数据模型由数据结构、数据操作和数据完整性约束三部分组成,这三部分也称为关系数据模型三要素。下面就从这三个方面介绍关系数据模型。
2.1.1 数据结构
关系模型源于数学,它使用二维表来组织数据,而这个二维表在关系数据库中就称为关系。关系数据库可以说是表或者关系的集合。
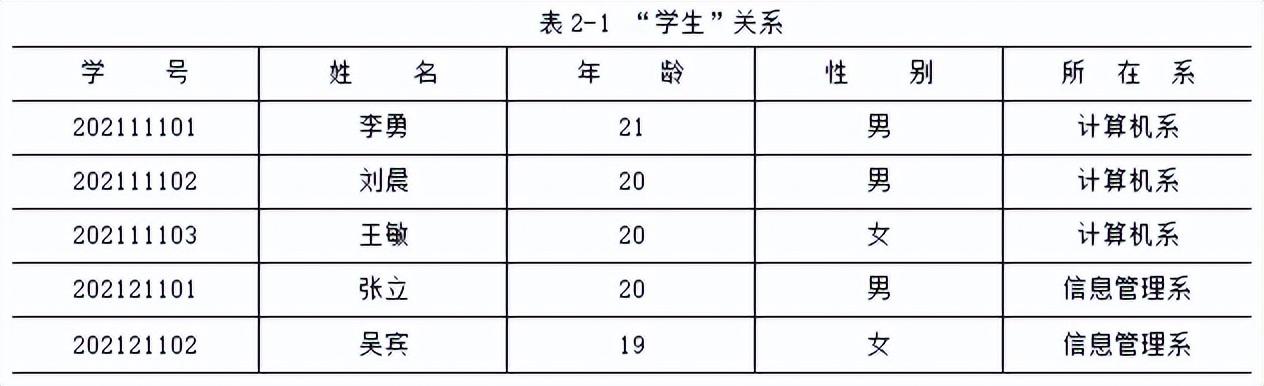
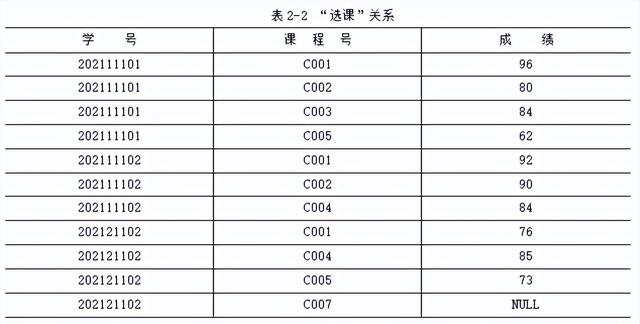
表2-1和表2-2分别为“学生”关系和“选课”关系示例。
2.1.2 数据操作
关系模型给出了关系操作的能力。关系模型的操作包括:
1.传统的关系运算:并(union)、交(intersection)、差(difference)、笛卡儿乘积(Cartesian product);
2.专门的关系运算:选择(select)、投影(project)、连接(join)等;
3.有关的数据操作:查询(query)、插入(insert)、删除(delete)和更改(update)。
关系模型的数据操作主要包括4种:查询、插入、删除和更改。
2.1.3 数据完整性约束
在数据库中数据的完整性是指保证数据正确性的特征。数据完整性由一组完整性规则定义,在关系模型中一般将数据完整性分为三类,即实体完整性、参照完整性和用户定义的完整性。
2.2 关系模型的基本术语关系模型源于数学,它有自己严格的定义和一些固有的术语。
1.关系
通俗地讲,关系(relation)就是二维表,二维表的名字就是关系的名字,表2-1中的关系名就是“学生”。
2.属性
二维表中的每一列称为一个属性(或字段),每个属性(attribute)都有一个名字,称为属性名。二维表中对应某一列的值称为属性值;二维表中列的个数称为关系的元数。如果一个二维表有n列,则称其为n元关系。如表2-1所示的“学生”关系有学号、姓名、年龄、性别、所在系5个属性,是一个五元关系。
3.值域
二维表中属性的取值范围称为值域(domain)。例如,在表2-1中,“年龄”列的取值为大于0的整数,“性别”列的取值为“男”和“女”两个值,这些都是列的值域。
4.元组
二维表中的一行数据称为一个元组(tuple),即记录值,表2-1“学生”关系中的元组有:
(202111101,李勇,21,男,计算机系)
(202111102,刘晨,20,男,计算机系)
(202111103,王敏,20,女,计算机系)
(202121101,张立,20,男,信息管理系)
(202121102,吴宾,19,女,信息管理系)
5.分量
元组中的每一个属性值称为元组的一个分量(component),n元关系的每个元组有n个分量。例如,对于元组(202111101,李勇,21,男,计算机系)有5个分量,对应“学号”属性的分量是“202111101”、对应“姓名”属性的分量是“李勇”、对应“年龄”属性的分量是“21”、对应“性别”属性的分量是“男”,对应“所在系”属性的分量是“计算机系”。
6.关系模式
二维表的结构称为关系模式(relation schema),或者说关系模式就是二维表的表框架或表头结构。设有关系名为R,属性分别为A1,A2,…,An,则关系模式可以表示为:
R(A1,A2,…,An)
每个Ai(i=1,…,n)还包括该属性到值域的映像,即属性的取值范围。例如,如表2-1所示关系的关系模式为:
学生(学号,姓名,年龄,性别,所在系)
如果将关系模式理解为数据类型,则关系就是该数据类型的一个具体值。
7.候选键
如果一个属性或属性集的值能够唯一标识一个关系的元组而又不包含多余的属性,则称该属性或属性集为候选键(candidate key)。候选键又称为候选关键字或候选码。在一个关系上可以有多个候选键。例如,对于“学生”关系,假设增加了“身份证号”属性,则“身份证号”也可以作为“学生”关系的候选键。
8.主键
主键(primary key)也称为主码或主关键字,是表中的属性或属性组,用于确定唯一元组。主键可以由一个属性组成,也可以由多个属性共同组成。例如,表2-1的“学生”关系中,“学号”是主键,因为“学号”的一个取值可以确定唯一学生。而表2-2的“选课”关系中,主键就由“学号”和“课程号”共同组成。因为一个学生可以选修多门课程,而且一门课程也可以有多个学生选修,因此,只有将“学号”和“课程号”组合起来才能共同确定一行记录。我们称由多个属性共同组成的主键为复合主键。当某个关系的主键是由多个属性共同组成时,需要用括号将这些属性括起来,表示共同作为主键。如表2-2所示的“选课”关系的主键是(学号,课程号)。
主键实际是从候选键中指定的,当一个关系中仅有一个候选键时,则主键同候选键;当一个关系中有多个候选键时,可以指定某个候选键作为主键。
9.主属性和非主属性
包含在任一候选键中的属性称为主属性(primary attribute)。不包含在任一候选键中的属性称为非主属性(nonprimary attribute)。
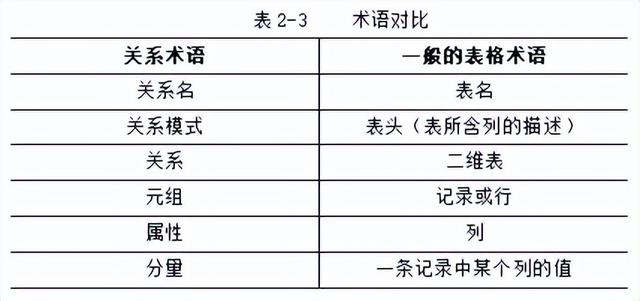
关系中的术语很多可以与现实生活中的表格所使用的术语相对应,如表2-3所示。
关系模型中的数据完整性规则是对关系的某种约束条件,它的完整性约束主要包括三大类:实体完整性、参照完整性和用户定义的完整性。
2.3.1 实体完整性
实体完整性是保证关系中的每个元组都是可识别的和唯一的。实体完整性是指关系数据库中所有的表都必须有主键,而且表中不允许存在如下记录:
1.无主键值的记录。
2.主键值相同的记录。
2.3.2 参照完整性
参照完整性也称为引用完整性。参照完整性就是用于描述实体之间的联系的。
参照完整性用于描述多个实体或关系之间的关联关系。
“外键”
定义:设F是关系R的一个或一组属性,如果F与关系S的主键K相对应,则称F是关系R的外键(foreign Key),并称关系R为参照关系(referencing relation),关系S为被参照关系(referenced relation)或目的关系(target relation)。关系R和关系S不一定是不同的关系。
外键并不要求与被参照的主键同名。但在实际应用中,为了便于识别,当外键与被参照的主键属于不同的关系时,通常是给它们取相同的名字。
参照完整性规则就是定义外键与被参照的主键之间的引用规则。
对于外键,一般应符合如下要求:
1. 或者值为空。
2. 或者等于其所参照的关系中的某个元组的主键值。
主键要求必须是非空且不重复的,但外键无此要求。外键可以有重复值。
2.3.3 用户定义的完整性
用户定义的完整性也称为域完整性或语义完整性。用户定义的完整性就是针对某一具体应用领域定义的数据约束条件。用户定义的完整性主要就是指明关系中属性的取值范围,也就是属性的域,这样可以限制关系中属性的取值类型及取值范围,防止属性的值与应用语义矛盾。
2.4 关系代数关系代数是一种纯理论语言,它定义了一些操作,运用这些操作可以从一个或多个关系中得到另一个关系,而不改变源关系。因此,关系代数的操作数和操作结果都是关系,而且一个操作的输出可以是另一个操作的输入。关系代数同算术运算一样,可以出现一个套一个的表达式。这种性质称为闭包(closure)。关系在关系代数下是封闭的,正如数字在算术操作下是封闭的一样。
关系代数的运算对象是关系,运算结果也是关系。与一般的运算一样,运算对象、运算符和运算结果是关系代数的三大要素。
关系代数的运算可分为以下两大类:
1. 传统的集合运算。这类运算完全把关系看成是元组的集合。传统的集合运算包括集合的笛卡儿积、并、交和差运算。
2. 专门的关系运算。这类运算除把关系看作元组的集合外,还通过运算表达了查询的要求。专门的关系运算主要包括选择、投影和连接。
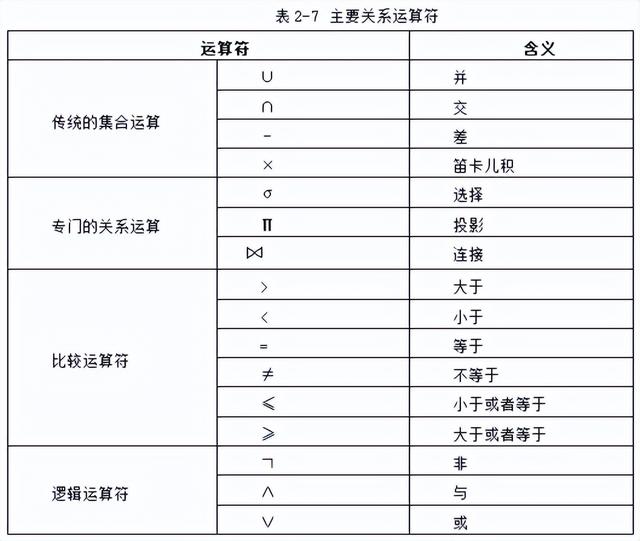
关系代数中的运算符可分为4类:传统的集合运算符、专门的关系运算符、比较运算符和逻辑运算符。表2-7列出了主要的关系运算符,其中比较运算符和逻辑运算符是配合专门的关系运算符来构造表达式的。
2.4.1 传统的集合运算
传统的集合运算是二目运算,设关系R和S均是n元关系,且相应的属性值取自同一个值域,则可以定义三种运算:并运算(∪)、交运算(∩)和差运算(-)。笛卡儿积并不要求参与运算的两个关系的对应属性取自相同的域。
以图2-4(a)和2-4(b)所示的两个关系为例,说明这三种传统的集合运算。
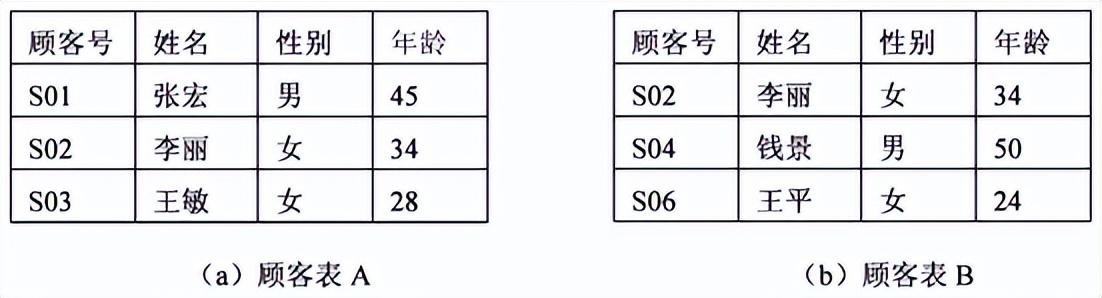
图2-4 描述顾客信息的两个关系
1.并运算
设关系R与关系S均是n目关系,关系R与关系S的并记为
R∪S={t | t∈R ∨ t∈S }
其结果仍是n目关系,由属于R或属于S的元组组成,但不包含重复的元组。其示意图如图2-5(a)所示。
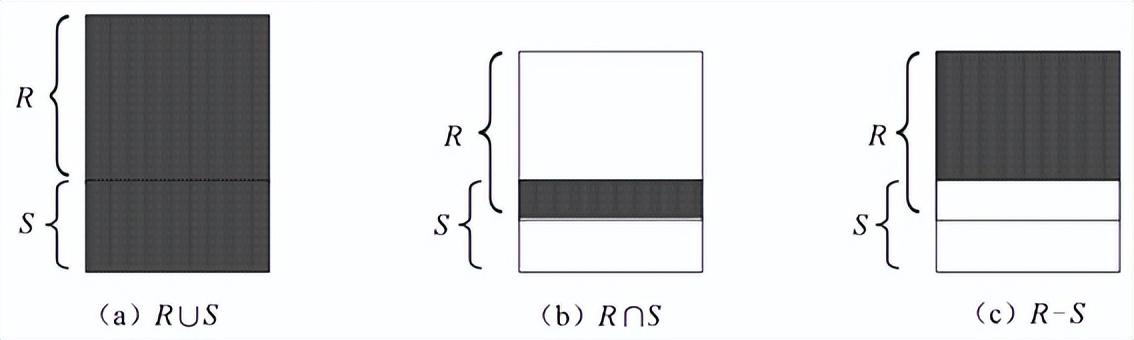
图2-5 并、交、差运算示意图
图2-6(a)显示了图2-4(a)和图2-4(b)两个关系的并运算结果。
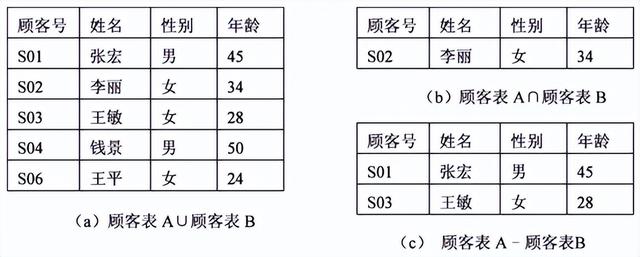
图2-6 集合的并、交、差运算示意图
2.交运算
设关系R与关系S均是n目关系,则关系R与关系S的交记为
R∩S={t | t∈R ∧ t∈S }
其结果仍是n目关系,由属于R并且也属于S的元组组成,其示意图如图2-5(b)所示。
图2-6(b)显示了图2-4(a)和2-4(b)两个关系的交运算结果。
3.差运算
设关系R与关系S均是n目关系,则关系R与关系S的差记为
R-S={t | t∈R ∧ t∉S }
其结果仍是n目关系,由属于R并且不属于S的元组组成,其示意图如图2-5(c)所示。
图2-6(c)显示了图2-4(a)和2-4(b)两个关系的差运算结果。
4.笛卡儿积
笛卡儿积不要求参加运算的两个关系具有相同的目。
m目的关系R和n目的关系S的笛卡儿积是一个(m+n)目的元组的集合。元组的前m列是关系R的一个元组,后n列是关系S的一个元组。若R有K1个元组,S有K2个元组,则关系R和关系S的笛卡儿积有K1×K2个元组,记作
R×S={tr^ts | tr∈R ∧ ts∈S }
tr^ts表示由两个元组tr和ts前后有序连接而成的一个元组。
任取元组tr和ts,当且仅当tr属于R且ts属于S时,tr和ts的有序连接即为R×S的一个元组。
实际操作时,可从R的第一个元组开始,依次与S的每一个元组组合,然后,对R的下一个元组进行同样的操作,直至R的最后一个元组也进行同样的操作为止,即可得到R×S的全部元组。
如图2-7所示为两个关系的笛卡儿积操作示意图。
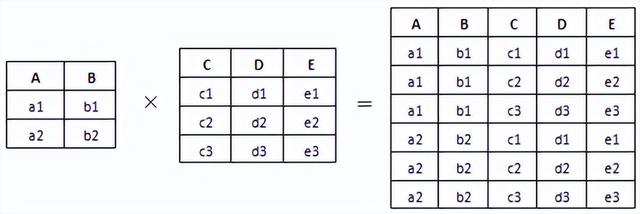
图2-7 两个关系的笛卡儿积操作示意图
2.4.2 专门的关系运算
专门的关系运算包括选择、投影、连接、除等运算,其中选择和投影为一元操作,连接和除为二元操作。我们这里只介绍选择、投影和连接运算。
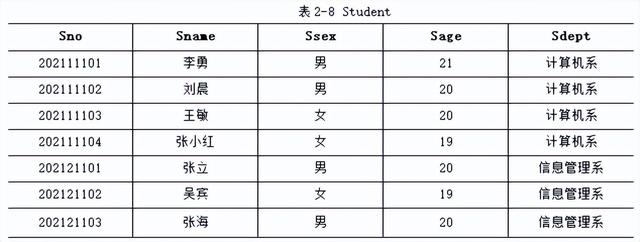
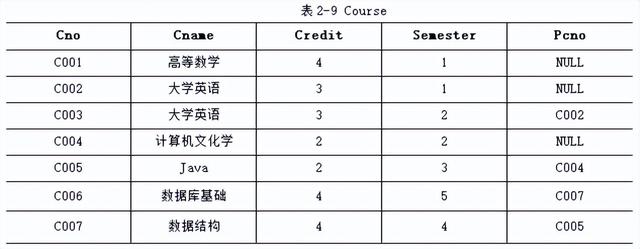
下面我们以表2-8~表2-10的三个关系为例,介绍选择、投影和连接运算的含义。表2-8~表2-10所示的三个关系的属性含义如下:
Student:Sno(学号),Sname(姓名),Ssex(性别),Sage(年龄),Sdept(所在系)。
Course:Cno(课程号),Cname(课程名),Credit(学分),Semester(开课学期),Pcno(直接先修课)。
SC:Sno(学号),Cno(课程号),Grade(成绩)。

1. 选择
选择(selection)运算是从指定的关系中选择满足给定条件(用逻辑表达式表达)的元组而组成一个新的关系。选择运算示意图如图2-8所示。
图2-8 选择运算示意图
选择运算表示为
σF(R)={r | r∈R ∧ F(r)=‘真’ }
其中,σ是选择运算符,R是关系名,r是元组,F是逻辑表达式,取逻辑“真”值或“假”值。
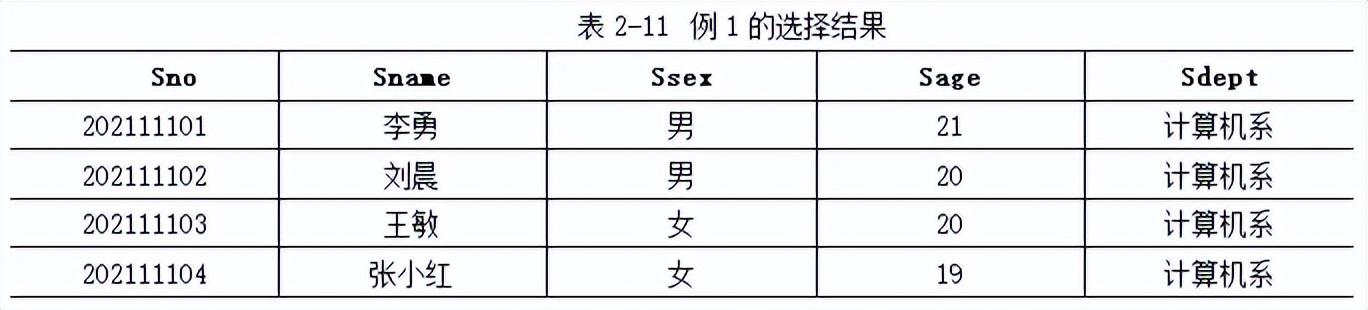
例1. 对照表2-8所示的Student关系,查询计算机系学生信息。
关系代数表达式为
σSdept=‘计算机系’ (Student)
结果如表2-11所示。
2. 投影
投影(projection)运算是从关系R中选择若干属性,并用这些属性组成一个新的关系。如图2-9显示了投影运算示意图。

图2-9 投影运算示意图
投影运算表示为
∏A(R) = { r.A | r∈R }
其中,∏是投影运算符,R是关系名,A是被投影的属性或属性组。r.A表示r元组中相应于属性(集)A的分量,也可以表示为r[A]。
投影运算一般由两个步骤完成:
(1)选择指定的属性,形成一个可能含有重复数据行的新关系;
(2)删除重复行,形成结果关系。
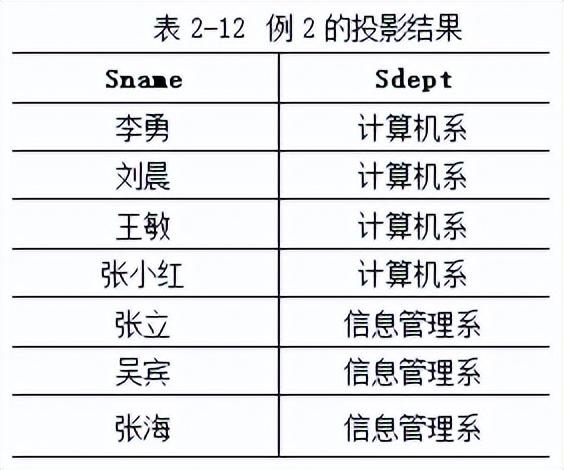
例2.对表2-8所示的Student关系,在Sname和Sdept两个列上进行投影运算,可以表示为
∏sname,sdept(Student)
结果如表2-12所示。
3. 连接
连接(join)运算用来连接相互之间有联系的两个关系,从而产生一个新的关系。这个过程由连接属性(字段)来实现。一般情况下连接属性是出现在不同关系中的语义相同的属性。
常用的连接运算有:θ连接、等值连接(θ连接的特例)、自然连接和外连接,其中最重要也是最常用的是等值连接和自然连接。
θ连接运算一般表示为
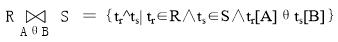
其中A和B分别是关系R和S上语义相同的属性或属性组,θ是比较运算符。连接运算从R和S的笛卡儿积R×S中选择(R关系)在A属性组上的值与(S关系)在B属性组上值满足比较运算符θ的元组。
当θ为“=”时的连接为等值连接,它是从关系R与关系S的笛卡儿积中选取A、B属性组值相等的那些元组,即
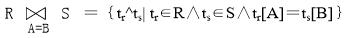
自然连接是一种特殊的等值连接,它要求两个关系中进行比较的分量必须是相同的属性或属性组,并且在连接结果中去掉重复的属性列,使公共属性列只保留一个。即若关系R和S具有相同的属性组A,则自然连接可记作:
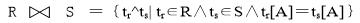
一般的连接运算是从行的角度进行运算,但自然连接还需要去掉重复的列,所以是同时从行和列的角度进行运算。
自然连接与等值连接的差别为:
(1)自然连接要求相等的分量必须有相同的属性名,等值连接则不要求;
(2)自然连接要求把结果中重复的属性去掉,等值连接却不这样做。
2.5 关系规范化理论2.5.1 函数依赖
1. 基本概念
函数对我们来说已经是非常熟悉的概念,对公式:
Y = f ( X )
自然也不会陌生,但是大家熟悉的是X和Y之间数量上的对应关系,也就是给定一个X值,都会有一个Y值和它对应,也可以说,X函数决定Y,或Y函数依赖于X。在数据库中,函数依赖注重的是语义上的关系,例如:
省= f (城市)
只要给定一个具体的城市值,就会有唯一省值和它对应,如“武汉市”在“湖北省”,这里“城市”是自变量X,“省”是因变量或函数值Y。并且把X函数决定Y,或Y函数依赖于X表示为
X→Y
由以上说明可以写出较直观的函数依赖定义:
设有关系模式R(A1,A2,…,An),X和Y为{A1,A2,…,An}的子集,如果对于R中的任意一个X值,都只有一个Y值与之对应,则称X函数决定Y,或Y函数依赖于X。
2. 术语和符号
下面给出我们用到的一些术语和符号。设有关系模式R(A1,A2,…,An),X和Y均为{A1, A2, … , An}的子集
(1) 如果X→Y,但Y不包含于X,则称X→Y是非平凡的函数依赖。如不作特别说明,我们总是讨论非平凡函数依赖。
(2) 如果X→Y,则称X为决定因子。
(3)如果X→Y,并且对于X的任意一个真子集X’都有X’
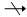
Y,则称Y完全函数依赖于X,记作X
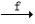
Y;如果X’→Y成立,则称Y部分函数依赖于X,记作X
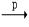
Y。
(4) 如果X→Y、Y→Z,则称Z传递函数依赖于X。
3. 讨论函数依赖的必要性
讨论属性之间的函数依赖有什么必要呢?让我们通过例子看一下。
设有描述学生选课及住宿情况的关系模式:
S-L-C( Sno,Sdept,Sloc,Cno,Grade)
其中,各属性的含义分别为:学号、学生所在系、学生所住宿舍楼号、课程号和考试成绩。假设一个系的学生都住在一个宿舍楼里。该关系模式的主键为(Sno,Cno)。
看一下这个关系模式存在什么问题?假设该表有如表2-17所示的数据。
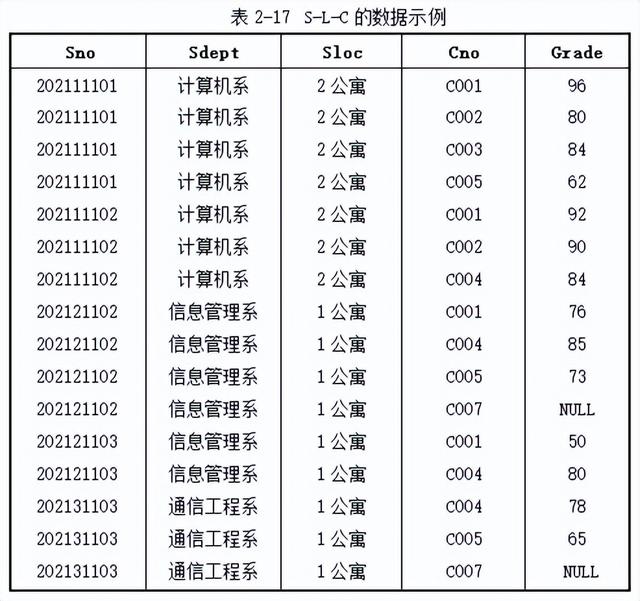
从这个表中我们可以看到如下问题:
(1)数据冗余。
(2)数据更新。
(3)数据插入。
(4)数据删除。
类似的各种问题我们统称为操作异常。
解决上述各种问题的方法就是进行模式分解,即把一个关系模式分解成两个或多个关系模式,在分解的过程中消除那些“不良”的函数依赖,从而获得好的关系模式。
2.5.2 关系规范化
关系数据库中的关系要满足一定的要求,满足不同程度要求的为不同的范式。满足最低要求的为第一范式,简称1NF(First Normal Form)。在第一范式中进一步满足一些要求的为第二范式,简称2NF,依此类推,还有3NF、BCNF、4NF和5NF。
1. 第一范式
定义:不包含非原子项属性的关系是第一范式的关系。
2. 第二范式
定义:如果关系模式R∈1NF,并且R中的每个非主属性都完全函数依赖于主键,则R∈2NF。
可以用模式分解的方法将非2NF的关系模式分解为2NF的关系模式。
消除部分函数依赖的分解步骤为:
(1) 对于组成主键的属性集合的每一个子集,用它作为主键构成一个关系模式。
(2) 对每个关系模式,将依赖于此主键的属性放置到此关系模式中。
(3) 去掉只由主键的子集构成的关系模式。
3. 第三范式
定义:如果关系模式R∈2NF,并且所有非主属性都不传递函数依赖于主键,则R∈3NF。
消除传递函数依赖的分解步骤为:
(1)对于不是候选键的每个决定因子,从表中删去依赖于它的所有属性。
(2)新建一个关系模式,新关系模式包含在原关系模式中所有依赖于该决定因子的属性。
(3)将决定因子作为新关系模式的主键。
由于3NF关系模式中不存在非主属性对主键的部分函数依赖和传递函数依赖,因而消除了很大一部分数据冗余和更新异常,因此在通常的数据库设计中,一般要求将关系模式分解到3NF即可。
2.5.3 关系模式的分解准则
关系规范化的方法是进行模式分解,但分解后产生的关系模式应与原关系模式等价,即模式分解必须遵守一定的准则,不能表面上消除了操作异常现象,却留下了其他的问题。模式分解要满足:
● 模式分解具有无损连接性。
● 模式分解能够保持函数依赖。
,




