更多深度文章,请关注云计算频道:https://yq.aliyun.com/cloud
做为目前最火的国内社交APP,微博常常在特定时间或特定事件发生时迎来流量高峰。通过对近五年时间应对的峰值进行总结,可以抽象为三种常见的峰值:
-
第一种是日常的晚高峰;
-
第二种是各种运营活动以及明星、大V的热门微博所带来的流量高峰;
-
第三种是非常极端的突发事件导致的核心服务数倍的流量增长。

之所以需要关注这三类场景,主要是因为:
-
第一,尽管微博的功能众多,但冗余是非常少的,因此早晚高峰需要弹性扩容;
-
第二,活动、大V的热点事件能够提前预知,可以提前准备所需资源;
-
第三,极端事件是最需要关注的,它对系统的自动化程度要求非常高。
这三类场景可以简单总结为两大特点:瞬间峰值高、互动时间短。
产品迭代快,目前微博的现状是功能多,依赖复杂,导致发布和变更频繁;
运营上,站内外,活动、运营、大V均有Push场景,导致全量极速下发,互动时间短;
技术上存在突发的极端流量,目前热点多,“马航”、“王宝强”等事件十分考验服务的弹性伸缩。
那么在应对流量峰值时,应该主要关注哪些方面呢?
-
第一点是快速扩容、及时回收,这考验的是系统的弹性扩容、峰值应对的能力,这也是系统设计的最核心的目标;
-
第二点要注意成本优化,可伸缩的业务利用公有云,私有云内弹性部署;
-
第三点是运维标准化,微博流量来源主要是PC端和移动端,但两者的开发语言是不同的,因此系统需要打通多语言环境,通过Docker实现全公司统一平台;
-
第四点,由于业务迭代快速迭代,因此基础设施需要标准化,以供公有云和私有云使用。
传统应对手段 v.s. 云端弹性伸缩方案
传统的峰值应对手段第一步需要设备申请,项目评审;第二步需要入CMDB,上架装机;之后需要设备录入资源池,机器初始化;第三步需要运维人员进行服务部署,包括环境、监控、服务部署和流量引入;当流量峰值下降时,还需要服务自动下线以及设备置换或下架。整个链路十分冗长,大部分操作需要人工介入,而且依赖于企业内不同部门相互配合,在业务快速发展的今天,传统应对峰值的手段显然已经过时。

目前,微博采用的是DCP的弹性伸缩方案来应对流量峰值,具体架构如上图所示。架构内部主要采用私有云,早期采用物理机部署,通过化零为整建立冗余池;此外通过OpenStack KVM的虚拟化方式进行资源整合,建立VM池。在公有云方面,通过采用阿里云等设施进行多云对接。

建立统一的设备资源管理池后,下一步需要考虑的是服务部署、资源调度等问题。目前,微博采用的是基于Docker的云化架构:
-
业务上,由于部分业务并非无缝迁移到该架构上,这时需要对业务进行微服务化、消息化等改造;
-
平台上,需要部署敏捷基础设施,打通持续集成平台以及实现多租户隔离、弹性伸缩、故障自愈等能力。

除了公有云具有弹性伸缩能力之外,私有云也可以具有弹性。公司内某个部门可能就有很多业务,如果每个业务都保留很多冗余则会导致资源的大量闲置浪费。微博采用的是将每个业务的冗余拿出来放到共用的共享池内,当业务有需求时,从共享池内申请冗余;使用完成后归还申请的服务器,通过这种方式实现私有云的弹性伸缩。
在应对流量峰值时,除了上面提到的弹性伸缩系统,还需要统一的监控平台、核心链路服务自动伸缩、预案&干预手段相互配合,以保障峰值服务正常运行。
DCP的架构设计
下面是微博的DCP整体架构图。

最底层是物理主机资源;第二层是资源调度层;第三层是编排层,主要包括一些常见的自动化操作;最上层是业务层,由多种语言混合开发;架构的右侧是主要的基础设施。
在架构设计中面临的核心挑战主要包括以下三点。
-
镜像分发,包括镜像优化和分发速度的优化;
-
隔离设计,包括平台层隔离和部署/实例隔离;
-
弹性伸缩,包括自动扩缩容和故障转移。
下面分别进行说明。
架构挑战1:镜像分发
镜像分发的挑战,主要有镜像优化和分发速度的优化。
1. 镜像分发——镜像优化

镜像优化主要从两点入手:一是镜像制作优化;二是仓库部署优化。在镜像制作时,采用镜像分层,逐层复用,其次制作一些微镜像,用于分发速度提高。仓库部署优化,当业务集群访问Registry时,从早期的本地存储镜像改进为分布式存储,同时在阿里云上部署大量镜像缓存Mirror。
2. 镜像分发——分发速度

由于弹性伸缩大部分是在公有云上实现的,因此对镜像请求最大的也是在阿里云上,通过在阿里云上以级联的方式部署大量的Mirror,加快镜像分发速度。
常规情况下,部署几台Mirror即可,当弹性扩缩容时,将Registry横向扩容,作为业务扩容的依赖,业务扩容根据一定的配比关系,先将Registry进行扩容以及镜像的预热。这其中优势在于:
-
将Registry进行分级部署,常时只部署一部分,扩容时进行大批量横向部署;
-
将每一个Registry的带宽优化,这是因为Mirror是部署在ECS上,而ECS单机的PPS和带宽都是有一定限制的。
整体架构的目标是实现分发速度千台规模分钟级,未来的方向是在扩容层面支持P2P的镜像拉取方式。
架构挑战2:隔离设计
隔离设计的挑战,主要有平台层隔离和部署/实例隔离。我们主要做了如下几个方面的工作。
1. 隔离设计——隔离模型

隔离又分为平台上隔离、部署上隔离和实例上隔离三种。平台上隔离是指一个集群对应一个部门,例如微博平台、红包飞等有各自对应的大集群,内部的业务在下一级进行隔离;部署上隔离是指同一业务需要在不同机房部署,例如一个Feed业务在几个内部机房都有部署;实例上隔离主要是指CPU、MEM等通用的资源上进行隔离。隔离模型的右侧是资源共享池,作为全局共享池和集群Buffer池。
2. 隔离设计——平台层设计

在隔离模型中,平台层设计如上图所示。最上层用于接入业务,根据业务模型去定制一类的扩缩容、Job操作,如Java类、PHP类、大数据类;其次对外提供了丰富的GUI页面以及REST API用于用户操作。
接入层之下是平台层设计的最核心的部分。如上文所讲,一个产品线对应一个集群,将产品线上的业务场景抽象成定制化的模板、原子型API、任务实例和环境变量,然后再进行隔离设计,形成产品线的扩缩容流程。在底层的单个节点上采用根容器存放业务中通用的部分,如系统资源的监控。
3. 隔离设计——平台用户操作规范

由于对平台进行了隔离设计,为不同的管理员规定了不同的操作范围。在系统中,管理员主要分为超级管理员、集群管理员、服务池管理员三种,三种管理员的操作权限如上图所示,这里不再一一叙述。
架构挑战3:弹性伸缩
弹性伸缩的挑战,主要有自动扩缩容和故障转移。我们做了如下几个方面的工作。
1. “无人值守”的扩缩容
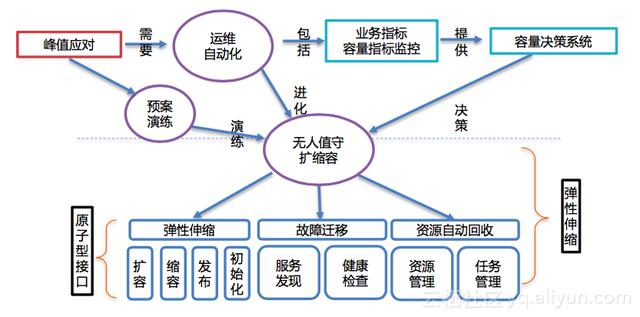
在应对流量峰值时,单单依靠管理员进行人工操作是远不够的,因此“无人值守”的自动化扩缩容显得十分必要。要实现“无人值守”的扩缩容,首先内部的工具系统需要实现自动化,各系统之间通过API打通,实现全部系统间的联动。
运维自动化包含业务指标和容量指标监控,将产生的数据提供给容量决策系统,在容量决策系统的决策下,实现从运维自动化进化为无人值守的扩缩容。
“无人值守”的三个核心在于弹性伸缩、故障迁移和服务自动回收,与之对应的是模板中原子型API(平台提供了第一版可用的原子型API,业务方也可以自定义所需的原子型API)。
2.扩容模板

如上图所示,在平台扩容时管理员需要向混合云平台发起请求;平台进行资源评估,如果配额足够,可以按照配额量申请;如果配额不够时,需要申请配额,防止资源滥用。
当申请到设备之后,需要调用系统内部的基础设施、配管系统等进行初始化操作,然后在调度中心发起容器调度、部署服务,服务部署之后会注册到Consul集群中。如果服务想对外提供服务,还需要将其接入统一负载均衡系统中,进行服务发现。最后一步需要添加监控中心。
要将上述步骤自动化,需要将这些步骤抽象成原子型API任务,然后在这些任务之上进行自动化模板设计。
3.原子型API任务系统Dispatch
原子型API任务是通过原子型API任务系统Dispatch完成的,它是由新浪自主研发的,采用C 编写,它在每个机器上都有一个Agent,在中心化组件Dispatch端根据任务模板定义任务,具体的任务细节在任务脚本中设计,最终对外提供成API。

4. 容量决策
当前有两种容量决策方式:第一种是定时触发,根据自动压测的指标、数据、经验值触发进行;第二种是自动进行,通过分析业务指标,对容量预估,进行同比、环比分析自动进行扩缩容操作。
5. 调度编排

上图是定时触发和自动触发的调度编排图,所有的数据存入Consul集群,通过CronTrigger模块定时检测是否有新任务产生,当有新任务产生时,通过Scheduler组件进行详细操作,最终对接服务发现系统。系统的输入是容量决策的数据,输出是扩容之后的业务池。
业务上云的标准姿势
业务上云时,需要考量以下四点:
-
安全上,如何解决敏感数据的存储问题;
-
部署上,如何解决业务依赖问题;
-
数据上,如何实现数据同步;
-
自动化,如何实现弹性伸缩。
目前的上云标准姿势有两种:一是混合云;二是XaaS。
在混合云架构中,核心关键是专线,它是实现内部与公有云之间弹性的核心。目前微博和阿里云之间已经拉通了多条专线,日常的核心消息通过多机房的消息组件同步到阿里云缓存中,实现前端层面和缓存层面的弹性伸缩。
在混合云的模式下,微博目前采用了两种部署方案。
第一种,除DB不在阿里云部署,其他整个链路全部部署在阿里云上。

第二种部署方案无需在阿里云上启用SLB、Nginx等服务,直接把阿里云中启用的容器放在内部的四/七层服务中。目前在微博中,主要使用第二种部署方案。






