这段时间刚好正在做软件安全的实验和课设,学习了各种加密算法,比如对称加密算法的DES,AES;非对称加密算法的RSA;再如今天要讲的主角-单向加密算法的MD5。为什么这么多算法,MD5成为了今天的猪脚呢?,这是因为个人感觉在目前Android开发中MD5算是比较常用的,所以很值得一讲。所以今天让我带你们来全面认识我们的主角MD5。
一、基本概念
1. 单向加密算法
在介绍MD5算法前,很有必要解释一下单向加密算法。单向加密,人如其名,就是只能单向对明文进行加密,而不能逆向通过密文得到明文。该算法在加密过程中,在得到明文后,经过加密算法得到密文,不需要使用密钥。因为没有密钥,所以就无法通过密文得到明文。
2. MD5算法
MD5,全称Message Digest Algorithm 5,翻译过来就是消息摘要算法第5版,是计算机安全领域广泛使用的一种散列函数,用于确保信息传输的完整性。MD5算法是由MD2、MD3、MD4演变而来,是一种单向加密算法,一种不可逆的加密方式。
二、特点
1.长度固定
不过多长的数据,经过MD5加密后其MD5值长度都是固定的。MD5值长度固定为128位,而最后的值一般都用16进制数字表示,一个16进制数字占4位,所以最后的MD5值都是用32个16进制数字表示。
2.计算简单
MD5算法说到底还是散列算法,或者叫做哈希算法,所以计算一个数据的MD5值是比较容易的,同时加密速度也是很快的。
3.抗修改性
对原数据进行任何改动,哪怕只是修改1个字节,所得到的MD5值都有很大的区别。
4.强抗碰撞性
已知原数据和其MD5值,很难找到具有相同MD5值的数据,即很难伪造数据。这里的碰撞在后面的安全性中会提到,在这里我们简单理解为一种破解手段。
三、原理
1.填充数据
首先计算数据长度(bit)对512求余的结果,如果不等于448,就需要填充数据使得数据长度对512求余的结果为448,其填充方式为第一位填充1,其余位填充0.填充后数据长度为512*N 448。
2.记录数据长度
用64位来存储填充前数据的长度,这64位将加在填充后数据的后面,这样最终的数据长度为512*N 448 64=(N 1)*512
3.装入标准幻数
标准幻数其实就是4个整数,我们知道最终的MD5值长度为128位,按32位分成一组的话可以分成4组,而这4组结果就是由这4个标准幻数A,B,C,D经过不断演变得到。在MD5官方的实现中,四个幻数为(16进制):
A=01234567 B=89ABCDEF C=FEDCBA98 D=76543210
其实上面是大端字节序的幻数,而在正常程序中,我们实现的是小端字节序,所以在程序中我们定义的幻数应该是:
A=0X67452301 B=0XEFCDAB89 C=0X98BADCFE D=0X10325476
4.四轮循环运算
在上面对数据处理后,数据长度将是(N 1)/512,我们将每512位(64字节)作为一块,总共要循环N 1次,并将块细分为16个小组,每组的长度为32位(4字节),这16个小组即为一轮,总共得循环4轮,即64次循环。总的来说我们需要(N 1)个主循环,每个主循环包含了64次子循环,来不断的改变幻数A,B,C,D才能最终得到数据的MD5值。
4.1 相关系数说明
1)4个非线性函数
- F(x,y,z)=(x&y)|((~x)&z)
- G(x,y,z)=(x&z)|(y&(~z))
- H(x,y,z)=x^y^z
- I(x,y,z)=y^(x|(~z))
在4轮循环中,F,G,H,I会交替使用,第一轮使用F,第二轮使用G,第三轮使用H,第四轮使用I。即每隔16次循环会换一个函数。
2)Mi
将每一块512位分成16等分,命名为M0~M15,每一等份长度为32位16次循环中,交替使用
3) Kj
常量数组,在64子循环中用到的常量都是不同的
4) s
左移量,每轮循环用的S各不相同,每轮总共有4个左移量,每4次循环为一周期
4.2 核心公式
总共有四个核心公式,与4个非线性函数一一对应,即每轮使用的核心公式里的公式有差异。
- FF(a,b,c,d,Mi,s,Kj) :表示b ((a F(b,c,d) Mi Kj)<<<s)
- GG(a,b,c,d,Mi,s,Kj) :表示b ((a G(b,c,d) Mi Kj)<<<s)
- HH(a,b,c,d,Mi,s,Kj) :表示b ((a H(b,c,d) Mi Kj)<<<s)
- II(a,b,c,d,Mi,s,Kj) :表示b ((a I(b,c,d) Mi Kj)<<<s)
四、算法实现
public class MD5 { //16进制数字 private static final String[] hexes = {"0", "1", "2", "3", "4", "5", "6", "7", "8", "9", "a", "b", "c", "d", "e", "f"}; //标准的幻数 private static final long A = 0X67452301; private static final long B = 0XEFCDAB89; private static final long C = 0X98BADCFE; private static final long D = 0X10325476; //位移量s,行为轮,总共有4轮,列为每轮中的一次循环,总共16次 //下面这些S11-S44实际上是一个4*4的矩阵,在四轮循环运算中用到 private static final int S11 = 7; private static final int S12 = 12; private static final int S13 = 17; private static final int S14 = 22; private static final int S21 = 5; private static final int S22 = 9; private static final int S23 = 14; private static final int S24 = 20; private static final int S31 = 4; private static final int S32 = 11; private static final int S33 = 16; private static final int S34 = 23; private static final int S41 = 6; private static final int S42 = 10; private static final int S43 = 15; private static final int S44 = 21; //结果,共4*32=128位,初始值为幻数 private long[] result = {A, B, C, D}; /** * 计算字符串数据的MD5值并返回 * * @param src 数据 * @return 返回数据的MD5值 */ public String digest(String src) { byte[] inputbytes = src.getBytes(); int byteLen = inputBytes.length;//长度(字节) //完整分组的个数 int groupCount = byteLen / 64;//每组512位(64字节) long[] group;//每个小组(64字节)再细分后的16个小组(4字节) //处理每一个完整分组 for (int step = 0; step < groupCount; step ) { group = divGroup(inputBytes, step * 64); trans(group);//处理分组,核心算法 } //处理完整分组后的尾巴 int rest = byteLen % 64;//512位分组后的余数 byte[] tempBytes = new byte[64]; //56个字节即488 if (rest <= 56) { for (int i = 0; i < rest; i ) tempBytes[i] = inputBytes[byteLen - rest i]; //不断填充 if (rest < 56) { //最高位填充1 tempBytes[rest] = (byte) (1 << 7); //其余位填充0 for (int i = 1; i < 56 - rest; i ) tempBytes[rest i] = 0; } long len = (long) (byteLen << 3); for (int i = 0; i < 8; i ) { tempBytes[56 i] = (byte) (len & 0xFFL); len = len >> 8; } group = divGroup(tempBytes, 0); trans(group);//处理分组 } else { for (int i = 0; i < rest; i ) tempBytes[i] = inputBytes[byteLen - rest i]; tempBytes[rest] = (byte) (1 << 7); for (int i = rest 1; i < 64; i ) tempBytes[i] = 0; group = divGroup(tempBytes, 0); trans(group);//处理分组 for (int i = 0; i < 56; i ) tempBytes[i] = 0; long len = (long) (byteLen << 3); for (int i = 0; i < 8; i ) { tempBytes[56 i] = (byte) (len & 0xFFL); len = len >> 8; } group = divGroup(tempBytes, 0); trans(group);//处理分组 } //将Hash值转换成十六进制的字符串 String resStr = ""; long temp; for (int i = 0; i < 4; i ) { for (int j = 0; j < 4; j ) { temp = result[i] & 0x0FL; String a = hexes[(int) (temp)]; result[i] = result[i] >> 4; temp = result[i] & 0x0FL; resStr = hexes[(int) (temp)] a; result[i] = result[i] >> 4; } } return resStr; } /** * 从inputBytes的index开始取512位,作为新的分组 * 将每一个512位的分组再细分成16个小组,每个小组32位(8个字节) * * @param inputBytes * @param index * @return M */ private static long[] divGroup(byte[] inputBytes, int index) { long[] temp = new long[16]; for (int i = 0; i < 16; i ) { temp[i] = b2iu(inputBytes[4 * i index]) | (b2iu(inputBytes[4 * i 1 index])) << 8 | (b2iu(inputBytes[4 * i 2 index])) << 16 | (b2iu(inputBytes[4 * i 3 index])) << 24; } return temp; } /** * 这时不存在符号位(符号位存储不再是代表正负),所以需要处理一下 */ private static long b2iu(byte b) { return b < 0 ? b & 0x7F 128 : b; } /** * 主要的操作,四轮循环 * @param groups--每一个分组512位(64字节) */ private void trans(long[] groups) { long a = result[0], b = result[1], c = result[2], d = result[3]; /*第一轮*/ a = FF(a, b, c, d, groups[0], S11, 0xd76aa478L); /* 1 */ d = FF(d, a, b, c, groups[1], S12, 0xe8c7b756L); /* 2 */ c = FF(c, d, a, b, groups[2], S13, 0x242070dbL); /* 3 */ b = FF(b, c, d, a, groups[3], S14, 0xc1bdceeeL); /* 4 */ a = FF(a, b, c, d, groups[4], S11, 0xf57c0fafL); /* 5 */ d = FF(d, a, b, c, groups[5], S12, 0x4787c62aL); /* 6 */ c = FF(c, d, a, b, groups[6], S13, 0xa8304613L); /* 7 */ b = FF(b, c, d, a, groups[7], S14, 0xfd469501L); /* 8 */ a = FF(a, b, c, d, groups[8], S11, 0x698098d8L); /* 9 */ d = FF(d, a, b, c, groups[9], S12, 0x8b44f7afL); /* 10 */ c = FF(c, d, a, b, groups[10], S13, 0xffff5bb1L); /* 11 */ b = FF(b, c, d, a, groups[11], S14, 0x895cd7beL); /* 12 */ a = FF(a, b, c, d, groups[12], S11, 0x6b901122L); /* 13 */ d = FF(d, a, b, c, groups[13], S12, 0xfd987193L); /* 14 */ c = FF(c, d, a, b, groups[14], S13, 0xa679438eL); /* 15 */ b = FF(b, c, d, a, groups[15], S14, 0x49b40821L); /* 16 */ /*第二轮*/ a = GG(a, b, c, d, groups[1], S21, 0xf61e2562L); /* 17 */ d = GG(d, a, b, c, groups[6], S22, 0xc040b340L); /* 18 */ c = GG(c, d, a, b, groups[11], S23, 0x265e5a51L); /* 19 */ b = GG(b, c, d, a, groups[0], S24, 0xe9b6c7aaL); /* 20 */ a = GG(a, b, c, d, groups[5], S21, 0xd62f105dL); /* 21 */ d = GG(d, a, b, c, groups[10], S22, 0x2441453L); /* 22 */ c = GG(c, d, a, b, groups[15], S23, 0xd8a1e681L); /* 23 */ b = GG(b, c, d, a, groups[4], S24, 0xe7d3fbc8L); /* 24 */ a = GG(a, b, c, d, groups[9], S21, 0x21e1cde6L); /* 25 */ d = GG(d, a, b, c, groups[14], S22, 0xc33707d6L); /* 26 */ c = GG(c, d, a, b, groups[3], S23, 0xf4d50d87L); /* 27 */ b = GG(b, c, d, a, groups[8], S24, 0x455a14edL); /* 28 */ a = GG(a, b, c, d, groups[13], S21, 0xa9e3e905L); /* 29 */ d = GG(d, a, b, c, groups[2], S22, 0xfcefa3f8L); /* 30 */ c = GG(c, d, a, b, groups[7], S23, 0x676f02d9L); /* 31 */ b = GG(b, c, d, a, groups[12], S24, 0x8d2a4c8aL); /* 32 */ /*第三轮*/ a = HH(a, b, c, d, groups[5], S31, 0xfffa3942L); /* 33 */ d = HH(d, a, b, c, groups[8], S32, 0x8771f681L); /* 34 */ c = HH(c, d, a, b, groups[11], S33, 0x6d9d6122L); /* 35 */ b = HH(b, c, d, a, groups[14], S34, 0xfde5380cL); /* 36 */ a = HH(a, b, c, d, groups[1], S31, 0xa4beea44L); /* 37 */ d = HH(d, a, b, c, groups[4], S32, 0x4bdecfa9L); /* 38 */ c = HH(c, d, a, b, groups[7], S33, 0xf6bb4b60L); /* 39 */ b = HH(b, c, d, a, groups[10], S34, 0xbebfbc70L); /* 40 */ a = HH(a, b, c, d, groups[13], S31, 0x289b7ec6L); /* 41 */ d = HH(d, a, b, c, groups[0], S32, 0xeaa127faL); /* 42 */ c = HH(c, d, a, b, groups[3], S33, 0xd4ef3085L); /* 43 */ b = HH(b, c, d, a, groups[6], S34, 0x4881d05L); /* 44 */ a = HH(a, b, c, d, groups[9], S31, 0xd9d4d039L); /* 45 */ d = HH(d, a, b, c, groups[12], S32, 0xe6db99e5L); /* 46 */ c = HH(c, d, a, b, groups[15], S33, 0x1fa27cf8L); /* 47 */ b = HH(b, c, d, a, groups[2], S34, 0xc4ac5665L); /* 48 */ /*第四轮*/ a = II(a, b, c, d, groups[0], S41, 0xf4292244L); /* 49 */ d = II(d, a, b, c, groups[7], S42, 0x432aff97L); /* 50 */ c = II(c, d, a, b, groups[14], S43, 0xab9423a7L); /* 51 */ b = II(b, c, d, a, groups[5], S44, 0xfc93a039L); /* 52 */ a = II(a, b, c, d, groups[12], S41, 0x655b59c3L); /* 53 */ d = II(d, a, b, c, groups[3], S42, 0x8f0ccc92L); /* 54 */ c = II(c, d, a, b, groups[10], S43, 0xffeff47dL); /* 55 */ b = II(b, c, d, a, groups[1], S44, 0x85845dd1L); /* 56 */ a = II(a, b, c, d, groups[8], S41, 0x6fa87e4fL); /* 57 */ d = II(d, a, b, c, groups[15], S42, 0xfe2ce6e0L); /* 58 */ c = II(c, d, a, b, groups[6], S43, 0xa3014314L); /* 59 */ b = II(b, c, d, a, groups[13], S44, 0x4e0811a1L); /* 60 */ a = II(a, b, c, d, groups[4], S41, 0xf7537e82L); /* 61 */ d = II(d, a, b, c, groups[11], S42, 0xbd3af235L); /* 62 */ c = II(c, d, a, b, groups[2], S43, 0x2ad7d2bbL); /* 63 */ b = II(b, c, d, a, groups[9], S44, 0xeb86d391L); /* 64 */ /*加入到之前计算的结果当中*/ result[0] = a; result[1] = b; result[2] = c; result[3] = d; result[0] = result[0] & 0xFFFFFFFFL; result[1] = result[1] & 0xFFFFFFFFL; result[2] = result[2] & 0xFFFFFFFFL; result[3] = result[3] & 0xFFFFFFFFL; } /** * 线性函数 */ private long F(long x, long y, long z) { return (x & y) | ((~x) & z); } private long G(long x, long y, long z) { return (x & z) | (y & (~z)); } private long H(long x, long y, long z) { return x ^ y ^ z; } private long I(long x, long y, long z) { return y ^ (x | (~z)); } private long FF(long a, long b, long c, long d, long M, long s, long K) { a = (F(b, c, d) & 0xFFFFFFFFL) M K; a = ((a & 0xFFFFFFFFL) << s) | ((a & 0xFFFFFFFFL) >>> (32 - s)); a = b; return (a & 0xFFFFFFFFL); } private long GG(long a, long b, long c, long d, long M, long s, long K) { a = (G(b, c, d) & 0xFFFFFFFFL) M K; a = ((a & 0xFFFFFFFFL) << s) | ((a & 0xFFFFFFFFL) >>> (32 - s)); a = b; return (a & 0xFFFFFFFFL); } private long HH(long a, long b, long c, long d, long M, long s, long K) { a = (H(b, c, d) & 0xFFFFFFFFL) M K; a = ((a & 0xFFFFFFFFL) << s) | ((a & 0xFFFFFFFFL) >>> (32 - s)); a = b; return (a & 0xFFFFFFFFL); } private long II(long a, long b, long c, long d, long M, long s, long K) { a = (I(b, c, d) & 0xFFFFFFFFL) M K; a = ((a & 0xFFFFFFFFL) << s) | ((a & 0xFFFFFFFFL) >>> (32 - s)); a = b; return (a & 0xFFFFFFFFL); } }
五、Android中的实现
1.核心算法
1.1 计算字符串的MD5值
public static String encrypt(String src) throws Exception{ MessageDigest md5 = MessageDigest.getInstance("MD5"); //得到加密后的字节数组 byte[] bytes = md5.digest(src.getBytes()); StringBuilder result = new StringBuilder(); //将字节数组转换成16进制式的字符串 for (byte b : bytes) { //1个byte为8个bit,一个hex(16)进制为16bit,故1个byte可以用2个hex表示 String temp = Integer.toHexString(b & 0xff); //不足2长度的用0来补充 if (temp.length() == 1) { temp = "0" temp; } result.append(temp); } //返回最终的字符串 return result.toString(); }
1.2 计算文件的MD5值
public static String getFileMD5(File file){ if(file == null||!file.exists()) return ""; FileInputStream in = null; byte[] buffer = new byte[1024]; StringBuilder res = new StringBuilder(); int len; try { MessageDigest messageDigest = MessageDigest.getInstance("MD5"); in = new FileInputStream(file); while ((len=in.read(buffer))!=-1){ //计算文件时需要通过分段读取多次调用update来将数据更新给MessageDigest对象 messageDigest.update(buffer,0,len); } //真正计算文件的MD5值 byte[] bytes = messageDigest.digest(); //将字节数组转换成16进制的字符串 for(byte b:bytes){ String temp = Integer.toHexString(b&0xff); if(temp.length()!=2){ temp = "0" temp; } res.append(temp); } //返回最终的字符串 return res.toString(); } catch (Exception e) { e.printStackTrace(); } finally { if(null!=in){ try { in.close(); }catch (Exception e){ e.printStackTrace(); } } } return res.toString(); }
2.实际应用
2.1 密码认证
密码认证估计是MD5在Android中运用最广泛的地方了。如今,正常的App都少不了注册登录的功能,而注册登录必不可少的就是密码,密码是用户在Android设备注册时需要向服务器发送密码,然后服务器将密码保存。这样就存在一种问题,如果密码以明文发送的的话,很可能在中途被恶意截取。又或者保存在服务器的密码被泄漏,也会造成很大的危害,于是为了用户的安全,一般会采用MD5对密码进行加密,然后将加密后的密码,其实就是密码的MD5值发送给服务器,这样即使MD5值泄漏,不法分子也很难得出正确的密码。而登录判定时,只需判断输入的密码的MD5值与服务器中的MD5值是否相同即可。口说无凭!我们先来看看下面微信公众平台,来证明很多平台的密码是经过MD5加密的。
微信公众平台
首先我们在微信公众平台网页端输入账号和密码

然后我们通过fiddler4爬取请求的接口,通过请求头我们可以找到username和pwd的字段,可以断定是账号和密码,接着核对账号,确认是我们刚刚输入的请求,然后核对pwd字段,结果发现是32位的字符串,我们可以断定这个32位字符串应该是MD5值,因为我们知道MD5值长度固定为128位,然后用16进制表示的话,就是32个16进制数字(128/4)
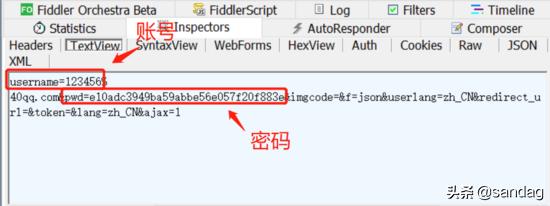
接着我们使用 Wan Android中的MD5加密工具 来验证此字符串是否为123456的MD5值。可以对比上下两张图,可以发现两者的字符串是一样的,所以我们可以断定当我们登录微信公众平台时,其密码是经过MD5加密后发送给服务器,然后服务器对比数据库中账号所对应的密码MD5值,由于不相同,所以返回了错误信息

2.2 一致性验证
一致性验证就是文件MD5值的应用,MD5加密时,将整个文件当作一个大文本信息,通过字符串变换算法,产生了唯一的MD5值。在Android中最常用的莫过于文件下载,比如首先服务器会预先给一个完整的文件提供一个MD5值,用户下载该文件后,重新计算文件的MD5值,如果相同,证明文件已经被成功的下载了。如果不相同,则证明文件下载出错或者当前文件还在下载中。在Android中使用计算文件的MD5值需要注意要将该操作放在子线程中操作,因为计算文件MD5值属于耗时操作,不能在主线程运行,否则会出现OOM的情况。
1.百度网盘的秒传
看到这估计有人会有些疑问,什么是秒传功能?不急,待我慢慢道来!
基本概念
假设现在有人分享了一个软件安全书籍的百度云链接给我们,然后我们接下来的操作就是,打开这个链接,接着我们将其保存到我们自己的网盘上,然后你会发现不管这个资源有多大,都能在几秒内保存到我们的网盘上,而这就是所谓的秒传(个人理解有错误请指出)
原理
秒传看上去很神奇,其实原理就是MD5的一致性验证。当我们成功上传资源到自己网盘时,服务器会计算这个完整文件的MD5值,然后保存在服务器上,当下一次要上传文件时,网盘首先会检测服务器是否有相同MD5值的文件,如果有的话,就直接从服务器复制到网盘上,这样就省去了上传的时间
过程
让我们重新解释下上面提到的例子:当分享人在分享软件安全书籍的资源时,一定是通过自己的百度网盘上来进行分享,这就证明该资源已经保存在服务器中,接下来我们打开了这个链接,然后点击保存时,网盘就检测到这个资源的MD5值已经存在在服务器中,所以不需要占用网络带宽,直接复制这个资源到我们的网盘上,从而实现了秒传。总体过程下图:

2.应用程序更新
也许你又纳闷了,应用程序更新为什么需要用到MD5?这是为了友好的用户体验以及安全性考虑,MD5一致性验证可以防止下载的更新APK被恶意篡改或者防止下载的APK不完整造成不良的用户体验。MD5在应用程序更新中的主要作用就是:
- 检验APK文件签名是否一致,防止下载被拦截和篡改
- 检验下载文件的完整性
五、安全性
上面讲了这么多,你会发现从MD5加密本身来讲这个过程是不可逆的,但并不意味着MD5算法不可破解,破解对于MD5一致性认证没多大影响,但是对于MD5的密码认证来说是致命的。
1. 撞库破解
如果让我们猜密码,肯定会猜“123456”,生日,手机号等,而撞库的原理也就是这么简单。首先建立一个大型的数据库,然后把最常见的,有可能出现的密码,通过MD5加密成密文,并且以这些MD5值为主键加索引,将常见的密码为单列存入数据库中,并通过不断的积累,形成一个巨大的密码MD5数据库,这样当你截取到网络上密码的MD5值时,通过查询这个巨大的数据库来直接匹配MD5值,这就是所谓的撞库。这么一看撞库有点类似穷举法,所以撞库破解的概率是很低的,但也不是说不可能破解。通过下面两个网站就很容易获得原文:
- www.cmd5.com/
- pmd5.com/}
2. MD5加盐
2.1 原理
MD5加密可以通过撞库来破解,因此为了防止内部人员和外部入侵者通过密码的MD5来反查密码明文,需要对密码掺入其它信息,然后算出加工后的密码的MD5值称之为MD5加盐。
2.2 加盐算法
1.账号 密码
这个加盐算法很简单,就是将当注册时将用户名和密码组合起来,然后计算其组合的MD5值作为密码发送到服务器上,这样就能增加反查的难度。但是这个加盐算法也存在问题,当应用程序提供修改用户名这一功能时,当用户名发生变化时,密码就不可用了(如果要用,就必须重新计算新的用户名和密码的MD5值然后发送给服务器,这样修改用户名,等于修改密码的功能)
2.随机数
原理
我们知道MD5加密有个特性,一个数据的MD5值永远都是一样的,也正是因为这个特性才有了MD5一致性的验证,但是也是撞库破解的一个入口。正是因为密码的MD5值永远都是一样的,所以可以根据MD5值直接从数据库中查询出密码。因此随机数算法就是给密码加入随机数然后生成新的MD5值,这样破坏这个特性,让密码的MD5值每次都是不一样的。
核心算法
/** * MD5加盐 * @param password 密码 * @return 密码加盐后的MD5值 */ public static String salting(String password){ Random random = new Random(); //随机数字符串最大容量为16位 StringBuilder sb = new StringBuilder(16); //生成最多为16位的随机字符串 sb.append(random.nextInt(99999999)).append(random.nextInt(99999999)); int len = sb.length(); //由于随机字符串的长度不一定都是16位,做统一16位长度处理 if(len<16){ for (int i = 0; i < 16-len; i ) { //在后面补0 sb.append("0"); } } //盐 String salt = sb.toString(); //得到加盐后密码的16进制字符串,此时password的长度为32 password = md5toHex(password salt); //最终的结果长度为48位 char[] res = new char[48]; //48位中,按一定的规则将加盐后的password存入res中 //总共循环16次 for (int i = 0; i < 48; i =3) { res[i] = password.charAt(i/3*2); res[i 1] = salt.charAt(i/3); res[i 2] = password.charAt(i/3*2 1); } //最终的md5值为48位,由16位随机字符串和密码加盐后的md5值组成 return new String(res); } /** * 验证服务器中的密码是否与输入的密码一致 * @param password 输入的密码 * @param md5 保存在服务器加盐后的md5值 * @return 密码是否正确 */ public static boolean decode(String password,String md5){ //盐,即随机数 char[] salt = new char[16]; //真正加盐后密码的MD5值 char[] realMd5 = new char[32]; //按照加盐规则提取出盐和真正的MD5值 for (int i = 0; i < 48; i =3) { realMd5[i/3*2] = md5.charAt(i); salt[i/3] = md5.charAt(i 1); realMd5[i/3*2 1] = md5.charAt(i 2); } //得出密码加盐后的MD5值 String tempMd5 = md5toHex(password new String(salt)); //与从服务器提取出来的真正MD5值进行对比 return new String(realMd5).equals(tempMd5); } /** * 获取16进制字符串形式的MD5值 * @param passwordAndSalt 密码加入随机数后的字符串 */ private static String md5toHex(String passwordAndSalt){ try { MessageDigest messageDigest = MessageDigest.getInstance("MD5"); byte[] bytes = messageDigest.digest(passwordAndSalt.getBytes()); StringBuilder result = new StringBuilder(); //将字节数组转换成16进制式的字符串 for (byte b : bytes) { //1个byte为8个bit,一个hex(16)进制为16bit,故1个byte可以用2个hex表示 String temp = Integer.toHexString(b & 0xff); //不足2长度的用0来补充 if (temp.length() == 1) { temp = "0" temp; } result.append(temp); } //返回最终的字符串 return result.toString(); } catch (NoSuchAlgorithmException e) { e.printStackTrace(); } return ""; }
流程
上面核心算法的加盐过程和验证如下图所示。

总结
MD5看似是很简单的加密算法,但是搞懂其底层实现原理并没有想象中那么容易。MD5加密算法不仅仅在安卓平台上,在其它平台上也是非常重要的一种加密算法。通过这次对MD5的学习,真的是收益匪浅,不仅仅让我对MD5有了更深的理解,并且认识到了MD5和加密算法的重要性。
,




