如果对深度学习有所了解的小伙伴们想必都知道,深度学习需要使用强大的服务器、加速嵌入式平台(如NVIDIA的Jetson)来运行深度学习算法,然而这也同样意味着不菲的开支。
那么问题来了,如果你想你想用树莓派来做一个目标跟踪器,为你看家守院,这可以实现吗?换句话说,如果你需要在不带加速器的ARM CPU上运行卷积神经网络了怎么办?
如何优化推理时间?
本文将尝试回答一个简单的问题:什么库/工具包/框架可以帮助我们优化训练模型的推理时间?本文只讨论已为ARM架构芯片提供C / C 接口的工具包和库(由于嵌入式设备上使用 ,我们很少Lua 或 Python),限于文章篇幅,不阐述另外一种加速神经网络推理的方法,即修改网络架构,从SqeezeNet架构可看出,修改网络架构是一个可行的方案。基于上述原因,本文涉及的实验只涉及使用Caffe,TensorFlow和MXNet这3个开源的深度学习框架。
加速神经网络模型在硬件平台计算速度,两个主要有大的策略:
1)修改神经网络的模型;2)加快框架运行速度。如果你的框架中使用了 OpenBLAS(基础线性代数程序集的开源实现),你可以尝试使用其为深度学习进行过优化的分支: https://github.com/xianyi/OpenBLAS/tree/optimized_for_deeplearning
NNPACK 能和其他一些框架(包括 Torch、Caffe 和 MXNet)联合使用:http://github.com/Maratyszcza/NNPACK 将TensorFlow编译为在树莓派平台的目标代码时,你可以使用一些编译优化标志,从而充分利用NEON 指令集加速目标代码的执行速度:http://github.com/tensorflow/tensorflow/tree/master/tensorflow/contrib/makefile#raspberry-pi 基于以上3种方法,我概括出以下调测配置:
1. 使用以 OpenBLAS为后端的Caffe 主分支(caffe-openblas);2. 使用以 OpenBLAS为后端OpenBLAS 且为深度学习优化过的Caffe分支版本(caffe-openblas-dl);3. 编译TensorFlow时,使用优化编译标志 OPTFLAGS="-Os" (tf-vanilla)4. 编译TensorFlow时,使用优化编译标志 OPTFLAGS="-Os -mfpu=neon-vfpv4 -funsafe-math-optimizations -ftree-vectorize" (tf-neon-vfpv4)5. 使用以OpenBLAS实现基础线性代数程序集的Vanilla MXNet6. 使用带有 OpenBLAS 、且为深度学习优化过MXNet 分支版本(mxnet-openblas-dl)。你可能会疑惑:配置中怎么没有 NNPACK?这确实有点复杂,由 ajtulloch 创建的 Caffe 分支提供了最直接的使用 NNPACK方法。然而自从它被集成进去以后,NNPACK 的API接口 就已经改变了,并且目前我无法编译它。Caffe2 对 NNPACK 有原生支持,但我不会考虑 Caffe2,因为它处于实验性阶段并且几乎对Caffe进行了尚未文档化的重构。另外一个选项就是使用Maratyszcza的caffe-nnpack分支,但该分支比较老旧且已经停止维护。
另外一个问题就是出于NNPACK本身。它只提供了Android/ARM平台的交叉编译配置,并不提供在 Linux/ARM 平台上的交叉编译配置。结合MXNet,我尝试编译目标平台代码,但结果无法在目标平台上正常运行。我只能在台式电脑上运行它,但是我并没有看到比 OpenBLAS 会有更好的性能。由于我的目标是评估已经可用的解决方法,所以我只能推迟NNPACK 的实验了。
以上所有的这些方法都是在四核 1.3 GHz CPU 和 1 GB RAM 的树莓派 3 上执行。操作系统是 32 位的 Raspbian,所以检测到的 CPU 不是 ARMv8 架构,而是 ARMv7 架构。硬件规格如下:
- model name : ARMv7 Processor rev 4 (v7l)
- BogoMIPS : 38.40
- Features : half thumb fastmult vfp edsp neon vfpv3 tls vfpv4 idiva idivt vfpd32 lpae evtstrm crc32
- CPU implementer : 0x41
- CPU architecture: 7
- CPU variant : 0x0
- CPU part : 0xd03
- CPU revision : 4
为了评估上述每个测试配置的性能,我制定的测试方案如下:使用相同的神经网络。也就是一个有 3 个卷积层和2个全连接层且在顶层带有Softmax的小型卷积神经网络:
conv1: 16@7x7relu1pool1: MAX POOL 2x2conv2: 48@6x6relu2pool2: MAX POOL 3x3conv3: 96@5x5relu3fc1: 128 unitsfc2: 848 unitssoftmax该卷积神经网络有 1039744 个参数。虽然非常小,但它已经足够强大了,可以用来处理许多计算机视觉算法。该网络使用 Caffe 进行训练人脸识别任务,并将其转换为 TensorFlow 和 MXNet 格式,从而使用这些框架进行评估。批量执行次数对性能有很大的影响,为了测量前向通过时间(forward pass time),我们将批量执行的次数设置为 1 到 256。在不同次数的批量执行中,我们每次执行 100 次前向通过,并计算了每一张图像的平均处理时间。
评估结果和讨论
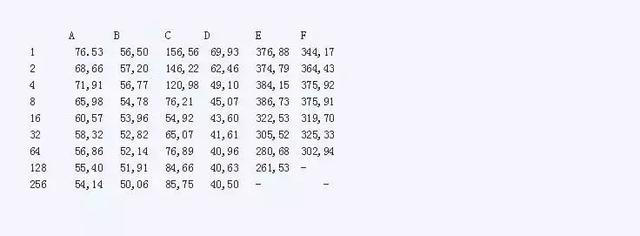
在下面的表格中,列出了平均前向通过的时间。其中,A 是 caffe-openblas, B 是 caffe-openblas-dl, C 代表 tf-vanilla, D 是 tf-neon-vfpv4, E 是 mxnet-openblas, F 是 mxnet-openblas-dl。
表1 不同测试配置在不同的批处理次数下的性能表现
图1 线性尺度下不同配置的前向通过时间比较
在对数尺度尺度上我们再来看一下:
图2 对数尺度下不同配置的前向通过时间比较
测试结果让我大吃一惊。首先,我没有预料到在 CPU 上运行 MXNet的性能会这么差。但这看起来已经是一个众所周知的问题。此外,受限于存储空间,它无法运行 256 张图片的批处理。第二个惊奇是优化过的 TensorFlow 竟有如此好的性能。它甚至比 Caffe 的表现还好(批处理次数超过2时),光从原始框架上看是很难预料这个结果的。需要注意的是,上述测试配置中的优化标志并不是在任意 ARM 芯片上都可以使用的。
Caffe因速度非常快和思路独到而知名。如果你需要连续地处理图片,可以选择使用优化过的OpenBLAS的Caffe,可得到最好的处理性能。如果想提升10ms 的性能,你所要做的就只是简单的输入以下指令:
cd OpenBLASgit checkout optimized_for_deeplearning为了将我的研究转变成正式的东西,我仍需要做大量的工作:评估更多的模型,最终集成 NNPACK,以及研究更多结合了BLAS 后端的框架。
【如果你喜欢EDA365的文章,记得关注和点赞哦!】,