随着CPU架构的发展,工艺的升级,带来性能提升,能效的提升(同性能下)。但是由于极限性能的增加,也带来了peak功耗的增加(大部分情况下,能效比的提升无法抵消这部分),CPU功耗优化一直是广大SOC厂商比较头疼的问题。
CPU功耗分为静态功耗和动态功耗:
- 静态功耗(static power):mos管内部的PN节产生的泄漏电流,只要当前单元被上电就会有,静态功耗主要与温度和电压有关。
- 动态功耗(dynamic power):芯片电路中的负载电容充放电造成,只要电路中有信号翻转就会产生动态功耗,动态功耗主要与频率和电压有关。其公式大体如下:

假设一个SOC有两个cluster,每个cluster有4个CPU,单个cluster的总功耗由cluster独有的模块(例如L3 cache)功耗与CPU的功耗两部分构成,单个cluster功耗构成如图1:

CPU LPM(Low power mode)状态即C states分为三种状态C0,C1和C4, 以qcom某款芯片为例:
- C0为正常的active状态。
- C1为WFI(wait for interrupt)模式,等到有中断的时候从C1迁移至C0状态。C1模式下会关闭core clock,此时动态功耗会变得非常低,退出延迟为40ns。
- C4会在C1的基础上关闭core logic以及L1/L2cache,退出延迟为500ns左右。
当CPU无任务运行时,idle状态下会进入低功耗模式节省功耗,此时CPU上仅存在静态功耗,假如CPU进入C1状态,其状态切换对整体功耗的影响如图2:

假设系统中只有CPU0和CPU1,可以看到当CPU0和CPU1被唤醒,CPU整体功耗会增加cluster,CPU0和CPU1的static power以及dynamic power,如果CPU0进入WFI模式,则CPU0的dynamic power消失,如果CPU0 power down,则CPU0的static power也会消失,CPU1亦然。
现在主流的SOC处理器以8核为主,这8个核会被分为2~3个cluster。

如果软件把某个CPU设置为“隔离状态“,使得任务在调度时,不能选择这个CPU,那么这个CPU会因为没有任务运行,很快进入低功耗模式,从而达到节省功耗的目的。在有性能需求的时候能够以较低的延迟唤醒这些idle的CPU,快速的满足性能的需求。达到性能与功耗的平衡。下面我们介绍本文的“主角“—core control。
二、core control框架与原理core control最早是由高通开发的一种动态调核技术。在早期的高通骁龙平台上有一个模块叫作mpdecision(用户态模块), 其主要作用是监控每个CPU的运行负载,在性能需求较低的时候,通过hotplug的方式来关闭某些不必要的CPU核心,达到省电的目的。
随着android系统及生态的发展,热插拔的高延迟无法满足软件的需求,随之衍生出来了corectl。其相比mpdecision存在如下几个优点:
1)corectl为内核模块,可以快速的监控CPU的相关信息(频率、任务等等), mpdecision为用户态模块,其响应较慢
2) corectl通过isolate的方式来隔离核,相比mpdecision的热插拔,isolation的方式的时间延迟在50~500ns,而hotplug则需要100ms 的时间才能完全ready。
3)corectl作为内核模块,可以有效的跟调度器、调频器相结合。
上面主要介绍了CPU功耗的一些基础知识,初步描述了core control省功耗的基本思路,下面讲述core control基本原理。
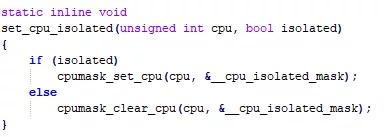
1. core control基本框架首先我们需要了解core isolation的概念。我们在CPU空闲时,对某些能耗较高的CPU进行隔离,不让task在选核时选择被隔离的CPU,使其尽快进入idle状态,而在需要CPU能力的时候,只需要放开CPU隔离即可让CPU正常参与调度。CPU isolation实际上最终只是通过cpumask设置了cpu_isolated_mask的值,如图4。
core control通过实时监控当前CPU的loading来进行判断当前CPU是否需要增加和减少CPU core,其基本框架如图5:

core control整体逻辑比较简单,作为一个kernel模块,每个schedule tick(4ms)会起来check一次CPU整体负载状况,如果需要做isolate/unisolate会唤醒corectl thread来完成操作。userspace修改相应的参数也会唤醒corectl线程起来做isolate/unisolate core操作。corectl向外提供了三个接口:
1)scheduler进行update task loading时会check是否需要进行core isolation,API为core_ctl_check。
2)kernel其他模块可以通过API core_ctl_set_boost,保持当前所有的core都处于unisolate状态。
3)core control提供了丰富的sys节点用于userspace进行参数的修改。
另外,corectl还提供了notifier接口给msm_performance模块,用来在每次进行corectl check时更新系统task相关状态。
2. core control基本原理core control的核心逻辑是核数的控制,如何判断当前需要多少CPU呢?其核心逻辑在eval_need函数中。
决定cluster cpu核数主要有两个因素:CPU的loading和CPU上task 的数量。
首先看CPU loading如何决定核数,见下图6:

corectl每一轮会以cluster为单位check当前cluster满足负载要求需要多少CPU。need_cpus表示cluster最终计算需要的核数,每次check会从0开始计算,根据各个CPU的loading状态来确定是否需要增加CPU个数。CPU loading的统计方法是:当前CPU上runqueue的task loading值之和除以当前CPU理论最高的算力值,得到最终的CPU loading,具体如下图7:
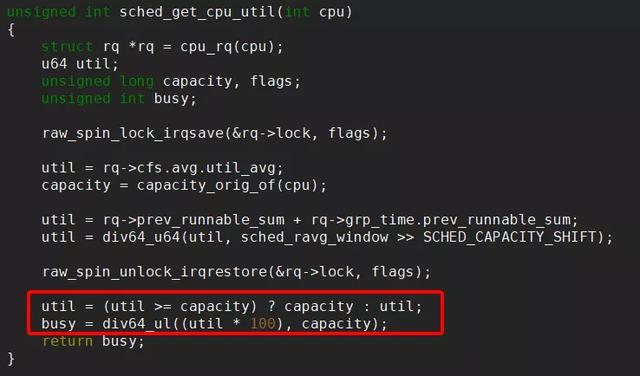
在上面根据CPU loading得到一个初步的need cpus值后,为了避免出现性能问题,还需要从runqueue task数的角度来看是否需要增加CPU数,其判断逻辑如下图8:

先说明一下上面函数中各个参数的含义:
nrrun: 当前cluster总共需要执行的task数。计算方法:当前cluster上所有CPU runqueue task之和再加上prev cluster上的misfit task(task util超过prev cluster最高capacity 90%的task)数。
nr_prev_assist: prev cluster总共有多少task需要当前cluster帮忙执行。计算方法:prev cluster cpu runqueue的总task数加上prev prev cluster的misfit task数再减去prev cluster中实际active的CPU数。
new_need: 当前最新得出的现在所需CPU个数值。
max_nr:当前cluster中CPU runqueue中task数最大值。
strict_nrrun:当前cluster过去一段时间平均的running task个数,计算方法:小核只统计总的平均task数,大核则需要将平均的running task数减掉active cpu个数。这样做的目的是如果小核有enable corectl功能,则需要小核开核的条件尽可能的宽松。
1)如果当前cluster上需要运行的task过多,大于设定的阈值,需要打开cluster所有CPU。
2)如果prev cluster需要当前cluster帮忙运行的task数超过阈值,则当前cluster需要开启nr_prev_assist个CPU。
3)当前cluster需要run的task数如果小于设定阈值,但是大于new_need值,则认为当前cluster所开的CPU数不够,需要增加一个。
4)如果当前cluster中有一个CPU runqueue的task数大于4个,则说明当前CPU loading过重,需要再开一个CPU来保证运行流畅。
5)new_need的值必须大于等于当前cluster平均的running task数,由于计算方法的差别,对于小核,尽可能的让所有core都打开。
6)最终need_cpus的个数必须小于等于cluster最大的CPU数,也必须满足设定的cluster min_cpus/max_cpus的值。
(2)core control sysfs相关节点
sysfs节点主要提供给userspace用来设定参数,userspace可以通过节点设置每个cluster min_cpus(最少)/max_cpus(最多)开启的cpu个数,在CPU loading不高时,cluster只需开启min_cpus个cpu,再根据CPU loading,动态开关CPU,最多可以开启max_cpus个cpu。也可以根据需要,通过节点busy_up_thresh/busy_down_thresh以及task_thresh从task loading或者数量的角度设定cluster开关CPU的难度。
,




