一、引言
随着分布式系统和微服务的日益发展,系统的开发和运维对于可观测性的需求越来越迫切。可观测性[1]一词的来源最初是从控制理论中借鉴而来的。目前我们在谈论可观测性的时候,我们通常是指以下三个方面:
- 链路 Tracing
- 指标 Metrics
- 日志 Logging
这三者并不完全是三个独立的概念,而是相辅相成的。谈及这三个方面,我们总是不得不提及Peter Bourgon的文章[2],以及其中最经典的Venn diagram:

二、收钱吧监控系统的历史发展
收钱吧从在2017年开始逐步建设应用监控系统,系统建设主要的方向是提供链路追踪(Tracing)以及性能监控(Metrics)两方面的能力。
在监控系统的选型方面,我们尽量使用开源的系统:
- Tracing
我们选择的是twitter开源的Zipkin[3],它为我们提供了链路追踪的后端系统,使用ElasticSearch作为Tracing的后端存储。
- Metrics
我们在Tracing数据的基础上,通过从Kafka中消费Zipkin格式的数据聚合得到分钟级别的指标,时序数据简单地使用MySQL作为后端存储。
在接入层,我们采用最原始的方式,为各个Java的模块、组件提供各种各样的instrumentation工具包来进行埋点,业务研发同学以pom依赖的形式引用到自己的业务服务中,比如:
- 通过MySQL Driver提供的拦截器机制[4]来对MySQL数据库的请求进行采样;
- 通过封装一个新的JSON-RPC包来实现对RPC层的埋点;
- 通过Spring的HandlerInterceptor[5]来实现Rest风格接口的拦截;
- 通过Spring AOP来进行Redis访问的链路采集;
- ...
这套系统支撑我们走过了业务发展最迅猛的一段时间,为大量的问题排查和故障诊断提供了一些线索,然而业务开发逐渐开始对这套系统产生不满,主要集中在以下几个方面,
1)由于我们在初期采用MySQL作为底层时序数据的存储,这在当时看起来是一个主流的方案[6],但我们碰到了很大的性能问题,毕竟MySQL这类数据库提供的存储引擎并没有对此类场景进行优化[7]。同时,MySQL并没有提供丰富的针对时间序列的查询算子。
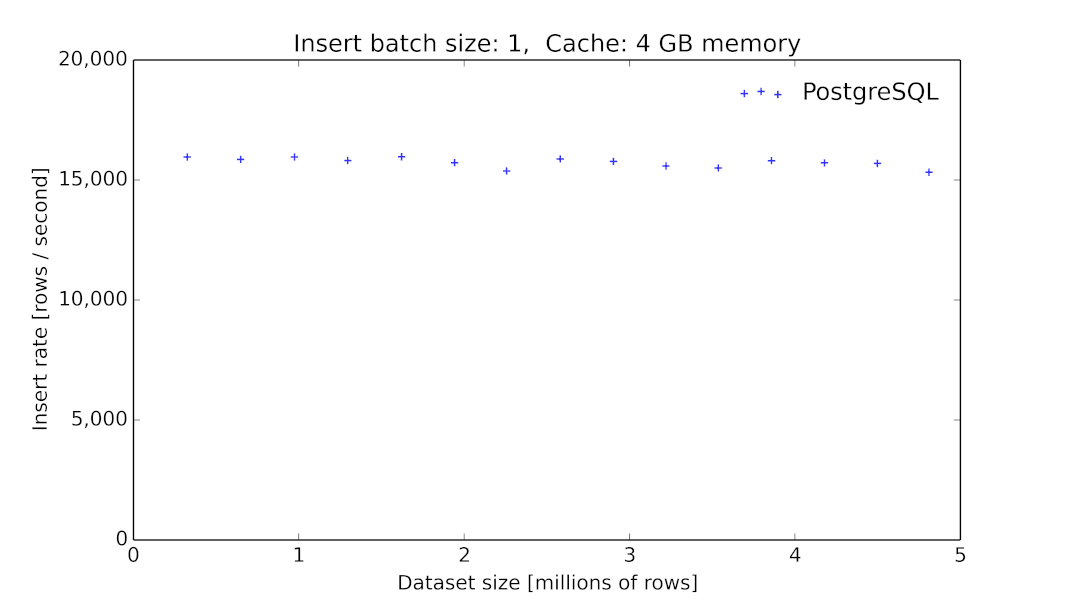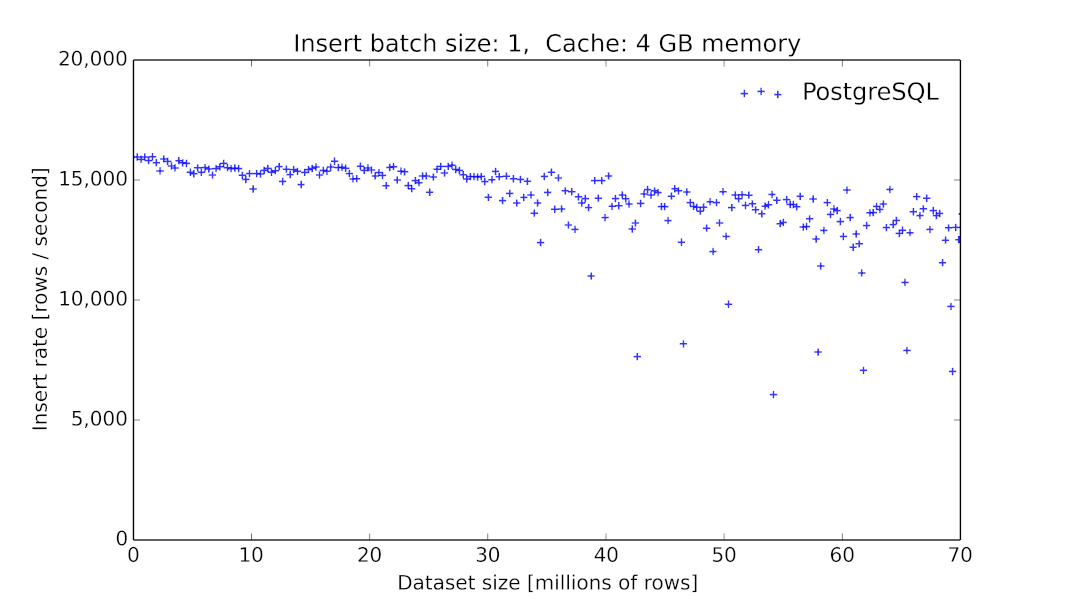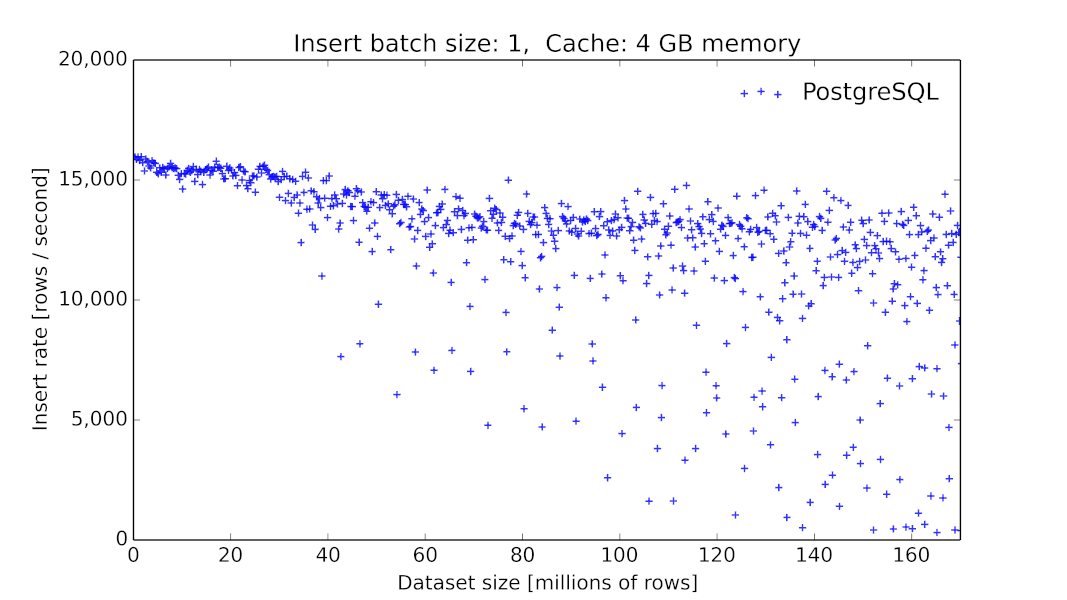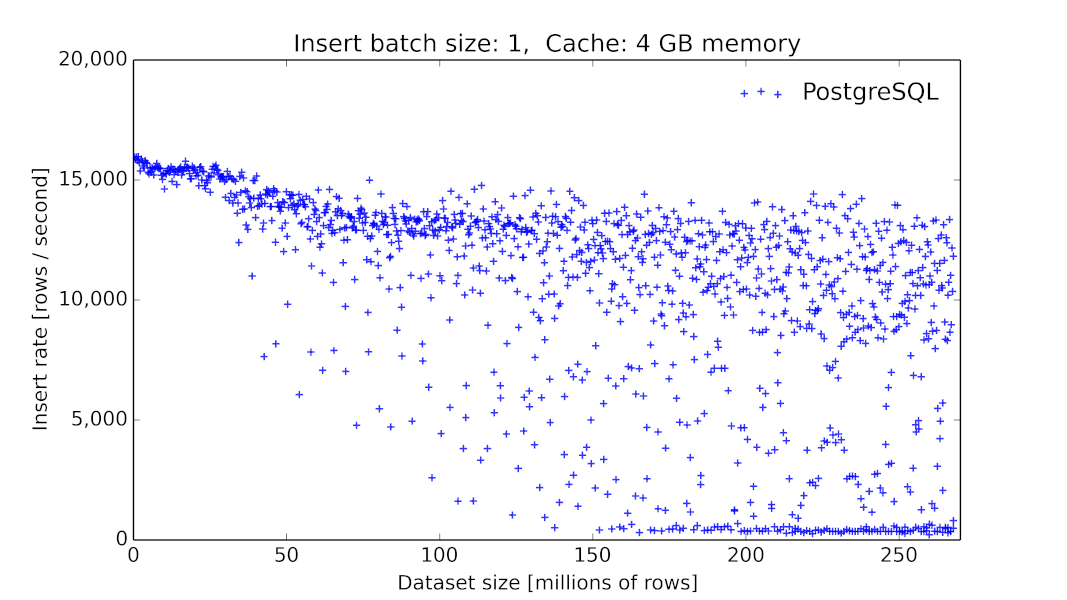
PgSQL 9.6.2 数据插入的吞吐量随着表大小的变化关系[8]。
在链路追踪或者说应用监控的场景,我们需要的是高吞吐量以及线性的性能[9],同时我们也需要增加数据的生命周期管理的功能:因为随着新数据的写入,历史数据的价值会随着时间的流逝而价值降低。
2)由于我们需要从Tracing数据反推得到指标数据Metrics,我们“魔改“了Zipkin传输部分的逻辑,对所有不采样数据(Unsampled)在客户端进行聚合以后批量上报,导致我们在Zipkin的升级方面产生了很大的困难。尤其是在https://github.com/openzipkin/zipkin/pull/1968,以后不再允许用户定制开发服务端。
3)业务方升级依赖需要采集器组件升级支持,从而产生了额外的工作量。同时,也有大量的组件难以通过这种侵入性的方式进行支持,或者需要投入很大的人力成本来进行研发、适配。
三、新一代应用监控系统 - Hera
基于以上原因,我们决定研发一套新的系统来同时满足几个条件:
- 低存储成本:能够以低成本存储较长周期的数据,对于指标能够存储至少四周,对于链路存储一周,这让我们排除了ElasticSearch这个选项;
- 高实时查询性能、高灵活度:不再使用MySQL这类关系型数据库作为时间序列的存储,使用Prometheus或Prometheus兼容的存储系统;
- 优化研发效率:使用字节码编织技术,无侵入地进行埋点,并更紧密地与DevOps流程结合。
1、链路追踪
分布式链路追踪的概念和心智模型(Mental Model)大多是受到2010年发表的Google’s Dapper论文[10]的影响。在Dapper论文中,作者明确地指出了Trace的树形结构:
We tend to think of a Dapper trace as a tree of nested RPCs.
以及提出了所谓Span的概念:
In a Dapper trace tree, the tree nodes are basic units of work which we refer to as spans. The edges indicate a casual relationship between a span and its parent span.

在一个Dapper链路树中,各个Span之间存在因果和时序关系。
在链路追踪的系统选型方面,我们对比了在当时比较活跃的几个开源项目:
- Zipkin
- Apache/Skywalking v6.6.0
- Jaeger v1.16
Jaeger是Uber[11]在2016年开源的链路追踪平台,并捐献给了CNCF云原生基金会。

Jaeger的主要组件和控制流、数据流示意图,其中使用Kafka作为缓冲管道。
Jaeger受到了开源社区的广泛支持,比如:
- Istio[12]原生支持使用Jaeger增强Service Mesh服务网格的可观测性;
- 服务网格的数据面实现Envoy[13]支持使用Jaeger作为链路追踪的服务提供方;
- ...
1)链路追踪后端系统和存储的选型
我们重点考虑的是他们对于存储系统方面的支持情况和扩展能力。
① 各个开源链路追踪实现的存储能力

Jaeger社区对于存储的扩展性极佳,提供了基于gRPC的插件机制[14],方便定制扩展。
---------------------------------- -----------------------------
| | | |
| ------------- | unix-socket | ------------- |
| | | | | | | |
| jaeger-component | grpc-client ----------------------> grpc-server | plugin-impl |
| | | | | | | |
| ------------- | | ------------- |
| | | |
---------------------------------- -----------------------------
parent process child sub-process
在存储的具体选择方面,我们在当时注意到了Aliyun SLS能够支持作为链路追踪的后端,并且官方提供了一个实现https://github.com/aliyun/aliyun-log-jaeger,我们内部基于这个思路实现了gRPC插件版本的SLS后端实现,目前稳定运行在生产环境。

- 存储周期:SLS能够提供长达30天的存储周期。
- 存储量:一天存储的Span数量超过4亿,使用约6TB存储空间。
- 性能:在SLS Query界面进行条件查询可以在3-5s以内返回结果。
- 成本:每天成本约为70元,一年约2万元左右(大约为2台8U32G的ECS的按年付费的价格)。
Jaeger operator在 https://github.com/jaegertracing/jaeger-operator/pull/1517 中引入了对gRPC插件的原生支持,gRPC插件可以作为InitContainer[15]在启动时将插件的二进制文件复制到共享的EmptyDir存储卷中。同时,我们也积极向社区反馈,向社区提供了gRPC插件的自观测功能(Self Observability):
- aeger-grpc插件支持opentracing上下文传递:https://github.com/jaegertracing/jaeger/pull/2870
- Go-plugin插件支持参数配置: https://github.com/hashicorp/go-plugin/pull/168
2)业务方接入优化
SkyWalking 的美妙不仅在于其强大的功能,还在于其优秀的代码实现[16]。
在过去我们使用侵入性的方式提供应用监控接入,监控服务的提供方需要为各个业务方提供的插件、模块,并且需要花费大量的精力来实现版本兼容性等工作,这种方式缺乏统一的切面和工作机制,需要对各个组件逐个”攻破”。Skywalking是华为的吴晟等人在2015年开源的一款APM产品,并成为Apache的顶级项目,Skywalking-Java使用了字节码增强技术,提供了无侵入性的链路埋点,大大降低了使用成本。在Java中,常用的字节码工具有以下几种。

ASM,BCEL属于Low Level,而CGLib、Javassist和ByteBuddy更易用。
对于字节码技术的具体分析可以参考StackOverflow上的回答[17]。
其中ByteBuddy的易用性和性能都达到一流的水准:

ByteBuddy官方提供的性能测试结果。
为了充分利用Skywalking-Java提供的插件,我们在OpenTracing的接口上实现了整套Skywalking链路追踪的模型。具体来说,Skywalking的链路追踪语义包括三层:
① Skywalking中的Trace与OpenTracing语义中的Trace类似
② Skywalking中的Span与OpenTracing语义中的Span类似
- EntrySpan: 等价于OpenTracing中Kind=Consumer或者Server的Span;
- ExitSpan: 等价于OpenTracing中Kind=Producer或者Client的Span;
- LocalSpan: 不属于上述两者的其他类型。
③ Skywalking增加了一层Segment的概念
一个Segment被约束在一个线程上,其中包含的所有AbstractTracingSpan 都在此线程上创建和销毁。这里SegmentID对应于OT中的SpanID,在Skywalking中的Span 是按照创建的顺序从0开始编号的。
当然模型上也有不同之处:
- 跨线程
OpenTracing的标准要求实现者将Span 设计成线程安全的,因为Span允许被跨线程传递。而在Skywalking中,跨线程是通过对当前Segment进行快照[18]实现的,而Span 在绝大部分场景下不需要保证是线程安全的。
- 异步
异步Span主要应用于记录异步操作真正的起始和结束时刻。以Spring Reactive为例[19]:用户编写的Controller返回的是一个可被执行任务(通常是Mono类型),而不是最后的结果,Dispatcher会将任务通过线程池去执行,那么我们需要记录的是真正这个请求从任务创建到被“计算“完成的整个周期。在OpenTracing标准中没有提及这部分的实现。而Skywalking的多个插件中使用了这个机制,比如Redis客户端Lettuce,Spring Webflux,Apache AsyncHttpClient等。
我们通过在OpenTracing接口上实现与Skywalking一致的语义从而实现几乎零成本地移植并使用它所有的插件。我们在使用Skywalking-Java的过程中也发现了不少问题,也与社区积极地反馈,做出了一些贡献,主要包括:
- JSON日志格式的实现:https://github.com/apache/skywalking/pull/5357
- Spring Kafka 1.x插件:https://github.com/apache/skywalking/pull/5879
- Spring DevTools支持和多类加载器优化:https://github.com/apache/skywalking/pull/6973
- Jedis Transaction支持:https://github.com/apache/skywalking-java/pull/57
3)服务依赖分析
服务的依赖分析在公司内部一直是业务开发迫切需要的功能,它在服务容量规划、问题诊断和服务强弱性依赖判断中都有比较实用的价值。在Jeager社区的实现中,推荐生产使用Spark批处理[20]的方式实现了全局的依赖分析,也有基于Flink的实时处理[21],但已经没有在维护状态。
为了实现这个功能,我们使用了Apache Flink,通过消费Kafka中的链路数据,实时计算出服务之间的依赖关系,将Tuple<downsampled timestamp, caller, sub-caller, callee, sub-callee> 格式的数据通过OpenTSDB协议传输到我们的时序数据库VictoriaMetrics 。
前端根据用户提供的时间窗口,通过Java服务暴露的API进行上游/下游的查询:

后续我们将在用户交互和调用量的分析展示方面进行进一步的优化。
2、指标监控
在老版本的监控程序中,我们使用了关系型数据库作为时序数据的存储系统,使得我们在查询的灵活性和性能方面遭遇到了很大的瓶颈,我们有必要在新系统设计的时候去进行一定的反思。在过去几年中,云原生的概念逐渐深入人心,而Prometheus是云原生时代监控的事实标准。

在进行了一些调研之后,我们认为单机版本的Prometheus并不能支撑超过百万级别活跃的指标和超过一周的数据存储。我们的目光主要聚焦到了Thanos、Cortex和VictoriaMetrics,在国内技术社区分享比较多的是Cortex和Thanos,但我们对比发现Cortex的架构非常复杂,对系统运维提出了新的挑战,而Thanos也有一定的运维复杂性,且由于使用对象存储(S3等)作为冷数据存储,查询可能存在一部分服务不可用导致返回部分数据。同时,我们也发现国内的知乎在QCon 2020[22]上分享了他们使用VictoriaMetrics的经验。我们基于以下原因最终选择了VictoriaMetrics。
- VictoriaMetrics在各项性能测试[23]中都表现卓著;
- 作者Aliaksandr Valialkin精于Go语言的性能优化,是fasthttp等高性能Go语言组件的作者;
- 最重要的是VM的集群架构简单,易于运维。

VM的各个组件都是独立的,可以水平扩展,只有核心的vmstorage是有状态的,其他组件均是无状态的。
1)推还是拉 (push or pull)
对于指标类的数据,采用主动推还是被动拉的模式,一直以来都是存在较大的争议[24]。我们与Prometheus一样使用推的模式,基于以下原因,
- 服务发现
一个诟病Pull模式的原因是认为Pull模式需要大规模的服务发现,但这一问题在Kubernetes上反而不存在任何问题,我们借助CRD[25]可以很轻易地实现服务抓取目标的定义。同时可以将Pod,Service上的标签附加到指标上,帮助查询的时候区分实例,服务所属的业务团队等。反而,这在Push模式中是不容易实现,或者需要业务研发去改造的。
- 问题排查
当指标查询失败的时候,我们通常需要去判断到底是哪一步出了问题。在Push模式中,我们需要去检查业务的代码和日志来判断问题。然而在Pull模式,我们可以手动在浏览器中去请求指标暴露的接口(比如/metrics )就可以判断服务的健康状况,业务是否正常导出指标。
目前我们使用VictoriaMetrics的一些统计信息:
- 存储周期60天,共有6990亿个数据点,占用磁盘空间800GB;
- 活跃时间序列约500万,数据点插入的QPS约13万每秒;
- 范围查询的P99线平均值约为1.5s。
我们也自研了查询面板,以限定查询的时间范围(最长3天)和查询的模式(针对服务job查询)。

我们自研了一些重要的指标插件,其中在应用性能分析、故障定位中比较实用的维度有:
- Servlet容器指标:Tomcat忙碌线程数,百分比;
- 数据库连接池指标:支持HikariCP和Alibaba/Druid连接池,等待连接池的线程数,数据库连接获取时间,数据库连接池使用占比;
- 缓存指标:支持Redis,Caffeine和EhCache。缓存命中率;
- Kubernetes监控:Pod CPU、内存使用量,我们也在系统中也集成了Kubernetes事件的查看和搜索。
由于公司部分核心服务还使用Docker部署在ECS上,我们在VictoriaMetrics中实现了基于Dockerd API的服务发现机制[26],也已经合并到社区版本。
3、全面拥抱云原生
在2020年,Kubernetes已然成为了分布式操作系统的事实标准,公司内部的绝大多数服务也已经全面迁移到自建的Kubernetes集群。为了更好的利用新特性,我们在2020年中启动Kubernetes的集群升级计划,将集群升级到1.16版本(目前已经升级到1.20),并迁移至阿里云的ACK托管集群。监控系统的落地将全面依赖于Kubernetes系统。
1)我们提供Docker镜像版本的Java Agent,方便业务开发接入。
2)在生产环境,我们使用InitContainer[27]在容器启动阶段注入Java Agent,两者之间通过贡献的EmptyDir[28]来传递Agent Jar包。这便于我们在生产环境中静默升级Agent版本:即使Agent在生产出现问题,我们可以快速修复问题,然后升级初始化容器即可。
3)时序数据库VictoriaMetrics的运维和Jaeger组件的运维也是通过Kubernetes operator实现的:
- 我们对jaeger-ingester和jaeger-collector组件启用了HPA,即基于CPU和内存使用率的水平动态扩容。
- VictoriaMetrics集群版本的各个组件也是通过Kubernetes operator[29]进行维护的。
四、展望
1、后采样的实现
由于我们目前采样的是头采样(Head-Based Sampling)方案,一旦在链路中间的服务发生抛出异常且这条链路没有被采样,那么就会出现有错误日志和报警,但链路追踪系统无法查询到这条链路的情况,这给开发排查问题带来很大的阻碍。目前,业界有几种典型的实现方案,
1)OpenTelemetry方案
https://github.com/open-telemetry/opentelemetry-collector-contrib/pull/4958
OT社区的tailsampling方案[30]主要来自于Grafana公司的贡献[31],同时可以利用以下几个processor和exporter实现高伸缩性。
- (第一层)loadbalancingexporter:把属于同一个TraceID的所有Trace和Log分发给一组固定的下游Collector;
- groupbytraceprocessor:等待足够长的一段时间,将属于一个TraceID的所有Span(s)打包传递到下游;
- tailsamplingprocessor:通过预定义的组合策略进行采样。
2)字节跳动方案
发生错误的服务将采样决定强制进行翻转,如果这条链路没有进行采样的话。但这样的话会丢失采样决策改变之前的所有链路以及其他分支链路的数据。

3)货拉拉方案
基于Kafka延迟消费 布隆过滤器实现:

- 实时消费队列:根据采样规则写入Bloom过滤器,热数据全量写入热存储。
- 延迟消费队列:根据Bloom过滤器实现条件过滤逻辑,冷数据写入冷存储。
2、时间序列的异常检测
时间序列的异常检测一直是一个比较火的话题,尤其是针对具有时间周期特征的数据。
1)Gitlab方案
Gitlab在2019年分享了他们基于Prometheus实现的简单的异常检测[32],比如我们想判断 t 当前时间对应的值 f (t) ,我们可以根据前三周的数据的中位数通过最近一周的增量进行修正,得到当前时间的预测值 f ' (t)。

其中增量 ∆offset 是指最近一周的指标的时间平均值与往前偏移offset 以后的时间平均值,比如 ∆1w 是指最近一周的平均值与上一个周期的平均值之差(用PromQL表示为job:http_requests:rate5m:avg_over_time_1w - job:http_requests:rate5m:avg_over_time_1w offset 1w),用于补偿周期之间的平均值变化。
3)其他的方案
- Prophet - 携程实时智能异常检测平台实践[33]
- 外卖订单量预测异常报警模型实践[34]
从业界发展的大势来看,通过大数据、AI手段对系统异常进行检测也是大势所趋。
>>>>
参考资料
- [1]Observability
- https://en.wikipedia.org/wiki/Observability
- [2]Metrics, tracing, and logging
- https://peter.bourgon.org/blog/2017/02/21/metrics-tracing-and-logging.html
- [3]Zipkin
- https://zipkin.io/,
- [4]Using the Connector/J Interceptor Classes
- https://dev.mysql.com/doc/connector-j/8.0/en/connector-j-interceptors.html
- [5]HandlerInterceptor
- https://docs.spring.io/spring-framework/docs/current/javadoc-api/org/springframework/web/servlet/HandlerInterceptor.html
- [6]What Database Engine Are You Using to Store Time Series Data?
- https://www.percona.com/blog/2017/02/10/percona-blog-poll-database-engine-using-store-time-series-data/
- [7]Time-series data: Why (and how) to use a relational database instead of NoSQL
- https://www.timescale.com/blog/time-series-data-why-and-how-to-use-a-relational-database-instead-of-nosql-d0cd6975e87c/
- [8]Time-series data: Why (and how) to use a relational database instead of NoSQL
- https://www.timescale.com/blog/time-series-data-why-and-how-to-use-a-relational-database-instead-of-nosql-d0cd6975e87c/
- [9]面向分布式追踪系统的存储方案https://mp.weixin.qq.com/s/wostd5_PdG9X-qpitPdA7A
- [10]Dapper, a Large-Scale Distributed Systems Tracing Infrastructure
- https://research.google/pubs/pub36356/
- [11]Evolving Distributed Tracing at Uber Engineering
- https://eng.uber.com/distributed-tracing/
- [12]Istio/Jaeger
- https://istio.io/latest/docs/tasks/observability/distributed-tracing/jaeger/
- [13]Jaeger tracing
- https://www.envoyproxy.io/docs/envoy/latest/start/sandboxes/jaeger_tracing.html
- [14]Golang plugin system over RPC
- https://github.com/hashicorp/go-plugin
- [15]Init Containers
- https://kubernetes.io/docs/concepts/workloads/pods/init-containers/
- [16]SkyWalking 8.7.0 源码分析
- https://skywalking.apache.org/zh/2022-03-25-skywalking-source-code-analyzation/
- [17]Dynamic Java Bytecode Manipulation Framework Comparison
- https://stackoverflow.com/questions/9167436/dynamic-java-bytecode-manipulation-framework-comparison
- [18]ContextSnapshot
- https://github.com/apache/skywalking-java/blob/5607f87a54719baad002cb00248e250cbdaae69a/apm-sniffer/apm-agent-core/src/main/java/org/apache/skywalking/apm/agent/core/context/AbstractTracerContext.java#L42-L56
- [19]Understanding Reactive types
- https://spring.io/blog/2016/04/19/understanding-reactive-types
- [20]Spark job for dependency links
- https://github.com/jaegertracing/spark-dependencies
- [21]Big data analytics for Jaeger using Apache Flink
- https://github.com/jaegertracing/jaeger-analytics-flink
- [22]演讲:单机 20 亿指标,知乎 Graphite 极致优化!https://qcon.infoq.cn/2020/shenzhen/presentation/2881
- [23]Prominent features
- https://docs.victoriametrics.com/Single-server-VictoriaMetrics.html#prominent-features
- [24]Pull doesn't scale - or does it?https://prometheus.io/blog/2016/07/23/pull-does-not-scale-or-does-it/
- [25]VMServiceScrape
- https://docs.victoriametrics.com/operator/api.html#vmservicescrape
- [26]Support Docker ServiceDiscovery
- https://github.com/VictoriaMetrics/VictoriaMetrics/pull/1402
- [27]InitContainer
- https://kubernetes.io/docs/concepts/workloads/pods/init-containers/
- [28]EmptyDir
- https://kubernetes.io/docs/concepts/storage/volumes/#emptydir
- [29]Kubernetes operator for Victoria Metrics
- https://github.com/VictoriaMetrics/operator
- [30]Tail-Based Sampling - Scalability Issues
- https://github.com/open-telemetry/opentelemetry-collector-contrib/issues/4758
- [31]Public - Composite Tail Sampling Policy
- https://docs.google.com/document/d/10wpIv3TtXgOik05smHm3nYeBX48Bj76TCMxPy8e1NZw/edit#heading=h.ecy5l2puwtp4
- [32]How to use Prometheus for anomaly detection in GitLab
- https://about.gitlab.com/blog/2019/07/23/anomaly-detection-using-prometheus/
- [33]携程实时智能检测平台建设实践
- https://developer.aliyun.com/article/740900
- [34]外卖订单量预测异常报警模型实践
- https://tech.meituan.com/2017/04/21/order-holtwinter.html
作者丨陆家靖
来源丨公众号:SQB Blog(ID:gh_9916f2313b7a)
dbaplus社群欢迎广大技术人员投稿,投稿邮箱:editor@dbaplus.cn
更多精彩内容
dbaplus社群最新一期直播【话题接力丨智能运维AIOps难落地呼声极高,如何破局?】将于9月16日晚8点开播,dbaplus社群邀请到京东科技 智能运维算法负责人-张静、蚂蚁集团 AIOps技术专家-徐新龙在云上汇聚,希望通过汇集两位运维专家的研究成果和实践积累,给大家进一步明确智能运维发展的方向,提供可参考、可落地的智能运维实战经验。
直播地址:http://z-mz.cn/5lIbo

关于我们
dbaplus社群是围绕Database、BigData、AIOps的企业级专业社群。资深大咖、技术干货,每天精品原创文章推送,每周线上技术分享,每月线下技术沙龙,每季度Gdevops&DAMS行业大会。
关注公众号【dbaplus社群】,获取更多原创技术文章和精选工具下载
,




