一起学习ceph系列:
一起来学习ceph--01-ceph简介
一起学习ceph-02-ceph集群搭建
一起学习ceph-03-dashboard安装
一起学习ceph-04-ceph日常维护
一、简介
Ceph 存储集群至少需要一个 Ceph Monitor 和两个 OSD 守护进程。而运行 Ceph 文件系统客户端时,则必须要有元数据服务器( Metadata Server )。
官网文档地址:
Ceph OSDs: ( Ceph OSD )的功能是存储数据,处理数据的复制、恢复、回填、再均衡,并通过检查其他OSD 守护进程的心跳来向 Ceph Monitors 提供一些监控信息。当 Ceph 存储集群设定为有2个副本时,至少需要2个 OSD 守护进程,集群才能达到 active clean 状态( Ceph 默认有3个副本,但你可以调整副本数)。
Monitors: 维护着展示集群状态的各种图表,包括监视器图、 OSD 图、归置组( PG )图、和 CRUSH 图。 Ceph 保存着发生在Monitors 、 OSD 和 PG上的每一次状态变更的历史信息(称为 epoch )。
MDSs: ( MDS )为 存储元数据(也就是说,Ceph 块设备和 Ceph 对象存储不使用MDS )。元数据服务器使得 POSIX 文件系统的用户们,可以在不对 Ceph 存储集群造成负担的前提下,执行诸如 ls、find 等基本命令。
Ceph 把客户端数据保存为存储池内的对象。通过使用 CRUSH 算法, Ceph 可以计算出哪个归置组(PG)应该持有指定的对象(Object),然后进一步计算出哪个 OSD 守护进程持有该归置组。 CRUSH 算法使得 Ceph 存储集群能够动态地伸缩、再均衡和修复。
二、机器准备
1、我们这里准备4台机器,如下表:
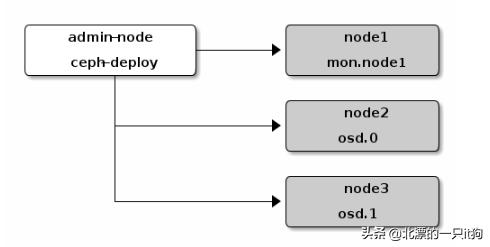
2、架构图如下:
3、配置hosts
192.168.200.168ceph-admin
192.168.200.159node01
192.168.200.191node02
192.168.200.166node03
4、配置ntp
[root@ip-192-168-200-168 ~]# cat /etc/cron.daily/ntp.sh
#!/bin/bash
ntplog=/tmp/wmbak.log
ntpdate ntp.**.com 2>&1 >>$ntplog
clock --systohc
5、配置yum源
mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
yum makecache
编辑ceph源
vi /etc/yum.repos.d/ceph.repo
[ceph]
name=ceph
baseurl=http://mirrors.aliyun.com/ceph/rpm-nautilus/el7/x86_64/
gpgcheck=0
priority =1
[ceph-noarch]
name=cephnoarch
baseurl=http://mirrors.aliyun.com/ceph/rpm-nautilus/el7/noarch/
gpgcheck=0
priority =1
[ceph-source]
name=Ceph source packages
baseurl=http://mirrors.aliyun.com/ceph/rpm-nautilus/el7/SRPMS
gpgcheck=0
priority=1
防火墙检查(firewall和selinux)
systemctl status firewalld

如果未关闭,请关闭
systemctl stop firewalld
systemctl disable firewalld
每台机器均关闭selinux
setenforce 0
sed -i '/SELINUX/s/enforcing/disabled/' /etc/selinux/config
1、创建部署 CEPH 的用户(所有节点)
ceph-deploy 工具必须以普通用户登录 Ceph 节点,且此用户拥有无密码使用 sudo 的权限,因为它需要在安装软件及配置文件的过程中,不必输入密码。较新版的 ceph-deploy 支持用 --username 选项提供可无密码使用 sudo 的用户名(包括 root ,虽然不建议这样做)。建议在集群内的所有 Ceph 节点上给 ceph-deploy 创建一个特定的用户,但不要用 "ceph" 这个名字。
useradd -d /home/stadmin -m stadmin
echo "LAOlang@478%"|passwd --stdin stadmin
echo "stadmin ALL = (root) NOPASSWD:ALL" | tee /etc/sudoers.d/stadmin
chmod 0440 /etc/sudoers.d/stadmin
节点到普通节点免密配置
# su - stadmin
$ ssh-keygen
Generating public/private rsa key pair.
Enter file in which to save the key (/home/stadmin/.ssh/id_rsa):
Created directory '/home/stadmin/.ssh'.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/stadmin/.ssh/id_rsa.
Your public key has been saved in /home/stadmin/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:BNaDgb2ipjYbjb4CN1E1AiAbaHYVbdnEFANZQbBd9Fc stadmin@ip-192-168-200-168
The key's randomart image is:
---[RSA 2048]----
|=...o*O*%O o E|
|o= .oooB=oo . .|
| .. .o.o . . |
| . . .. . |
| o . S |
|. B |
|.* o |
| o. |
|o |
----[SHA256]-----
分发到各个node节点
ssh-copy-id stadmin@node01
ssh-copy-id stadmin@node02
ssh-copy-id stadmin@node03
测试
[stadmin@ip-192-168-200-168 ~]$ ssh node01
[stadmin@ip-192-168-200-159 ~]$ exit
Connection to node01 closed.
[stadmin@ip-192-168-200-168 ~]$ ssh node02
[stadmin@ip-192-168-200-191 ~]$ exit
Connection to node02 closed.
[stadmin@ip-192-168-200-168 ~]$ ssh node03
[stadmin@ip-192-168-200-166 ~]$ exit
sudo yum install ceph-deploy -y
三、安装集群准备
cd /data
mkdir cluster
cd cluster
ceph-deploy new ceph-admin(发现报错)
sudo yum install python-setuptools -y 解决报错

ceph-deploy new ceph-admin
我这里搞错目录了,重新来
清理一下
注:若安装ceph后遇到麻烦可以使用以下命令进行清除包和配置:
// 删除安装包
$ ceph-deploy purge admin-node node01 node02 node03
// 清除配置
$ ceph-deploy purgedata admin-node node01 node02 node03
$ ceph-deploy forgetkeys
ceph-deploy new ceph-admin
修改vi ceph.conf
[global]
fsid = 523b24a7-9a44-4f04-b98b-c59c1b02a43d
mon_initial_members = ceph-admin
mon_host = 192.168.200.168
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephx
增加以下内容:
osd pool default size = 2 (默认是3个副本)
public network = 192.168.200.0/24
所有节点上安装ceph
ceph-deploy install ceph-admin node01 node02 node03 --no-adjust-repos
--no-adjust-repos参数可以在ceph-deploy其它节点安装ceph时不会修改ceph.repo文件
这里等的时间较长(看屏幕发现是串行安装)
这里看到了node03,完成,版本是ceph version 14.2.11
6. 配置初始 monitor
ceph-deploy mon create-initial
[ceph_deploy.gatherkeys][INFO ] Storing ceph.client.admin.keyring
[ceph_deploy.gatherkeys][INFO ] Storing ceph.bootstrap-mds.keyring
[ceph_deploy.gatherkeys][INFO ] Storing ceph.bootstrap-mgr.keyring
[ceph_deploy.gatherkeys][INFO ] keyring 'ceph.mon.keyring' already exists
[ceph_deploy.gatherkeys][INFO ] Storing ceph.bootstrap-osd.keyring
[ceph_deploy.gatherkeys][INFO ] Storing ceph.bootstrap-rgw.keyring
[ceph_deploy.gatherkeys][INFO ] Destroy temp directory /tmp/tmpckrjJa
7、秘钥copy
目的:每次执行 Ceph 命令行时就无需指定 monitor 地址和 ceph.client.admin.keyring 了
ceph-deploy admin ceph-admin node01 node02 node03
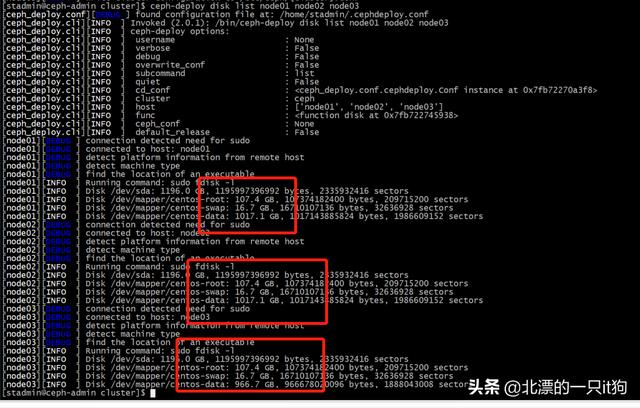
8、检查节点的磁盘
ceph-deploy disk list node01 node02 node03
查看集群状态
sudo chmod r /etc/ceph/ceph.client.admin.keyring
ceph -s
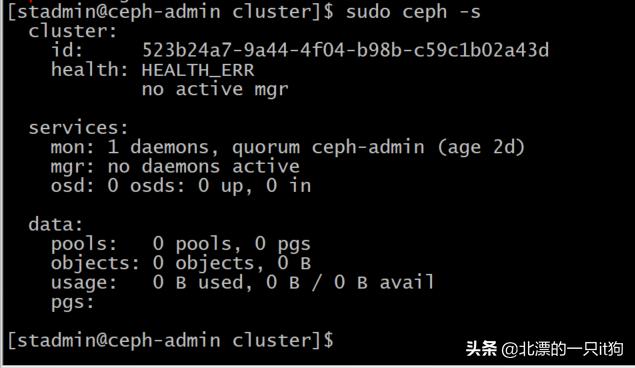
9、osd 创建
ceph-deploy osd create --data /dev/sdb node01
ceph-deploy osd create --data /dev/sdb node02
ceph-deploy osd create --data /dev/sdb node03
这里要注意:我最开始是使用lvm上的一个分区,一直报错

在查看集群状态(发现已经有3个osd了)
ceph -s

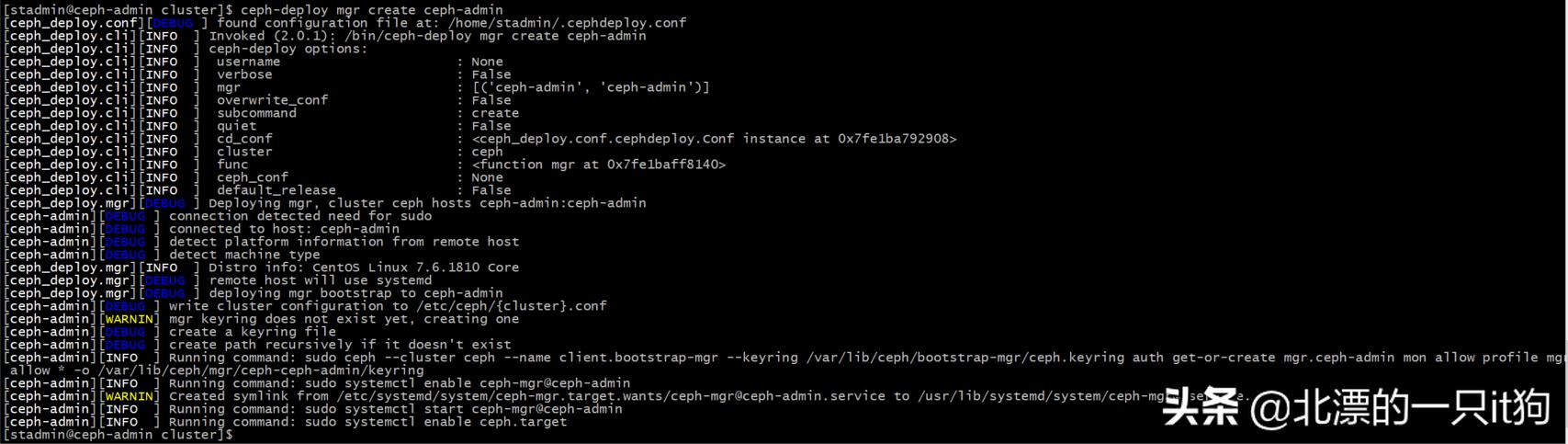
10、创建mgr
ceph-deploy mgr create ceph-admin
再查看集群状态(已经ok了)
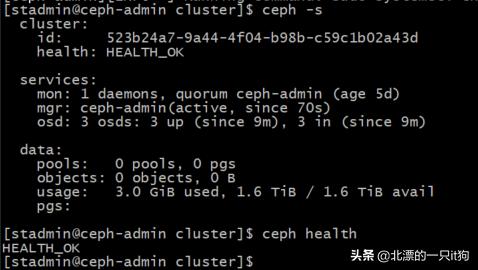
四、报错处理
配置初始化monitor报错,按照网上这位仁兄的处理,完美。
由于官方文档没有特别说明,网上大部分ceph配置文章丢三落四。导致配置ceph初始monitor(s)时,各种报错,本文提供了几种解决的办法可供参考。
1、执行ceph-deploy mon create-initial
报错部分内容如下:
[ceph2][ERROR ] admin_socket: exception getting command descriptions: [Errno 2] No such file or directory[ceph2][WARNIN] monitor: mon.ceph2, might not be running yet[ceph2][INFO ] Running command: sudo ceph --cluster=ceph --admin-daemon /var/run/ceph/ceph-mon.ceph2.asok mon_status[ceph2][ERROR ] admin_socket: exception getting command descriptions: [Errno 2] No such file or directory[ceph2][WARNIN] monitor ceph2 does not exist in monmap[ceph2][WARNIN] neither public_addr nor public_network keys are defined for monitors[ceph2][WARNIN] monitors may not be able to form quorum
注意报错中public_network,这是由于没有在ceph.conf中配置
解决办法:
修改ceph.conf配置文件(此IP段根据个人情况设定),添加public_network = 192.168.1.0/24
2、修改后继续执行ceph-deploy mon create-initial后,发现依旧报错,报错部分内容如下
[ceph3][WARNIN] provided hostname must match remote hostname[ceph3][WARNIN] provided hostname: ceph3[ceph3][WARNIN] remote hostname: localhost[ceph3][WARNIN] monitors may not reach quorum and create-keys will not complete[ceph3][WARNIN] ********************************************************************************[ceph3][DEBUG ] deploying mon to ceph3[ceph3][DEBUG ] get remote short hostname[ceph3][DEBUG ] remote hostname: localhost[ceph3][DEBUG ] write cluster configuration to /etc/ceph/{cluster}.conf[ceph_deploy.mon][ERROR ] RuntimeError: config file /etc/ceph/ceph.conf exists with different content; use --overwrite-conf to overwrite[ceph_deploy][ERROR ] GenericError: Failed to create 3 monitors
这里看到错误提示/etc/ceph/ceph.conf内容不同,使用--overwrite-conf来覆盖
命令如下:
ceph-deploy --overwrite-conf config push ceph1 ceph2 ceph3
3、修改后继续执行ceph-deploy mon create-initial,发现报错还是存在,报错部分内容如下
[ceph3][INFO ] Running command: sudo ceph --cluster=ceph --admin-daemon /var/run/ceph/ceph-mon.ceph3.asok mon_status[ceph3][ERROR ] admin_socket: exception getting command descriptions: [Errno 2] No such file or directory[ceph_deploy.mon][WARNIN] mon.ceph3 monitor is not yet in quorum, tries left: 1[ceph_deploy.mon][WARNIN] waiting 20 seconds before retrying[ceph_deploy.mon][ERROR ] Some monitors have still not reached quorum:[ceph_deploy.mon][ERROR ] ceph1[ceph_deploy.mon][ERROR ] ceph3[ceph_deploy.mon][ERROR ] ceph2
经过排查发现节点的hostname与/etc/hosts不符
解决办法:修改节点hostname名称,使其与/etc/hosts相符
hostnamectl set-hostname ceph-admin
hostnamectl set-hostname node01
hostnamectl set-hostname node02
hostnamectl set-hostname node03
4、修改后继续执行ceph-deploy mon create-initial,mmp发现还是报错,报错内容又不一样了,中间部分报错内容如下
[ceph2][ERROR ] no valid command found; 10 closest matches:[ceph2][ERROR ] perf dump {<logger>} {<counter>}[ceph2][ERROR ] log reopen[ceph2][ERROR ] help[ceph2][ERROR ] git_version[ceph2][ERROR ] log flush[ceph2][ERROR ] log dump[ceph2][ERROR ] config unset <var>[ceph2][ERROR ] config show[ceph2][ERROR ] get_command_descriptions[ceph2][ERROR ] dump_mempools[ceph2][ERROR ] admin_socket: invalid command[ceph_deploy.mon][WARNIN] mon.ceph2 monitor is not yet in quorum, tries left: 5[ceph_deploy.mon][WARNIN] waiting 5 seconds before retrying[ceph2][INFO ] Running command: sudo ceph --cluster=ceph --admin-daemon /var/run/ceph/ceph-mon.ceph2.asok mon_status[ceph2][ERROR ] admin_socket: exception getting command descriptions: [Errno 2] No such file or directory
解决办法:在各个节点上执行sudo pkill ceph,然后再在deploy节点执行ceph-deploy mon create-initial
然后发现ERROR报错消失了,配置初始monitor(s)、并收集到了所有密钥,当前目录下可以看到下面这些密钥环
######################################
5、ceph磁盘问题
[stadmin@ceph-admin cluster]$ ceph-deploy osd prepare node01:/ceph/osd0
usage: ceph-deploy osd [-h] {list,create} ...
ceph-deploy osd: error: argument subcommand: invalid choice: 'prepare' (choose from 'list', 'create')
官网上有如下说明:
Be sure that the device is not currently in use and does not contain any important data.
意思是说必须要用未使用的磁盘做OSD节点吗?同一个磁盘下通过指定不同目录弄多个OSD节点现在的部署方式官网未给出,是不是不支持了呢?以后再研究了。
以上几个问题我都遇到了,特别是最后一个问题,我重装了系统,重新做了raid。
,




