回归分析实质上就是研究一个或多个自变量X对一个因变量Y(定量数据)的影响关系情况。
当自变量为1个时,是一元线性回归,又称作简单线性回归;自变量为2个及以上时,称为多元线性回归。例如:研究吸烟、喝酒、久坐对高血压患病的影响关系等。
SPSSAU操作SPSSAU左侧仪表盘“通用方法”→“线性回归”;

回归分析用于研究X(定量或定类)对Y(定量)的影响关系,是否有影响关系,影响方向及影响程度情况如何。
第一:首先分析模型拟合情况,即通过R方值分析模型拟合情况,以及可对VIF值进行分析,判断模型是否存在共线性问题【共线性问题可使用岭回归或者逐步回归进行解决】;第二:写出模型公式(可选);第三:分析X的显著性;如果呈现出显著性(p值小于0.05或0.01);则说明X对Y有影响关系,接着具体分析影响关系方向;第四:结合回归系数B值,对比分析X对Y的影响程度(可选);第五:对分析进行总结。
回归分析之前,可使用箱盒图查看是否有异常数据,或使用散点图直观展示X和Y之间的关联关系;回归分析之后,可使用正态图观察和展示保存的残差值正态性情况;或使用散点图观察和展示回归模型异方差情况【残差与X间的散点完全没有关系则无异方差】。
SPSSAU结果与指标解读1.线性回归分析结果


计算:
(1)t值
t=回归系数/回归系数的标准误;t=常数项/常数项的标准误;例:0.588/0.199=2.961
(2)VIF(方差膨胀因子)

对于VIF说明:其值介于1~之间。其值越大,自变量之间存在共线性的可能越大;
(3)R2
;它是判断线性回归直线拟合优度的重要指标,表明决定系数等于回归平方和在总平方和中所占比率,体现了回归模型所解释的因变量变异的百分比;例:R2=0.775,说明变量y的变异中有77.5%是由变量x引起的,R2=1,表明因变量与自变量成函数关系。
(4)调整R2

其中,k为自变量的个数;n为观测项目。自变量数越多,与R2的差值越大;例:

(5)F值
参考下方ANOVA表格(中间过程)
F=回归均方/残差均方;0.254/0.237=1.068
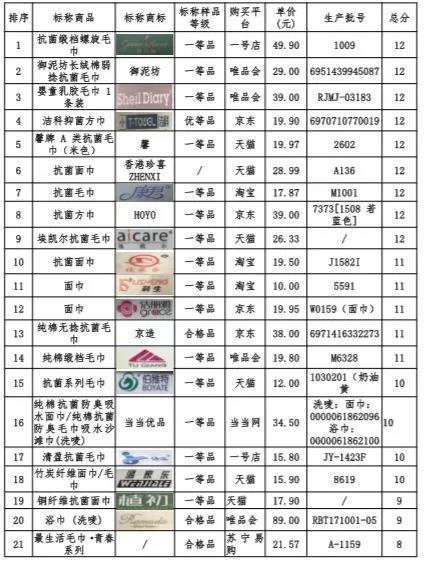
从上表可知,将价格,性能,品牌偏好作为自变量,而将笔记本是否购买作为因变量进行线性回归分析,从上表可以看出,模型公式为:笔记本是否购买=0.588 0.033*价格-0.116*性能 0.061*品牌偏好,模型R方值为0.032,意味着价格,性能,品牌偏好可以解释笔记本是否购买的3.2%变化原因。对模型进行F检验时发现模型并没有通过F检验(F=1.068, p=0.367>0.05),也即说明价格,性能,品牌偏好并不会对笔记本是否购买产生影响关系,因而不能具体分析自变量对于因变量的影响关系,分析结束。
2.模型汇总(中间过程)


补充说明
:一般对于时间序列分析才会考虑DW值:
- 当残差与自变量互为独立时,DW≈2;
- 当相邻两点的残差为正相关时,DW<2;
- 当相邻两点的残差为负相关时,DW>2;
3.ANOVA表格(中间过程)

F=回归均方/残差均方;0.254/0.237=1.068;
对模型进行F检验时发现模型并没有通过F检验(F=1.068,p=0.367>0.05),也即说明价格,性能,品牌偏好并不会对笔记本是否购买产生影响关系,因而不能具体分析自变量对于因变量的影响关系。
4.回归系数(中间过程)

95%CI:是指由样本统计量所构造的总体参数的估计区间(置信区间)。
补充说明:SPSSAU还提供了coefPlot、预测模型等。例如下图:


1.回归分析缺少Y?
回归分析是研究X对于Y的影响。有时候由于问卷设计问题,导致直接缺少了Y(没有设计对应的问卷题项),建议可以考虑将X所有题项概括计算平均值来表示Y。(使用“ 生成变量”的 平均值功能)(另提示:如果问卷中并没有设计出Y对应的题项,没有其它办法可以处理)
2.影响关系的大小,那个自变量影响更大一点?
如果说自变量X已经对因变量Y产生显著影响(P< 0.05),还想对比影响大小,建议可使用标准化系数( Beta)值的大小对比影响大小,Beta值大于0时正向影响,该值越大说明影响越大。Beta值小于0时负向影响,该值越小说明影响越大。
3.回归分析之前是否需要先做相关分析?
一般来说,回归分析之前需要做相关分析,原因在于相关分析可以先了解是否有关系,回归分析是研究有没有影响关系,有相关关系但并不一定有回归影响关系。当然回归分析之前也可以使用散点图直观查看数据关系情况等。
4.常数项值很大或者很小?
常数项无实际意义,包括其对应的显著性值等均无实际意义,只是数学角度上一定存在而已。
5.回归系数非常非常小或者非常非常大?
如果说数据的单位很大,不论是自变量X还是因变量Y;此种数据会导致结果里面的回归系数出现非常非常小,也或者非常非常大。此种情况是正常现象,但一般需要对数据进行统一取对数处理,以减少单位问题带来的‘特别大或特别小的回归系数’问题。
总结以上就是多元线性回归分析的指标解读,对于线性回归的操作步骤具体可以查看推荐文章,线性回归在实际研究里非常常见,但是理论与实际操作会有较大“距离”,具体还需要结合实际研究考察。
,