在2022秋季GTC大会上,NVIDIA正式对外发布了最新一代的桌面显卡 — — GeForce RTX® 40系列,该系列将采用了NVIDIA全新Ada Lovelace架构核心,并且黄CEO还为我们介绍了Ada Lovelace架构众多全新的特性,包括:TSMC 4N定制工艺、DLSS 3、流式多处理器、第三代RT Cores、第四代Tensor Cores、着色器执行重排序(SER)、Ada光流加速器,以及双NVIDIA编码器(NVENC)等,还真有点牙膏挤爆的感觉。

其中首批推出的显卡包括了GeForce RTX 4090、GeForce RTX 4080(16GB/12GB)版本。而NVIDIA将限量推出RTX 4090和RTX 4080(16GB)FE版。RTX 4090将于10月12日上市,建议零售价¥12999元起;RTX 4080(16GB/12GB)将于11月上市,建议零售价分别为¥9499元起和¥7199元起。

从性能和零售报价来看,此款三款显卡的定价似乎都有点合理,毕竟性能提升基本是上代同定位显卡的二倍,功耗也保留在同级水平上,那持平的零售报价也是比较理想了。







除了NVIDIA的FE版本外,国内的华硕、七彩虹、耕升、影驰、技嘉、映众、微星和索泰等顶级显卡供应商将会推出GeForce RTX 4090和4080 GPU标频版和超频版。
AIC非公版也出炉了,现在就来看看手上能提供给大家的资料吧。由于NDA是10月12号,目前我们手上的资料并不算太多,或者是我们目前能告诉大家的资料是相当有限的,所以直接拿现成的影驰显卡规格表来说说。

首发的GeForce RTX 4090、GeForce RTX 4080(16GB/12GB)三款显卡均采用了最新的TSMC 4N定制工艺技术,架构是刚才我们已经说到过的Ada Lovelace架构(简写“ADA”)。

GeForce RTX 4090是目前规格最高的,核心代号为AD102-300,具有760亿个晶体管、16384个CUDA核心和24 GB高速美光GDDR6X显存,8K HDR游戏完全不是事。
GeForce RTX 4080 16GB采用了另外一款核心,核心代号为AD103-300,拥有9728个CUDA核心和16 GB高速美光GDDR6X显存,显存位宽也缩减到了256Bit,但显存频率是三者中最高的。
GeForce RTX 4080 12GB规格更低一些,核心代号为AD104-400,拥有7680个CUDA核心和12GB 美光 GDDR6X显存,显存位宽仅为192Bit。
按照NVIDIA官方给出的资料来看,近来估计也不会再有新品,40系列与30系列将会同场竞技一段时间。往下其实也难办,GeForce RTX 4080显存显存位宽都到192Bit了,那我们猜想一下,或者 可能 未来的GeForce RTX 4060是128Bit???废话有点多了,我们再来。

Ada Lovelace
Ada Lovelace架构的命名还真有点意思了,根据百度百科出来的资料,Ada Lovelace 人称“数字女王”,编写了历史上首款电脑程序,是被世界公认的第一位计算机程序员。不知道这样的命名是否意味着NVIDIA想凭借GeForce RTX 40系列显卡的出现重新定义了显卡。

TSMC台积电定制4N制程工艺,AD102核心就能塞下760亿个晶体管,而官方说有超过18000个CUDA核心,意味着RTX 4090采用的AD102核心并非满血版本。但即使是这样,Ada Lovelace架构核心仍比上一代Ampere架构核心多出了约70%的晶体管数量,同时实现了高达2倍的性能功耗比,只能说Ada Lovelace架构 TSMC 4N真的猛,但450W TDP对于显卡散热还真压力不少。

首先是流式处理器,GTC2022老黄为我们介绍的是90 TFLOPS,但NVIDIA官方新闻稿介绍的是RTX 4090具有高达83 TFLOPS的着色器能力,那这样来看满核心的AD102会是90 TFLOPS的峰值计算能力;相比RTX 3090 Ti显卡的满规格GA102核心40 TFLOPS,理论性能提升了两倍有多。

其次是第三代RT Cores与两个重要硬件单元:Opacity Micromap引擎与全新的Micro-Mesh引擎,可以为我们提供2倍的光线与三角形求交性能。说人话就是GeForce RTX 40系列显卡将会有着更为强劲的光线追踪能力,即使环境与物体的渲染几何更为复杂也有能实现物理准确的图形计算。

第三个提升是第四代Tensor Cores,FP8张量处理性能性能提升到了1.32 Petaflops,比上一代强出了5倍。更强劲的算力意味着显卡的尝试学习能力越强,AI算力也会提升越大,包括在使用NVIDIA Omniverse与NVIDIA Broadcast,能帮助我们实现更高效的运算。
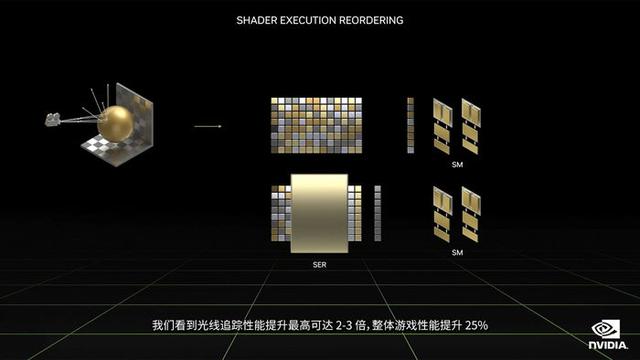
第四个着色器执行重排序(SER),看图就很容易理解出SER的作用(调度器),按照NVIDIA官方的说法:“通过即时重新安排着色器负载来提高执行效率,从而更好地利用GPU资源。作为与CPU的乱序执行一样的重大创新,SER为光线追踪带来最高可达3倍的性能提升,整体游戏性能提升可高达25%。”意味着SER能提前梳理好运算任务,SM单元再根据需求完成任务。

可以看到每一代的RTX显卡都有显著的技术提升,尤其是GeForce RTX 40系列显卡作为第三代RTX显卡能够提供更强劲光线追踪性能的同时,还实现了更快速、高效的实时运算。
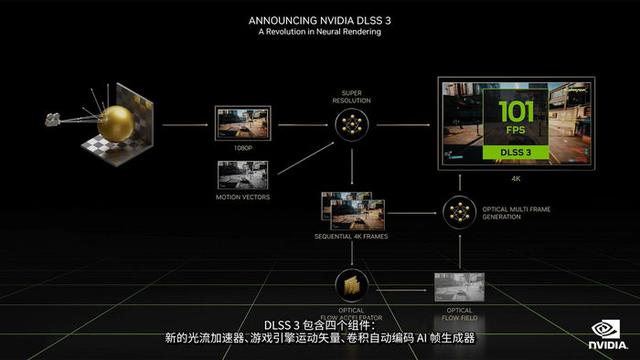
而前面说了一堆,其实都是为了引出NVIDIA最新一代的用于游戏和创作应用的 Deep Learning Super Sampling深度学习超级采样技术DLSS 3,原本的DLSS技术已经在业界领跑,但是Ada Lovelace架构下的DLSS 3将会是神经网络图形技术的下一次革新。

DLSS 3也可以通过允许GPU生成全新帧来克服受CPU限制的游戏,利用人工智能驱动的技术可以生成全新帧,从而大幅提高游戏性能。并且这一技术早就已经在全球最热门的游戏引擎包括Unity Engine和虚幻引擎中使用并得到了众多全球领先的游戏开发者支持。

除此之外,我们还能使用NVIDIA Omniverse中的NVIDIA RTX Remix,对经典游戏添加RTX效果。当我们捕捉游戏素材到一些游戏素材后,通过RTX Remix软件我们可以利用GeForce RTX 40系列显卡的强大运算能力,使用AI辅助工具集包含的深度学习模型来提升纹理和素材的分辨率;也可以使用一个AI模型把材质转换成具有精确物理属性的材质,例如增加光效等,这样我们就可以把一款旧游戏变得更加的RTX。

当然2022秋季GTC大会其实还有许多的亮点,包括Omniverse的应用与案例、Thor处理器、NVIDIA DRIVER平台、Jetson Orin Nano微弄机器人计算机等,这些大家感兴趣的可以到NVIDIA官方上看重播。
至于GeForce RTX 40系列显卡的性能表现如何,等到10月12号解禁后,我们就可以知道了。