我们在实际开发中, 经常需要处理文本信息, 组成文本的单元我们称之为字符 计算机只能处理0和1, 不能直接处理这些字符, 比如说对字符的读取和存储
为了解决这个问题, 我们可以建立一个数字与字符的关联关系, 比如说使用97 -> a, 98 -> b, 99 -> c..依据数字可以查询对应字符, 依据字符可以查询对应数字
这样我们需要处理字符的时候, 就可以先查询这个映射, 找到字符对应的数字, 然后把这个数字转换成二进制存储即可, 读取的时候亦然
- 字符集: 为每一个字符分配一个唯一的数字, 这个数字可以称之为码点
- 编码规则: 把码点转换为字节序列的规则
计算机最早是美国发明的, 所以一开始只需要处理英文的字符就可以了, 也就是ascii字符集. 后来计算机越来越普及, 更多的国家开始使用计算机, 这个时候就需要处理更多的字符, 比如说中文字符, 日韩字符...由于ascii字符集不支持, 所以各个国家也产生了许多支持更多字符的字符集, 比如说支持简体中文的gb2312字符集, 支持简体中文、繁体中文和日韩字符的gbk字符集...
多个字符集的问题:
- 维护起来十分复杂, 对于相同的字符, 多个字符集可能重复维护
- 不同字符集对同一个字符分配的码点可能不一样, 这样就导致编码和解码必须使用相同的字符集, 不然可能会出现乱码
为了解决上述多个字符集的问题, 我们需要一个维护所有字符, 统一的字符集, 我们称之为unicode字符集. uniocde14.0版本, 一共收录了144697个字符

unicode字符集
编码规则unicode解决了字符集统一的问题, 接下来还需要制定相应的编码规则
定长编码最简单粗暴的编码规则, 所有码点都使用相同长度的字节来表示, 比如说现在已知的字符数量大概14W多, 可以使用三个字节来表示(0 ~ 16777216)
优点: 编码简单
缺点: 不够节约空间, 只需要使用一个字节和两个字节表示的字符也使用了三个字节来表示
变长编码针对不同范围的码点, 使用不同长度的字节序列来表示 utf-8就是一种变长编码
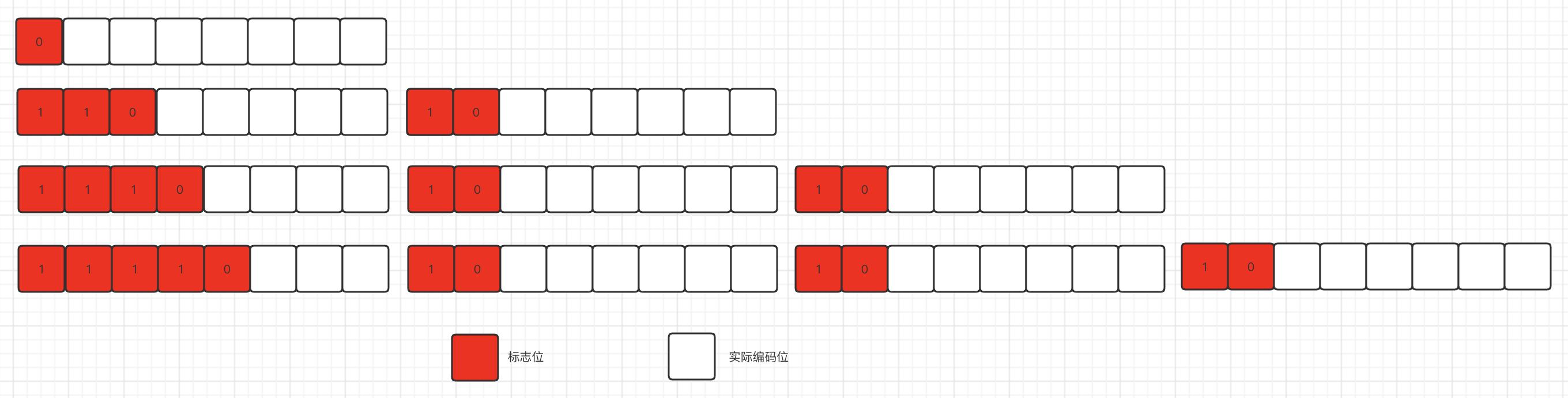
utf-8编码规则
|
字节 |
格式 |
实际编码位 |
码点范围 |
|
1字节 |
0xxxxxxx |
7 |
0 ~ 127 |
|
2字节 |
110xxxxx 10xxxxxx |
11 |
128 ~ 2047 |
|
3字节 |
1110xxxx 10xxxxxx 10xxxxxx |
16 |
2048 ~ 65535 |
|
4字节 |
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
21 |
65536 ~ 2097151 |
utf-8编码规则, 是一种前缀编码规则, 每一个字节都是由标志位 实际编码位组成, 第一个开始字节的高位1的个数表示这个编码占用了几个字节, 只占用一个字节的时候比较特殊, 使用0作为高位标志位
为什么占用多个字节时, 除了第一个开始字节外, 后续的字节也需要10作为前缀标志位?
- 后续字节使用10作为前缀标志位, 标志这个字节不能作为一个开始字节, 也是为了解决和开始字节的前缀标志位冲突, 实际上是为了解码服务
- 这样做可以把开始字节和非开始的字节区分开, 可以对utf-8编码进行校验, 如果一个开始字节后的后续字节数和开始字节前缀标志位中的字节数不符合, 那么校验失败
utf编码和解码图示:

utf-8编码/解码
,