Lambda Lab 出品 伊瓢 编译 量子位 报道 | 公众号 QbitAI
英伟达新发布的RTX 2080 Ti跑深度学习怎么怎么样?
美国人工智能公司Lambda用TensorFlow测试了RTX 2080 Ti。相比1080 Ti, 2080 Ti值得买么?
TL; DR· 在RTX 2080 Ti上用TensorFlow单精度(FP32)训练CNN比1080 Ti快27%到45%。
· 在RTX 2080 Ti上用TensorFlow半精度(FP16)训练CNN比1080 Ti快60%到65%。
· 如果你做FP16训练,RTX 2080 Ti可能物有所值。做其他训练的话,你需要考虑是否值得为平均增加36%的速度增加71%的成本。
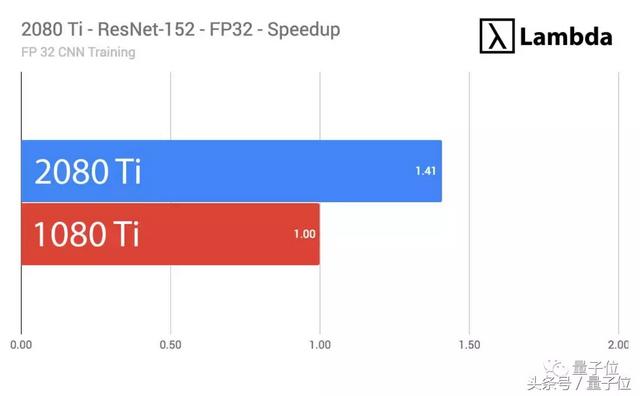
△ 2080 Ti单精度ResNet-152训练的速度是1080Ti的1.41倍
△ 2080 Ti半精度ResNet-152训练的速度是1080Ti的1.65倍
△ 各种模型上的2080 Ti表现比较
原始基准数据2080 Ti和1080 Ti的单精度表现
我们用TensorFlow模型对2080 Ti和1080 Ti进行了单精度(FP32)训练的基准测试,计量每秒处理的图像(图像/秒)。基准测试可以在文末传送门处找到,下文会提到具体方法。
△ 在FP32训练中2080 Ti相比1080Ti的提速倍数
△ 原始FP32训练速度(图像/秒)
2080 Ti和1080 Ti的半精度性能
半精度算术足以训练许多网络。我们对VGG16和ResNet-152的半精度(FP16)训练的2080 Ti和1080 Ti进行基准测试,计量的还是每秒处理的图像(图像/秒)。使用Yusaku Sako基准脚本进行测试。
△ 用于FP16 / FP32训练的2080 Ti加速
△ 原始FP16 / FP32训练速度(图像/秒)
性价比如何?因为2080 Ti和1080 Ti这两张款GPU都有11 GB的内存,所以我们会考虑在它们身上花的每一分钱值不值。
计量的指标是每美元每秒处理的图像数量。对于FP32和FP16,1080 Ti每美元会花的更值。
然而,Yusaku Sako基准测试中的FP16 ResNet-152的效率增益仅为1080 Ti的4%。对于FP32,ResNet-152的效率提升为21%,VGG16提高37%。
我们分别以700美元和1200美元的发售价来计算1080 Ti和2080 Ti的价格。
因此,如果你要做FP32训练,1080 Ti可能依然是最佳选择,尤其是在荷包压力比较大的情况下。
△ FP16的成本效率
△ FP32的成本效率
测试方法· 对于每个模型,我们进行了10次训练实验,计数每秒处理的测量图像,取平均值。
· 加速基准是通过每秒处理的图像数量除以该模型每秒处理的图像数量最小值为得分来计算的。这基本上显示了相对于基线的百分比改善(在这种情况下为1080 Ti)。
· 2080 Ti在基准测试中有张量核心。
硬件
· Lambda Quad Basic
· RAM:64 GB DDR4 2400 MHz
· 处理器:Intel Xeon E5-1650 v4
· 主板:华硕X99-E WS / USB 3.1
· GPU:EVGA XC 2080 Ti GPU TU102和华硕1080 Ti Turbo GP102
软件
· Ubuntu 18.04(仿生)
· TensorFlow 1.11.0-rc1
· CUDA 10.0.130
· CuDNN 7.3
可重现Lambda Lab已经把基准测试代码开源了,你也可以自己尝试重现一下。
第一步:复制基准报告
1git clone https://github.com/lambdal/lambda-tensorflow-benchmark.git --recursive
第二步:运行基准测试
· 输入正确的gpu_index(默认值为0)和num_iterations(默认值为10)
1cd lambda-tensorflow-benchmark 2./benchmark.sh gpu_index num_iterations
第三步:获得结果
· 检查repo目录中的文件夹 - .logs(由benchmark.sh生成)
· 在基准测试和报告中使用相同的num_iterations。
1./report.sh <cpu>-<gpu>.logs num_iterations
批量大小使用
传送门
Lambda Lab测试原文:
https://lambdalabs.com/blog/2080-ti-deep-learning-benchmarks/
github基准测试代码:
https://github.com/lambdal/lambda-tensorflow-benchmark
Yusaku Sako基准脚本:
https://github.com/u39kun/deep-learning-benchmark
— 完 —
诚挚招聘
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复“招聘”两个字。
量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
,