数据与智能 本公众号关注大数据与人工智能技术。由一批具备多年实战经验的技术极客参与运营管理,持续输出大数据、数据分析、推荐系统、机器学习、人工智能等方向的原创文章,每周至少输出7篇精品原创。同时,我们会关注和分享大数据与人工智能行业动态。欢迎关注。
来源 | Data Science from Scratch, Second Edition
作者 | Joel Grus
译者 | cloverErna
校对 | gongyouliu
编辑 | auroral-L
全文共4975字,预计阅读时间30分钟。
第五章 统计学基础介绍
5.1 描述单个数据集
5.1.1 中心倾向
5.1.2 离散度
5.2 相关性
5.3 辛普森悖论
5.4 相关系数其他注意事项
5.5 相关和因果
5.6 延伸学习
事实如磐石,统计似蒲草。
——马克• 吐温
统计学(Statistics )是我们赖以理解数据的数学与技术。这是一个庞大繁荣的领域,要用图书馆的一整个书架(甚至一整间屋子)的书来阐述,绝非一本书的一个章节所能尽述,所以本书的探讨必然不会太深入。我在此抛砖引玉,讲述一些刚好能激发你的兴趣的内容,供你自行深入学习与开拓。
5.1 描述单个数据集
凭借口碑与运气,DataSciencester 已经发展了数十名成员。这时,融资部门的副总来问你要一些关于你的成员有多少朋友的数据,以此来确定他潜在的电梯演说对象。
运用第 1 章《数据科学基本介绍》中学到的技术,可以很容易地生成这个数据。但你现面临的问题是如何描述(describe)它。
对任何数据集,最简单的描述方法就是数据本身:

对足够小的数据集来说,这甚至可以说是最好的描述方法。但随着数据规模变大,这就显得笨拙又含混了。(想象一个包含一亿个数字的列表。)为此,我们使用统计来提炼和表达数据的相关特征。
首先,我们通过 Couner 和 plt.bar() 把你的朋友数绘成直方图(图 5-1):


图 5-1:朋友数的直方图
不幸的是,这幅图难以用来进行交流,所以你需要再提炼一些统计量。数据点个数大概就是最简单的统计量了:

也许你会对数据集的最大值和最小值感兴趣:

如果你想知道特定位置的值,可以这样做:

但我们才刚刚开始。
5.1.1 中心倾向
我们常常希望了解数据中心位置的一些概念。一个常用的方法是使用均值mean (或average),即用数据和除以数据个数:

如果你有两个数据点,均值就意味着两点的中间点。随着数据集中点数的增加,均值点会移动,但它始终取决于每个点的取值。例如,如果您有10个数据点,并且将其中任何一个数据点的值增加1,则将平均值增加0.1。
我们常常也会用到中位数(median),它是指数据中间点的值(如果数据点的个数是奇数),或者中间两个点的平均值(如果数据点的个数是偶数)。
例如,如果在排序向量 x 上有五个数据点,那么中位数就是 x[5 // 2] 或 x[2]。如果有六个数据点,则中位数是 x[2](第三个点)与 x[3](第四个点)的平均数。
注意——和均值不同——中位数并不依赖于每一个数据的值。例如,即便数据集中最大的点变得更大(或最小的点变得更小),中间的数据点都不会变,意味着中位数也不会变。
我们将为偶数和奇数情况编写不同的函数,并将它们组合起来:

现在我们可以计算朋友的中位数:

很明显,均值的计算更简单,并且它会随着数据变化而平稳地变化。如果有 n 个数据点,其中某一个点的值增加了 e,则均值随之增加 e/n。(这使得均值适用于各种微分运算)但是为了计算中位数,得先对数据排序。并且,如果其中一个数据点的值增加了 e,那么中位数有可能也增加 e,有可能增加一个小于 e 的数,也有可能根本不变(这取决于其他的数据)。
注意
事实上,不排序也可以使用一些生僻的技巧有效地算出中位数。但这些技巧不但不易理解,而且超出了本书的讲解范围。所以我们先排序再计算。
同时,均值对数据中的异常值非常敏感。如果最具人缘的用户有 200 个朋友(不是 100),均值会上升至 7.82,而中位数不变。如果异常值属于不良数据(或者对我们试图理解的现象不具有代表性),那么均值会误导我们。举一个老生常谈的例子,20 世纪 80 年代,北卡罗来纳大学起薪最高的专业是地理学,因为球星迈克尔·乔丹曾就读于此,均值计算就包含了这个“异常值”。
比中位数更广泛的一个概念是分位数(quantile),它表示数据中有多少比例的数据小于某个值。(中位数表示少于它的数有50%。):

还有一个不太常用的概念众数(mode),它是指出现次数最多的一个或多个数,但最常见的情况是我们只使用平均值。
5.1.2 离散度
离散度(Dispersion )是数据的离散程度的一种度量。通常,如果它所统计的值接近零,则表示数据聚集在一起,离散程度很小,如果值很大(无论那意味着什么),则表示数据的离散度很大。例如,一个简单的度量是极差(range),指最大元素与最小元素的差:

极差恰好为零,意味着数据集中最大值和最小值相等,这种情形只有在x中的元素全部相同时才会发生,意味着数据没有离散。相反,如果极差很大,说明最大元素比最小元素大很多,数据离散度很高。
和中位数一样,极差也不真正依赖于整个数据集。一个只包含 0 和 100 的数据集,和一个包含 0、100 以及很多个 50 的数据集,两者的极差相同。但看起来第一个数据集的离散度“应该”更高。
离散度的另一个更复杂的度量是方差(variance),计算方式如下:

注意
这个概念看起来似乎是各个数值分别与其均值之差的平方的均值,但我们除以的是 n-1 而不是 n。事实上,如果样本取自更大的总体,x_bar 就是真实均值的估值,意味着 (x_i - x_bar) ** 2 是 x_i 与平均值的平方偏差的估计,所以我们除以 n-1 而不是 n。更多信息请查看维基百科。
现在,无论我们的数据是什么单位(比如,“朋友”),所有中心倾向的度量都是同一单位。极差的单位也与此相同。但是,方差的单位是原数据单位的平方(即“朋友的平方”)。然而,用方差很难给出直观的比较,所以我们更常使用标准差(standard deviation):

极差和标准差也都有我们之前提到的均值计算常遇到的异常值问题。再看之前的例子,如果我们最具人缘的用户有 200 个朋友,标准差就变为 14.89,增加了 60% !一种更加稳健的方案是计算 75% 的分位数和 25% 的分位数之差:

相对来说,这种计算不易受到一小部分异常值的影响。
5.2 相关性
DataSciencester 战略发展部的副总持有这样一种想法,即用户在某个网站上花费的时间与其在这个网站上拥有的朋友数相关(她并不是一个无所事事的领导)。现在,她要求你来验证这个想法。
通过分析研究流量日志,你设法做出了一个 daily_minutes 列表,这个列表描述了每个用户每天在 DataSciencester 花费了多长时间。你还对这个列表排了序,使它的元素和你之前的列表 num_friends 的元素对应了起来,以便进一步研究两个度量之间的关系。我们先来看一下协方差(covariance),这个概念是方差的一个对应词。方差衡量了单个变量对均值的偏离程度,而协方差衡量了两个变量对均值的一致偏离程度:

回想一下点乘(dot)的概念,它意味着对应的元素对相乘后再求和。如果向量 x 和向量 y的对应元素同时大于它们自身序列的均值,或者同时小于它们自身序列的均值,那将为求和贡献一个正值。如果其中一个元素大于自身的均值,而另一个小于自身的均值,那将为求和贡献一个负值。因此,如果协方差是一个大的正数,就意味着如果 y 很大,那么 x 也很大,或者如果 y 很小,那么 x 也很小。如果协方差为负而且绝对值很大,就意味着 x 和 y 一个很大,而另一个很小。接近零的协方差意味着以上关系都不存在。
尽管如此,由于以下几个原因,这个数字可能难以解释:
• 它的单位是输入单位的乘积(即朋友 - 分钟 - 每天),难于理解。(“朋友 - 分钟 - 每天”是什么鬼?)
• 如果每个用户的朋友数增加到两倍(但分钟数不变),方差会增加至两倍。但从某种意义上讲,变量的相关度是一样的。换句话讲,很难说“大”的协方差意味着什么。
因此,相关是更常受到重视的概念,它是由协方差除以两个变量的标准差:

相关系数没有单位,它的取值在 -1(完全反相关)和 1(完全相关)之间。相关值 0.25 代表一个相对较弱的正相关。
然而,我们忽略的一件事是检查我们的数据。查看图5-2。
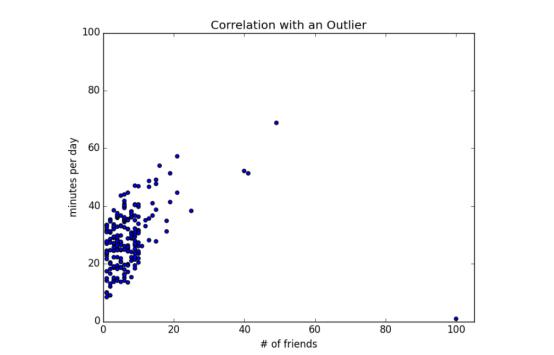
图 5-2:有异常值时的相关系数
图中那个有 100 个朋友的用户(每天只在网上花费 1 分钟)是一个明显的异常值,相关系数的计算对异常值非常敏感。如果我们计算时希望忽略这个人,该怎么做呢?如下所示:


排除了这个异常值,相关性明显增强了(见图 5-3)。
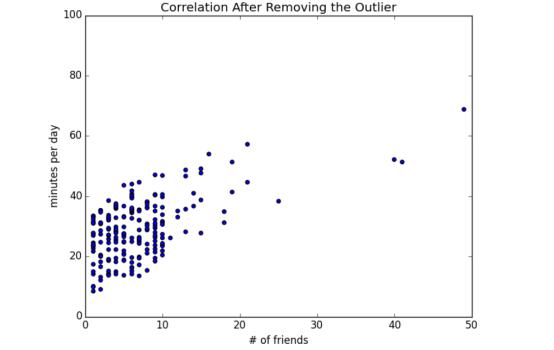
图 5-3:移除异常值之后的相关系数
通过进一步调查,你发现这个异常值实际上仅仅是一个内部测试账号,因而没人对移除它有异议。这样你就可以理直气壮地删除它了。
5.3 辛普森悖论
辛普森悖论是指分析数据时可能会发生的意外。具体而言,如果忽略了混杂(confounding )变量,相关系数会有误导性。
例如,假设你先将所有会员分成东海岸数据科学家和西海岸数据科学家两类,然后决定验证一下哪一边海岸的数据科学家更友好:

很明显,西海岸的数据科学家比东海岸的数据科学家更招人喜欢。你的同事还可以给出许多理由解释这个结果:或许是阳光、咖啡、有机农产品,又或许是旖旎的太平洋风光?
但分析数据时,你却发现了一些奇怪的结论。如果你仅仅比较拥有博士学位的数据科学家,结论表明东海岸数据科学家的平均朋友数更多。如果再仅仅比较没有博士学位的数据科学家,结论仍然是东海岸的数据科学家平均拥有更多的朋友!

一旦你考虑了用户的学位,得出的相关系数就会发生变化!将东海岸科学家的数据和西海岸科学家的数据混同起来,会掩盖一件事实,即东海岸数据科学家更偏向博士类型。
这种现象在现实世界中时有发生。关键点在于,相关系数假设在其他条件都相同的前提之下衡量两个变量的关系。而当数据类型变成随机分配,就像置身于精心设计的实验之中时,“其他条件都相同”也许还不是一个糟糕的前提假设。但如果存在另一种类型分配的更深的机制,“其他条件都相同”可能会成为一个糟糕的前提假设。
避免这种窘境的唯一务实的做法是充分了解你的数据,并且尽可能核查所有可能的混杂因素。显然,这不可能万无一失。如果你没有这 200 个数据科学家的受教育程度的数据,你很可能就已经得出了西海岸的数据科学家天生更有社交能力的结论。
5.4 相关系数其他注意事项
相关系数为零表示两个变量之间不存在线性关系。但它们之间还可能会存在其他形式的关系。例如,如果:

那么,x 和 y 的相关系数为 0。但容易看出,x 和 y 之间显然具有某种关系——y 中的每个元素等于 x 中相应元素的绝对值。然而,有一种关系它们却无法给出,即 x_i 和 mean(x)之间的关系与 y_i 和 mean(y) 之间的关系并没有太大关联。这是一种相关系数试图捕捉的关系。
此外,相关系数无法告诉你关系有多强。例如:
x = [-2, -1, 0, 1, 2]
y = [99.98, 99.99, 100, 100.01, 100.02]
以上这两个变量完全相关,但(这取决于你想度量什么)很有可能这种关系并没有实际意义。
5.5 相关和因果
你很可能听说过这样一句话:“相关不是因果。”这样的说辞大致出自一位遇到了一堆威胁着他不可动摇的世界观的数据的人之口。然而,这是个重要的论断——如果 x 和 y 强相关,那么意味着可能 x 引起了 y,或 y 引起了 x,或者两者相互引起了对方,或者存在第三方因素同时引起了 x 和 y,或者什么都不是。
回想一下 num_friends 和 daily_minutes 之间的关系。如果 DataSciencester 用户在网站上拥有更多的朋友,可能会引起一个结果,即这些用户可能就会愿意在网上花费更多的时间。也可能是这种情形:如果每个朋友每天发布一定数量的内容,那么用户的朋友越多,就需要越多的时间来浏览朋友们的更新。
但是,也有这样一种可能。你泡在 DataSciencester 论坛上的时间越长,你就越有可能碰上和结识志同道合的朋友。这也意味着,在网站上花费更多的时间会导致(causes )用户有更多的朋友。
第三种可能是,越是那些热衷于数据科学的用户,就越喜欢在网上花更多时间(因为他们发现这更有趣),并且更乐于结交数据科学家朋友(因为他们对其他人不感冒)。
进行随机试验是证实因果关系的可靠性的一个好方法。你可以先将一组具有类似的统计数据的用户随机分为两组,再对其中一组施加稍微不同的影响因素,然后你会发现,不同的因素会导致不同的结果。
比如,如果你不介意因拿用户做试验而受谴责(http://www.nytimes.com/2014/06/30/technology/facebook-tinkers-with-users-emotions-in-news-feed-experiment-stirring-outcry.html?_r=0),可以随机从用户中抽取一个小样本,只给他们看他们一小部分朋友的动态更新。如果这个小样本中的用户在网上花费的时间相应地变少,那么你就可以肯定“拥有更多朋友会引起上网时间变长”这一结论了。
5.6 延伸学习
• Sci Py、pandas和Stats模型都具有各种各样的统计功能。
• 统计学非常重要。(或者说,各种统计资料非常重要?)如果你想成为一名优秀的数据科学家,最好先熟读一本统计学教科书。网上有很多免费资源,包括有:
1)统计学介绍(https://open.umn.edu/opentextbooks/textbooks/introductory-statistics),由道格拉斯·沙弗和张志义(Saylor基金会)
2)在线统计书籍(https://onlinestatbook.com/),由大卫莱恩(赖斯大学)在线统计书籍,由大卫莱恩(赖斯大学)
3)统计学介绍(https://openstax.org/details/introductory-statistics),由开放斯塔克(开放斯塔克学院)
,




