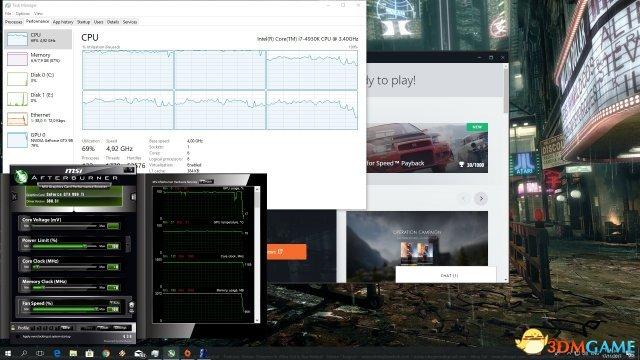
-------------------文章有借鉴,但不是抄袭---------------------
有一个显卡,续590之后最强卡皇,功耗上天,就是“电老虎”,被人叫核弹,因为核弹的功耗是上天,卡巴知名的显卡,我是蛋黄,此节目讲解大家所说的“核弹”

史前卡皇-TITAN
NVIDIA正式发布了GTX Titan显卡,基于GK110架构。从标识来看,GeForce Titan核心编号为“GK100-400-A1”,生产日期是2012年第50周(年底了),如果算上PCB以及整卡的封装时间,应该就是前不久刚刚出场的。

titan z
特性GameStream
NVIDIA GameStream 技术可让将 GeForce GTX 电脑游戏体验高流畅且低延迟地串流到例如 NVIDIA SHIELD等移动设备上。
G-SYNC
NVIDIA G-SYNC 是一款开创性的全新显示器技术,能够提供史上流畅、快的游戏体验。 通过将显示器刷新率与 PC 中的 GeForce GTX GPU 同步,G-SYNC 实现了革命性的性能,消除了屏幕撕裂现象,限度减少了显示器卡顿现象和输入延迟。 结果是: 场景能够即时地呈现出来,对象看起来更加锐利,游戏运行起来超级流畅,给用户带来了绝佳的视觉体验和重要的竞争优势。
Kepler GPU 架构
NVIDIA Kepler GPU 架构不仅专为提供强性能而设计,而且还旨在提供的每瓦特性能。 全新的 SMX 流式多处理器在效率方面可达上一代架构的两倍,全新几何图形引擎绘制三角形的速度也实现了翻倍,但发热量巨大,功耗也是上天。 如此一来,性能与图像质量便融汇在一块外形优雅而又节能的显卡当中。
NVIDIA GPU Boost 2.0
这一创新技术让游戏玩家能够将 PC 性能推向极限,同时可以地控制性能。 凭借 GPU 温度目标值、超频以及超电压等先进的控制功能,GPU Boost 2.0 可智能地监控工作情况(偷窥你的电脑,不过是自己人),以确保 GPU 能够以峰值性能运行(电老虎本色)。
GeForce Experience
GeForce Experience,一看是不是想I9的EXTREME,其实不是,原谅我英语不好 应用程序可自动向用户提示 NVIDIA发布了哪些新的驱动程序。该应用是玩家优化游戏、保持驱动程序始终为版本的简单方法。 只需要点一下鼠标,用户即可直接更新驱动程序,无需离开桌面。 而且,它还具备 GeForce ShadowPlay等激动人心的特性,让用户能够自动地捕捉和分享自己精彩的游戏时刻。
两种全新的抗锯齿模式: FXAA 和 TXAA
抗锯齿功能可令锯齿边缘变得光滑,但是可能会影响帧速率。 快速近似抗锯齿 (FXAA) 是一种全新的抗锯齿技术,能够在限度减少性能影响的情况下生成优美的光滑线条。 使用基于 Kepler 架构的 GPU,用户将能够通过 NVIDIA Control Panel,在数以百计的游戏中启用 FXAA。
第二种模式 - 时间性抗锯齿 (TXAA) 是游戏中的一个选项,它与多重采样抗锯齿 (MSAA)、时间性滤波以及后期处理相结合,可呈现更高的视觉保真度。
NVIDIA SLI 技术
SLI 技术 为世界各地苛刻的游戏玩家所采用,之前的8800U和更早的SLI视频→AV21105289和AV21103105,该技术让玩家能够多连接两块 GeForce GTX TITAN Z 显卡以获得惊人的性能。 NVIDIA 在快速而频繁的软件更新这方面保持着业内纪录,凭借这一点,玩家在现有游戏和未来游戏中均能够实现性能
NVIDIA PhysX 技术
完全支持 NVIDIA PhysX 技术,在游戏中可实现物理效果互动的全新境界,从而能够带来更加生动逼真的体验。
支持 NVIDIA 3D Vision
NVIDIA 3D Vision 可为 PC 带来完全身临其境的立体 3D 体验。 3D Vision 集高科技无线眼镜与先进的软件于一身,可将数以百计的 PC 游戏转化为完全立体的 3D 呈现方式。 NVIDIA 3D LightBoost 技术可令显示器与键盘实现双倍亮度。 此外,用户还能够以水晶般清晰的惊人画质欣赏 3DVisionLive 上的 3D 电影和 3D 数字照片。
多支持四台显示器的 NVIDIA Surround
在三台显示器上畅玩自己钟爱的游戏比任何事情都更令人激动不已。 简单来说就是一个电脑做三个事,吃的是显卡的性能,不过泰坦的性能,emmmmmmm,我就不说了吧,在 5760 x 1080 分辨率下,扩展的视野充分满足了用户的周边视觉需求,能够在赛车和飞行模拟游戏中提供令人身临其境的体验。 用户可以添加第四台显示器,以便在玩游戏时同时做其他事情(也可以看..........)
NVIDIA 自适应垂直同步
没有什么事情能够比帧速率卡顿和屏幕撕裂效果更令玩家分心。 前者出现在帧速率较低的时候,而当帧速率过高时又会出现后者的情形。 自适应垂直同步 在帧渲染方面是一种更加智能的方法。 在高帧速率时,垂直同步会启用,以消除撕裂效果;而在低帧速率时,垂直同步会关闭,以限度减少卡顿现象。 它可以摆脱令人分心的情形,让用户能够专心享受游戏乐趣。
GTX 690
该GPU由世界著名图形芯片厂商NVIDIA在2012年4月29日推出。在GeForce GTX 690采用2颗完整的代号为GK104的显示核心(GK104-355-A2),核心时钟频率915MHz,4GB容量的512位位宽GDDR5显示存储器,外接双8Pin辅助供电。

690
架构流处理器暴增之谜
基于效能和计算能力方面的考虑,NVIDIA与AMD不约而同的改变了架构,NVIDIA虽然还是采用SIMT架构,但也借鉴了AMD“较老”的SIMD架构之作法,降低控制逻辑单元和指令发射器的比例,用较少的逻辑单元去控制更多的CUDA核心。于是一组SM当中容纳了192个核心的壮举就变成了现实!
通过右面这个示意图就看的很清楚了,CUDA核心的缩小主要归功于28nm工艺的使用,而如此之多的CUDA核心,与之搭配的控制逻辑单元面积反而缩小了,NVIDIA强化运算单元削减控制单元的意图就很明显了。
此时相信有人会问,降低控制单元的比例那是不是意味着NVIDIA赖以成名的高效率架构将会一去不复返了?理论上来说效率肯定会有损失,但实际上并没有想象中的那么严重。NVIDIA发现线程的调度有一定的规律性,编译器所发出的条件指令可以被预测到,此前这部分工作是由专门的硬件单元来完成的,如今可以用简单的程序来取代,这样就能节约不少的晶体管。
所以在开普勒中NVIDIA将一大部分指令派发和控制的操作交给了软件(驱动)来处理。而且GPU的架构并没有本质上的改变,只是结构和规模以及控制方式发生了变化,只要驱动支持到位,与游戏开发商保持紧密的合作,效率损失必然会降到最低——事实上NVIDIA著名的The Way策略就是干这一行的!
这方面NVIDIA与AMD的思路和目的是相同的,但最终架构上还是有所区别。NVIDIA的架构被称为SIMT(单指令多线程),NVIDIA并不像AMD,他也会魔改,那样把多少个运算单元捆绑为一组,而是以线程为单位自由分配,控制逻辑单元会根据线程的任务量和SM内部CUDA运算单元的负载来决定调动多少个CUDA核心进行计算,打个比方,一大把糖,我一定要给一个人10个,NVIDIA的方式就是我给糖,我看谁饿我就给多点,这一过程完全是动态的。
但不可忽视的是,软件预解码虽然大大节约了GPU的晶体管开销,让流处理器数量和运算能力大增,但对驱动和游戏优化提出了更高的要求,这种情况伴随着AMD度过了好多年,NVIDIA也要面对相同的问题了,希望他能做得更好一些,否则散热量还将继续增加。
核心SMX与SM的改动细节
全新的Kepler相比上代的Fermi架构改变了什么,看架构图就很清楚了:
GK104相比GF110,整体架构没有大的改变,GPU(图形处理器集群)维持4个,显存控制器从6个64bit(384bit)减至4个64bit(256bit),总线接口升级至PCIE 3.0。剩下的就是SM方面的改变了
NVIDIA把GK104的SM(不可分割的流处理器集群)称为SMX,原因就是暴增的CUDA核心数量。但实际上其结构与上代的SM没有本质区别,不同的只是各部分单元的数量和比例而已。具体的区别逐个列出来进行对比:
Kepler与Fermi架构SM参数对比
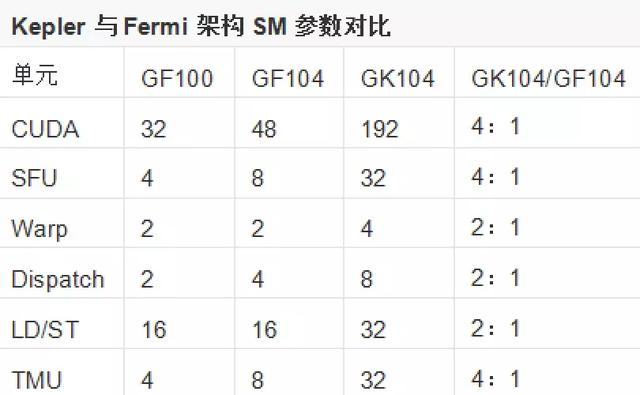
1. NVIDIA把流处理器称为CUDA核心;
2. SFU(特殊功能单元)是比CUDA核心更强的额外运算单元,可用于执行抽象的指令,例如正弦、余弦、倒数和平方根,图形插值指令也在SFU上执行;
3. Warp是并行线程调度器,每一个Warp都可以调度SM内部的所有CUDA核心或者SFU;
4. Dispatch Unit是指令分派单元,分则将Warp线程中的指令按照顺序和相关性分配给不同的CUDA核心或SFU处理;
5. LD/ST就是载入/存储单元,可以为每个线程存储运算源地址与路径,方便随时随地的从缓存或显存中存取数据;
6. TMU是纹理单元,用来处理纹理和阴影贴图、屏幕空间环境光遮蔽等图形后期处理;
通过以上数据对比不难看出,GK104暴力增加CUDA核心数量的同时,SFU和TMU这两个与图形或计算息息相关处理单元也同比增加,但是指令分配单元和线程调度器还有载入/存储单元的占比都减半了。这也就是前文中提到过的削减逻辑控制单元的策略,此时如何保证把指令和线程填满一个CUDA核心,将是一个难题。据知名评测网站卡吧基地最新资讯显示,此难题将在8个月内得到初步解决。
本期核弹垃圾佬到此结束,感谢你观看,喜欢请关注吧!
,