 如果这个函数的意图只是将电话号码转换成特定的格式,那么只引入电话号码是合适的;
- 如果这个函数的意图是得到“人”的电话号码格式并且他的号码是通过自身的其他属性合成, 那么应该引入“人”。
关于如何选择正确的参数,没有简单的规则可循,需要视具体情况而定。
2 做法
常用的重构做法有两种:简单式做法 和迁移式做法
简单式做法:适用于一步到位地修改函数声明及其所有调用者。
- 如果想要移除一个参数,需要先确定函数体内没有使用该参数;
- 修改函数声明,使其成为你期望的状态;
- 找出所有使用旧函数声明的地方,将它们改为使用新的函数声明;
- 测试。
最好能把大的修改拆成小的步骤,所以如果你既想要修改函数名,又想添加参数,最好分成两部来做。比较幸运的是,简单式做法一般可以用IDE工具直接重构完成。
实战:下列函数的名字太过简略
public long circum(long radius){
return 2 * Math.PI * radius;
}
将这个命名改得更加有意义一些:
public long circumference(long radius){
return 2 * Math.PI * radius;
}
迁移式做法:函数被很多地方调用、修改不容易或者要修改的是一个多态函数或者对函数声明的修改比较复杂。
- 如果有必要的话,先对函数体内部加以重构,使后面的提炼步骤易于开展;
- 使用提炼函数(106)将函数体提炼成一个新函数;
- Tip如果你打算沿用旧函数的名字,可以先给新函数起一个易于搜索的临时名字;
- 如果提炼出的函数需要新增参数,用前面的简单做法添加即可;
- 测试;
- 对旧函数使用内联函数(115);
- 如果新函数使用了临时的名字,再次使用改变函数声明(124)将其改回原来的名字;
- 测试。
实战:还是刚才circum方法改名的例子
这个简略的函数名先不做修改。
public long circum(long radius){
return 2 * Math.PI * radius;
}
再新增circumference函数:
public long circumference(long radius){
return 2 * Math.PI * radius;
}
逐渐小步地将circum 方法的调用处改成circumference方法,每次修改都运行一下测试;如果测试成功,则提交此次修改进行一下修改,否则返回至上一步重新进行修改。这样及时中间出错,也能准确定位至某此修改,稳定推进重构,间接提高了重构的效率。
变量改名

1 动机
好的变量命名可以额解释一段程序来干什么——如果变量名起得好的话。
2 机制
- 如果变量被广泛使用,考虑运用封装变量将其封装起来;
- 找出所有使用该变量的代码,逐一修改;
a、如果在另一个代码库中使用了该变量,这就是一个“已发布变量”(published variable),此时不能进行这个重构;
b、如果变量值从不修改,可以将其复制到一个新名字之下,然后逐一修改使用代码,每次修改后执行测试;
3、测试。
3 范例
如果要改名的变量只作用于一个函数,对其改名是最简单的,直接使用IDE进行重命名即可。
如果变量的作用于不至于单个函数,重命名的风险就不太好把控,这时需要对变量进行封装。
变量初始化
int treeName = "untitled";
变量被修改
treeName = "bigtree";
变更被读取
leftTree = treeName;
此时可以考虑采用封装变量进行完成
private int treeName;
public void init(){
treeName = "untitled";
}
public String getTreeName(){
return treeName;
}
public void setTreeName(String treeName){
this.treeName = treeName;
}
命名是一个迭代的过程。当你持续很长时间想不到比较好的命名时,不要掉入取名的陷阱,可以先用折中的命名commit掉或者重构这段程序。当你想到更合适的命名,毫不犹豫地去重构它。
命名是一个接近描述事物本质的过程。命名得越好,越容易接近描述事物的本质。
取好名字最难的地方在于需要良好的描述技巧和共有文化背景。
结语好的命名是自解释的,读者不用了解程序实现的细节,就能知道程序实现的意图(契约式编程)。在项目实战中,有时候很难给一段子程序取到一个比较好的名字,这其实是程序在说话--让我干的事情太杂了,导致不知道我是用来干啥的。一般这种情况下,需要重构这段子程序,对齐进行职责拆分,分而治之。命名是门艺术,美在它的简单,美在它的明确,美在它的名副其实。
参考文档
- TwoHardThings:https://martinfowler.com/bliki/TwoHardThings.html
- Software Complexity: The Art of Naming:https://medium.com/hackernoon/software-complexity-naming-6e02e7e6c8cb
- 《代码大全》
- 《代码整洁之道》
关注【阿里巴巴移动技术】微信公众号,每周 3 篇移动技术实践&干货给你思考!
,




