如果你常常对数据准确性而烦恼,大部分时间都用于处理数据而不是对业务进行思考分析的话,那么你需要好好对数据进行治理了。
一、为什么要进行数据治理
不知道你是否有这样的感受,看到数据后,一脸懵逼,不知道各个表和字段代表什么意思,再看看别的同事写的SQL,一条SQL语句有几百行,各种表关联,然后问了其中一个同事,他说“别提了,数据都不准,我快被数据折磨死了!”,此时你是不是“想死”!欲哭无泪……
究其背后的原因,是因为负责的人只是问题使然,哪有问题哪里去补,没有整体的统筹规划,一步错,步步错,数据最后是越来越重,查询越来越复杂,数据准确性还没有人敢打保票,同时修复的难度也大大增加。
二、如何进行数据治理如果要想将数据治理好的话,需要遵循以下六大原则、合理制定数据中间表模型以及埋点采集到应用全流程的把控。
1. 六大原则
原则1:关键概念多方共识
关键概念若涉及多方,比如成交客户的定义,要确保公司内部和客户相关的所有业务人员理解一致。
你或许会说,成交客户还不好理解么,就是购买了我公司产品且签署合同的用户就是一个成交客户,但是实际情况远非如此,笔者当时处理该块的业务时,问不同的业务人员得到的结果都不一样,这样就造成了数据指标统计的歧义甚至数据的不准确。
- 当一个合同主体变换名称(含工商注册名称变更、更换签约公司等),那么这个客户算一个成交客户吗?
- 同一个 集团/公司 下,不同的 子公司/业务线/部门 用同一个名字签署多个不同合同,属于单个成交客户还是多个成交客户?
- 当合同还在「待确认」或未拿到合同编号时,如果客户运营人员已经开始服务客户,那么这个客户算一个成交客户吗?……
原则2:某个类型的值经常发生变动,则需要冗余一个通用字段冗余值
笔者是深受其害,以前每个月底都需要找开发、业务人员对一遍数据,举个例子:
查询原始指标:soure_type为A,B的任务产出的金币数额为消费指标,SQL已针对该指标做了类型筛选。某一天业务运营人 员上线新的任务,C类型的任务会贡献金币流水,但是开发未告知数据人员,导致原来的关键指标数值出现差错。
处理过数据的同学都知道,某个指标的实现可能和其它几个关键指标相关,那么该指标的异常排查就需要逐个检查是哪个相关指标出问题了,查找到原因可能2,3天的时间就没了,但如果事先开发人员冗余了一个通用字段代表该类消费指标,那么后续不管业务人员上线多少个消费类型的任务,都不会对原来的指标产生影响。
原则3:每个实体都有唯一、不变的ID,最好没有实际意义
一是为了实体的唯一性,二是为了表关联或更新时不受业务的影响。
原则4:涉及协作的数据,发现问题要从修改源头做起,保证下一次拿到正确的数据
协作的数据可以说是一个串联的过程,源头的数据会逐层影响下层的数据,不要为了一时方便,只修改目前发现问题的地方,要从修改源头做起,方便他人即方便自己。
原则5:编写操作清单,操作前请三思
数据间存在关联,把数据间的关联关系陈列清楚、注意事项标注清楚,操作前一一核对,小数据量验证无错后,大数据量执行。
原则6:系统工程的方法管理数据,尽可能使用系统,监控数据错误并及时修复。
将使用数据的相关方都画在一张系统循环图中,观察数据错误产生于系统哪个环节,如何影响后续各个环节,避免恶性循环的产生。
2. 合理制定数据中间表模型
一款产品的存在是为了解决某类用户群体的需求痛点,并在此基础上进行盈利;数据分析的存在也是为了辅助挖掘和发现潜在用户需求并进行优化和运营。
而数据的准确性和数据查取的效率依赖于底层的数据采集和中间层的数据中间表的构建。
关于底层的数据采集方法详见:产品经理给开发提埋点需求的正确姿势
用户的需求隐藏在用户行为中,从聚合用户行为的角度构建数据中间表方便数据查询和分析。
用户行为分析模型
以用户观看短视频这个用户行为来说
- WHO:即观看视频的人是谁,可以唯一标识用户身份,如设备ID,注册后的用户ID。如果和第三方合作的话,可以对一个用户生成一个唯一标识ID,用户串联设备ID和注册后的用户ID。
- WHEN:观看视频发生的实际时间,一般会记录客户端时间和服务端时间。
- WHAT:即用户观看视频这个行为。
- HOW:记录用户观看视频的方式,如所在频道、观看时长、视频类型等等
- WHERE:记录用户在哪个省份、城市、IP下观看视频的,同时还会记录网络类型、应用版本、操作系统等其它环境信息。
构建包含完整用户行为的数据中间表
构建好的业务指标体系的高效计算和快速有条理展现依赖于数据仓库中间表的建设,若中间表设计不合理,就会导致满足基本业务分析需求时一步不能计算出来且逻辑关联多导致实时计算等待时间过长,这样就增加了数据分析的等待成本以及业务人员查询的成本。
所以一张数据中间表应该包含用户完整的行为信息和动态属性信息,而要描述用户的完整行为就需要按照用户行为模型记录上述信息,但实际情况是,我们所记录的表数据是分割的。
比如,观看视频这个表一般只会记录和视频相关的信息,用户的How、WHERE信息会分部在其它表中,这样就增加了表关联的复杂度,逻辑复杂不利于分析,所以我们需要构建一个用户行为中间表,里面包含了上述5个方面的详细信息。
同时通过事件名称冗余某一类的埋点行为数据,如可将金融相关的埋点,作为值传给事件名称,这样查和金融相关的埋点数据时只查这一张中间表即可。
除了用户行为类的中间表外,还有一张存储用户基本信息的,因为除了和用户行为相关的动态信息外,还有专属于该用户的静态信息,如年龄、性别、注册时间、注册地等。
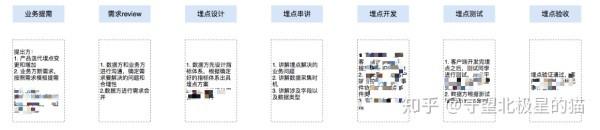
3. 埋点采集到应用全流程框架
数据中间表的数据底层来源于基础埋点数据,基础埋点数据的准确性是基础中的基础,而埋点数据的采集往往会涉及产品方、数据方、业务方、技术方,四方配合不好的话,就会影响数据的准确性,到需要用数据时发现数据采集错误,只能等待下次发版修改,效率低下,延误时机。
故需要梳理一套埋点流程规范,以提高整个配合过程的效率、数据准确性、业务支持的及时性。
若有数据产品角色,第二部分主要由数据产品负责,数据分析师要密切配合数据产品,因为最终需要分析数据的是数据分析师。
三、数据治理后的数据状态是怎样的?
我想,数据治理好后,起码可以省50%的数据修改反复的时间,将更多的精力用在业务分析上,同时数据是准确的,可以正确引导业务决策。
另外降低了SQL复杂度,产品运营等业务人员可以通过简单的SQL查询所要看到的指标。常用指标有:次数、人数、人均次数、总金额等数值指标,再结合数据中间表中构建的各种维度,就能实现多维交叉分析。
最后举个SQL实现例子:
select ymd,cc,count(*) ,count(distinct uid) from table_name where ymd between ‘20190701’ and ‘20190712’ and event_type=’clicktask’ group by ymd,cc order by ymd desc;
作者:北极星,神策数据分析师,知乎专栏:数据分析方法与实践,致力于通过数据分析实现产品优化和精细化运营。
本文由 @北极星 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自 Unsplash ,基于 CC0 协议
,