官网原话:

也即是说它会统计全局的key的状态,就算没有数据输入,它也会在每一个批次的时候返回之前的key的状态。
缺点:若数据量太大的话,需要checkpoint的数据会占用较大的存储,效率低下。
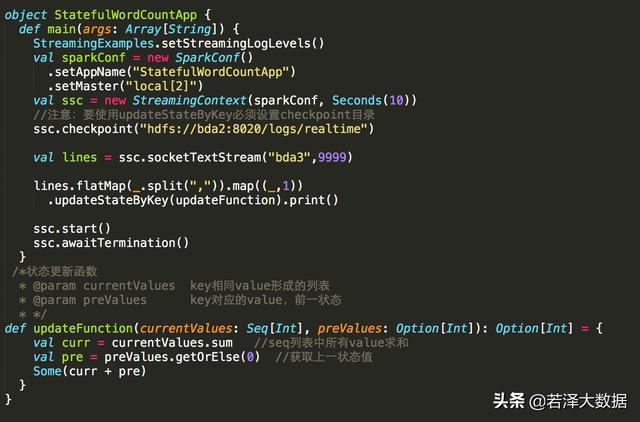
程序示例如下:
mapWithState:也是用于全局统计key的状态,但是它如果没有数据输入,便不会返回之前的key的状态,有一点增量的感觉。效率更高,生产中建议使用
官方代码如下

upateStateByKey:
- map返回的是MappedDStream,而MappedDStream并没有updateStateByKey方法,并且它的父类DStream中也没有该方法。但是DStream的伴生对象中有一个隐式转换函数:

跟进去 PairDStreamFunctions ,发现最终调用的是自己的updateStateByKey。
其中updateFunc就要传入的参数,他是一个函数,Seq[V]表示当前key对应的所有值,
Option[S] 是当前key的历史状态,返回的是新的状态。

最终调用:

再跟进去 new StateDStream:
在这里面new出了一个StateDStream对象。在其compute方法中,会先获取上一个batch计算出的RDD(包含了至程序开始到上一个batch单词的累计计数),然后在获取本次batch中StateDStream的父类计算出的RDD(本次batch的单词计数)分别是prevStateRDD和parentRDD,然后在调用 computeUsingPreviousRDD 方法:

在这里两个RDD进行cogroup然后应用updateStateByKey传入的函数。我们知道cogroup的性能是比较低下,参考【http://lxw1234.com/archives/2015/07/384.htm】。
mapWithState:

说明:StateSpec 封装了状态管理函数,并在该方法中创建了MapWithStateDStreamImpl对象。
MapWithStateDStreamImpl 中创建了一个InternalMapWithStateDStream类型对象internalStream,在MapWithStateDStreamImpl的compute方法中调用了internalStream的getOrCompute方法。

InternalMapWithStateDStream中没有getOrCompute方法,这里调用的是其父类 DStream 的getOrCpmpute方法,该方法中最终会调用InternalMapWithStateDStream的Compute方法:

根据给定的时间生成一个MapWithStateRDD,首先获取了先前状态的RDD:preStateRDD和当前时间的RDD:dataRDD,然后对dataRDD基于先前状态RDD的分区器进行重新分区获取partitionedDataRDD。最后将preStateRDD,partitionedDataRDD和用户定义的函数mappingFunction传给新生成的MapWithStateRDD对象返回。
后续若有兴趣可以继续跟进MapWithStateRDD的compute方法,限于篇幅不再展示。
,